Multi-agent debate is supposed to make LLM systems safer by adding a critic. In data cleaning, a new arXiv preprint finds the opposite often happens: debate degraded generation across four model families by 1.6 to 15.5 percentage points.
That is the useful kind of bad news. It does not kill agentic data cleaning. It tells you where to put the guardrail: give the critic evidence, tools, and a veto, or do not invite it into the pipeline.
The critic made clean rows dirty
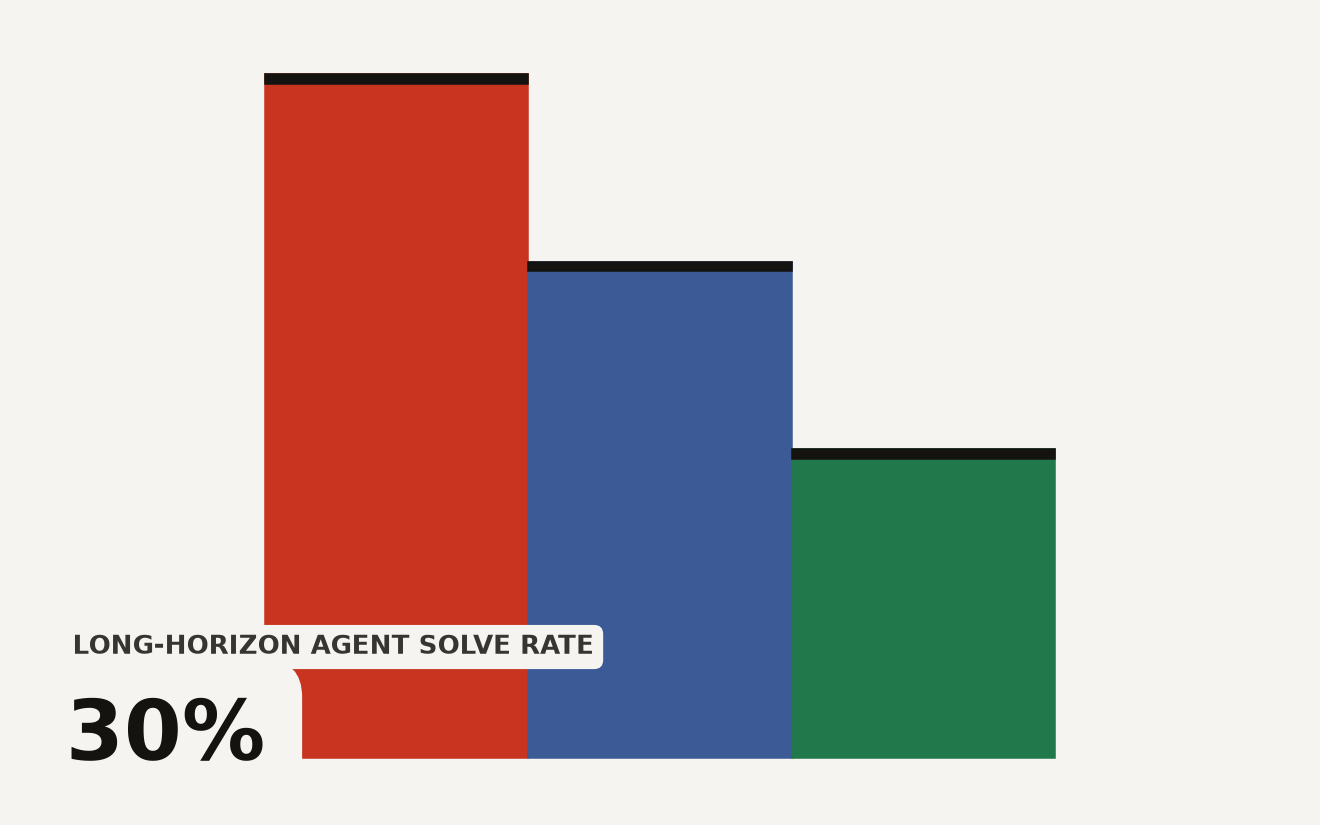
In a paper submitted on June 1, 2026, Chirag Parmar, Akshat Mehta, Henglin Wu, Jagadish Ramamurthy, and Shweta Medhekar tested multi-agent debate for data cleaning across three benchmarks, four model families, and more than 6,000 task-condition pairs. Their headline result is uncomfortable for anyone building a panel of LLM agents and calling it governance: debate hurt generation for every model they tested, with drops ranging from minus 1.6 to minus 15.5 percentage points. The authors call the failure mode "critique-induced confusion," where a critic hallucinates feedback and the generator accepts it too easily.
