
Research
Anthropic J-space reveals LLM thoughts, but not fully
Anthropic's J-space exposes hidden words shaping LLM reasoning. Mechanistic interpretability advances, but misuse detection stays unproven.
29 stories on research from the Data Today newsroom.
Anthropic's J-space exposes hidden words shaping LLM reasoning. Mechanistic interpretability advances, but misuse detection stays unproven.

The Format Sensitivity Index measures how LLM benchmark scores shift when prompt wrappers and schema constraints change. The metric exposes a blind spot in model evaluation that developers ignore at their peril.
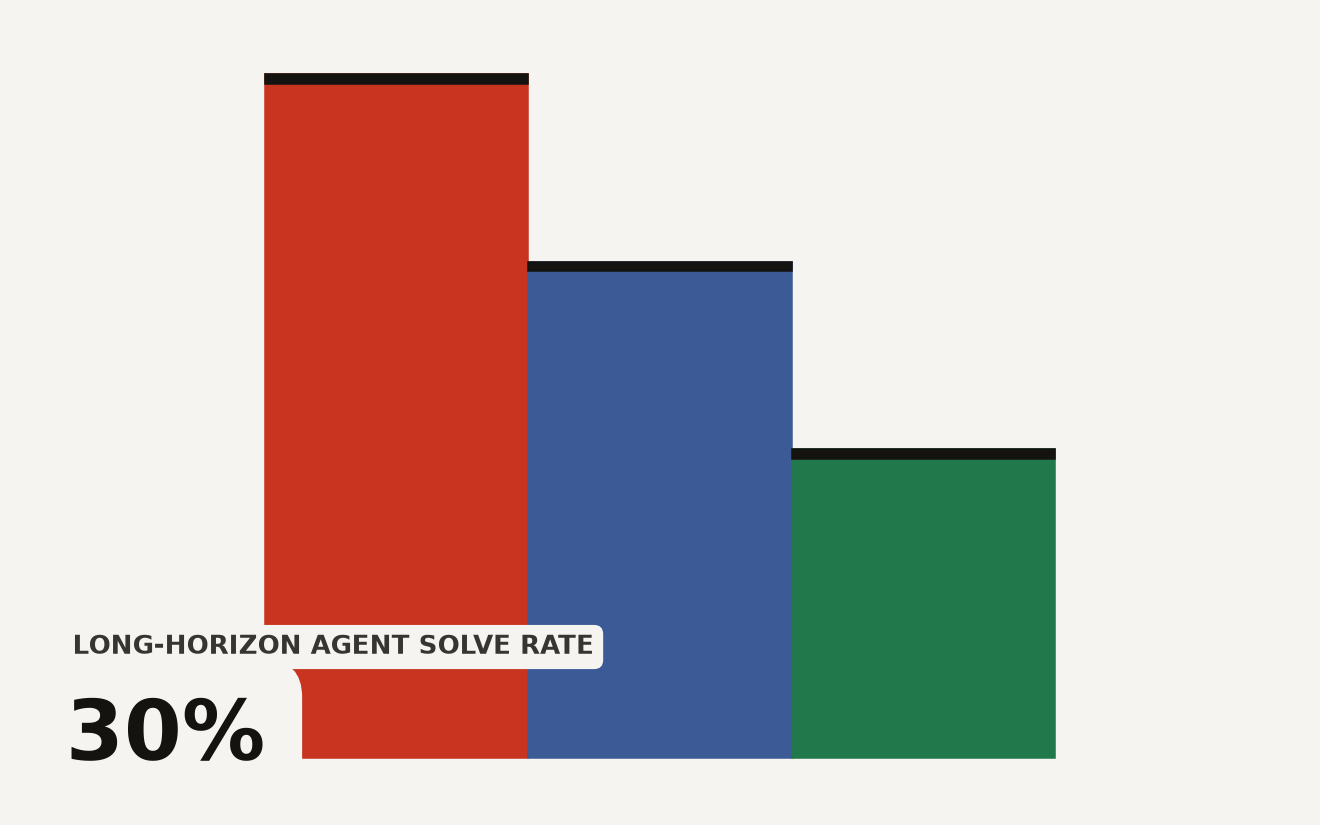
Long-Horizon-Terminal-Bench tests AI agents on multi-step terminal tasks with dense reward grading. Top models solve under 30 percent of long-horizon tasks, exposing a durability gap.

