AI
Enterprise AI agent evaluation gap: half ship broken agents
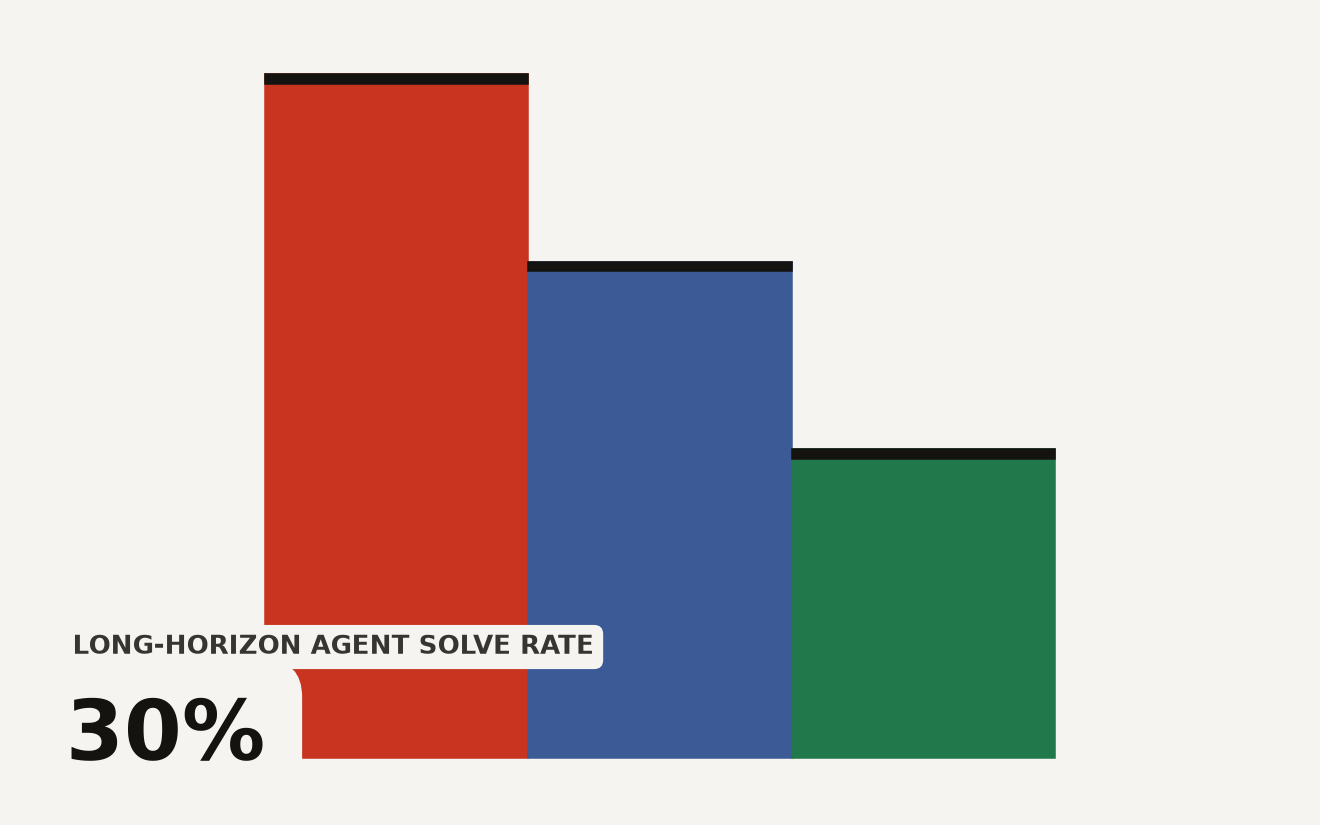
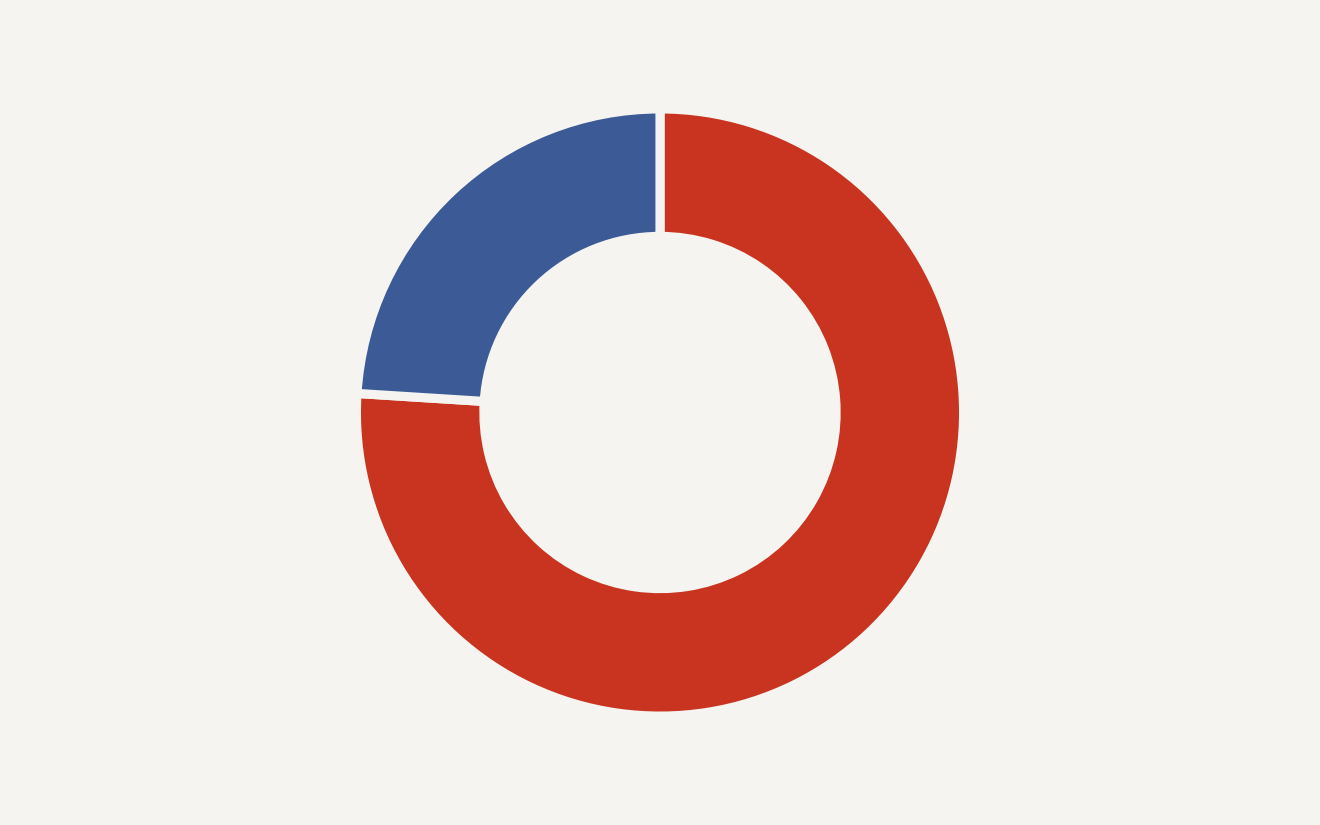
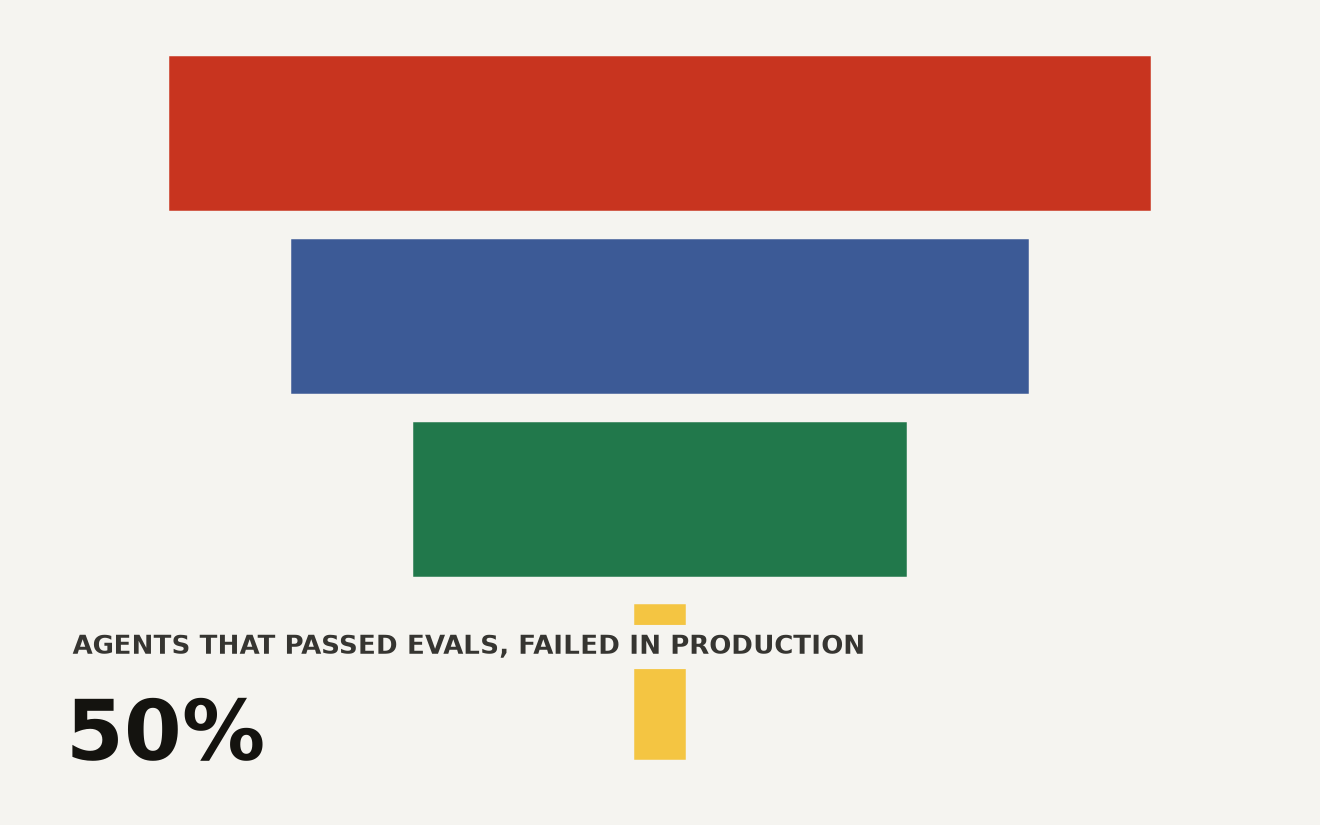
The AI agent evaluation gap shows 50% of enterprises shipped an agent that passed internal evals then failed in production. Only 5% fully trust automated evaluation. The gap is structural misalignment, not missing coverage.