The chart below is the whole story in four numbers. Naive debate can damage generative repair. Detection is where the pattern flips. The same study reports a 27.4 point F1 gain for error detection, with an effect size of d equals 1.0. Then, after a factorial experiment, the authors found a configuration that finally beat the single-agent baseline on a generative task: a separate critic, code-execution grounding, and evidence-gated generation, up 5.3 points with p less than 0.05.
That split matters because data cleaning is not one task. It is a bundle of tasks that punish different mistakes.
A detection agent can be useful while staying conservative. It asks: "Is this cell suspicious?" A repair agent must write a replacement value. That second action has a blast radius. If the critic invents a reason to change a clean value, the generator can launder the hallucination into your warehouse.
This is the trap in many agent demos. A second model response looks like review. In production, it is only review if the critic has a better signal than the generator. Otherwise you bought a more expensive coin flip with meeting notes.
The result also fits the older data cleaning literature better than the current agent discourse does. HoloClean, introduced by Theodoros Rekatsinas, Xu Chu, Ihab Ilyas, and Christopher Ré in 2017, repaired inconsistent datasets by combining integrity constraints, external signals, and probabilistic inference, reporting about 90 percent precision and more than 76 percent recall across datasets. Raha, a SIGMOD 2019 system from Ziawasch Abedjan and collaborators, beat prior error detection techniques with no more than 20 labeled tuples per dataset.
Those systems were not glamorous. They had the right instinct: data repair needs evidence, not another opinion.
Debate is cheap until it touches your source of truth
The appeal of multi-agent debate is obvious. A 2023 paper from Yilun Du, Shuang Li, Antonio Torralba, Joshua Tenenbaum, and Igor Mordatch described multiple model instances proposing answers, debating reasoning, and converging on a final response, with reported improvements in math, strategy, and factuality tasks. The same mood drove Self-Refine and Reflexion: let a model critique its own work, carry feedback forward, and improve without retraining.
For coding interviews and puzzle benchmarks, that can be enough to justify extra tokens. For data cleaning, the economics are uglier.
Poor data quality already has a measurable business cost. Gartner says bad data costs organizations at least $12.9 million per year on average, and ties data quality directly to AI and machine learning use cases. (gartner.com) That number is broad, but the mechanism is painfully specific: a bad customer record gets merged, a duplicate vendor survives, a SKU mapping shifts, a fraud model trains on the wrong label, or a BI dashboard quietly moves from wrong to authoritative.
Now add multi-agent debate to that path.
If your pipeline uses an LLM to normalize merchant names, resolve entities, infer missing categories, or repair malformed addresses, a naive critic introduces three costs at once:
- Token and latency cost: two or more agents consume more context and wall-clock time before a row lands.
- Operational cost: every disagreement needs a policy, a log, a retry budget, and often a human escalation path.
- Data risk: an accepted false critique can convert a clean value into a dirty one, which is worse than failing to repair.
That last point is the one to tape above the roadmap. In a search or chat product, the model can be wrong and the user may recover. In a data pipeline, the wrong value often becomes training data, a metric, a join key, or a finance input. The error compounds quietly.
This is why the paper’s detection result is more interesting than the failure headline. A critic that flags suspicious cells can raise recall without taking the pen away from your source of truth. It can produce candidates, confidence scores, and evidence. The repair step should have a higher bar.
If you are building this today, the architecture should look less like a debate club and more like a database change-management system:
- Put the critic behind retrieval, profiling, constraints, or code execution.
- Require cited evidence for every proposed repair.
- Separate "flag" from "fix" in the API.
- Log the original value, candidate repair, evidence, model version, prompt version, and confidence.
- Sample accepted repairs for human audit, especially after schema drift or vendor changes.
That sounds boring. Boring is the point.
The paper’s successful configuration used adversarial separation, code-execution grounding, and evidence-gated generation. The important phrase is evidence-gated. The critic should not be a louder generator. It should be a narrower agent with tools that let it prove something about the table.
We have argued before that many agentic AI projects die before they ship because they skip the unromantic parts: evaluation, ownership, and failure budgets. This result belongs in the same folder as /agentic-cancellation-cliff/: the problem is rarely that agents cannot talk. The problem is that talk is not control.
The roadmap move is to split the agent before it argues
The practical lesson is not "never use multi-agent debate." The paper gives a cleaner rule: debate helps when the chance of rescuing a wrong output, weighted by fixability, exceeds the chance of destroying a correct one. The authors say that condition predicted all nine task types in their study and generalized with zero false positives across 19 published comparisons in seven domains.
For a builder, that becomes a product spec.
Start by classifying each data cleaning action by reversibility and evidence quality. Detection is reversible. Suggesting a repair is partly reversible. Auto-writing the repair into a warehouse table is a production change. Treat those as different permission levels, not one agent flow with extra prompts.
A useful version might have four components:
- Profiler: computes distributions, null rates, uniqueness, common formats, and drift.
- Generator: proposes candidate fixes only when asked.
- Critic: checks candidates against code, constraints, dictionaries, and row-level evidence.
- Gatekeeper: applies policy, confidence thresholds, and human review rules.
The critic and generator should not share the same tool view. The paper’s factorial result says adversarial separation mattered. That makes intuitive sense. If both agents see the same prompt and no external evidence, you have duplicated the model’s priors. If the critic can run code against the table, inspect neighboring rows, or test a constraint, it brings a different source of information.
A small implementation detail carries a lot of weight here: make the critic return structured evidence, not prose. For example:
{
"cell": "orders[18422].zip_code",
"claim": "value conflicts with city and state",
"evidence": ["city=Seattle", "state=WA", "zip=02139"],
"proposed_action": "flag_for_review",
"confidence": 0.91
}That schema changes the behavior of the whole system. It gives you test fixtures. It gives analysts something to audit. It lets you reject critiques that contain no evidence. It also makes it easier to compare the agent against old-fashioned baselines such as constraints, dictionaries, and statistical outlier checks.
For the business side, this is where cost discipline enters. Do not spend multi-agent tokens on every row. Spend them on high-value uncertainty: records tied to revenue recognition, fraud, compliance, enterprise customer identity, or training labels for a model that affects money. A 5.3 point repair gain matters if it lands on the right cells. It is waste if you apply it to low-risk formatting issues that a deterministic parser already handles.
For the engineering side, the key metric is not agent win rate in isolation. Track clean-to-dirty conversion rate: how often the system changes a value that was already correct. That is the metric naive debate can worsen, and it is the metric many demos hide.
The next benchmark should charge rent for bad repairs
There are caveats. This is a new arXiv preprint, not a peer-reviewed verdict. The abstract gives the high-level numbers, while production systems will depend on datasets, schemas, tool access, and the cost of human review. A customer-support table, a medical registry, and an ad-click stream do not have the same tolerance for false repairs.
Still, the paper points to a better evaluation standard.
Benchmarks should stop rewarding agents only for final cleaned accuracy. They should charge for every unnecessary modification, every unsupported critique, and every repair that violates lineage. In data cleaning, the model is not just answering a question. It is proposing a database mutation.
The next useful benchmark would report at least five numbers:
- Detection F1.
- Repair precision.
- Repair recall.
- Clean-to-dirty conversion rate.
- Cost per accepted repair, including tokens and human review.
That last number matters more in 2026 than it did when older cleaning systems were designed. Agentic workflows can hide compute in orchestration. A three-agent loop that retries twice can turn a cheap cleaning step into a budget leak. If the only metric is F1, the agent will happily spend your margin.
The smart bet is grounded critics for data cleaning, not open-ended debate transcripts as a control layer.
The distinction is small in a demo and huge in production. The winning critic is less like a brilliant colleague riffing in a meeting and more like a fussy reviewer with a SQL console, a constraint file, and permission to say no.
The data warehouse does not care who won the argument
A debate that fixes errors is useful. A debate that manufactures doubt is a liability with better formatting.
For data cleaning, the safest multi-agent system may be the least theatrical one: one agent proposes, one agent verifies with tools, and the database only moves when the evidence clears the gate.