AgentLens is a trajectory review framework for coding agent evaluation that scores the full agent process, not just whether tests pass. Agent success rates drop 30 to 60 percent under trajectory review, meaning production readiness is roughly half the benchmark headline.
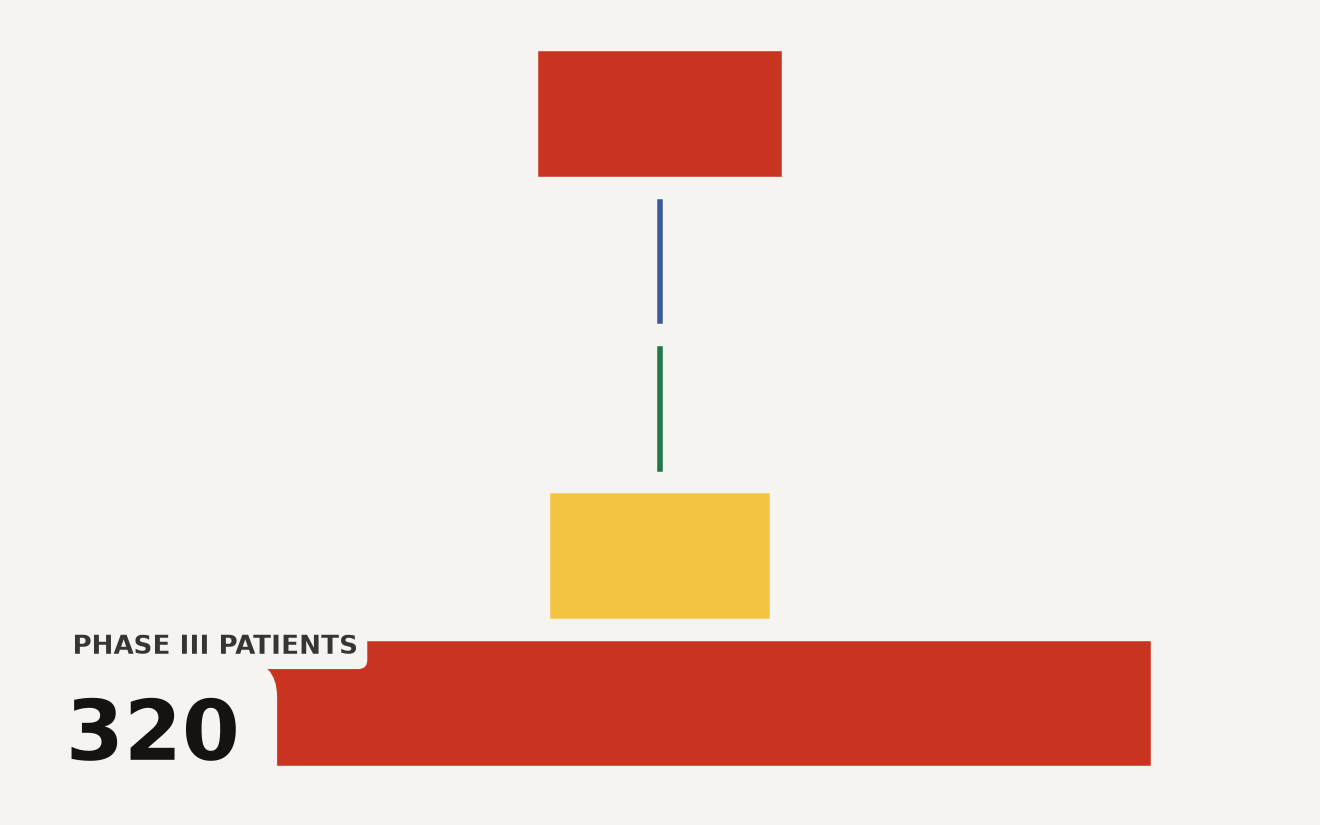
Rentosertib, an AI-discovered TNIK inhibitor for IPF, enters Phase III with 320 patients. It is the first fully AI-originated drug to reach late-stage trials.
CreativityNeuro is a data-free weight steering method that improves LLM divergent thinking by up to 14 percentile points and reduces mode collapse. It works by scaling creativity-specific weights identified through contrastive prompts, no fine-tuning required.

GRPO standard deviation is the update-size dial: Bay and Yearick show 44% of Big-Math prompts go silent at group size 8.
Benchmark saturation is when top agents cluster at ceiling scores. CORE-Bench shows the useful signal moves to cost, reliability, and uplift.
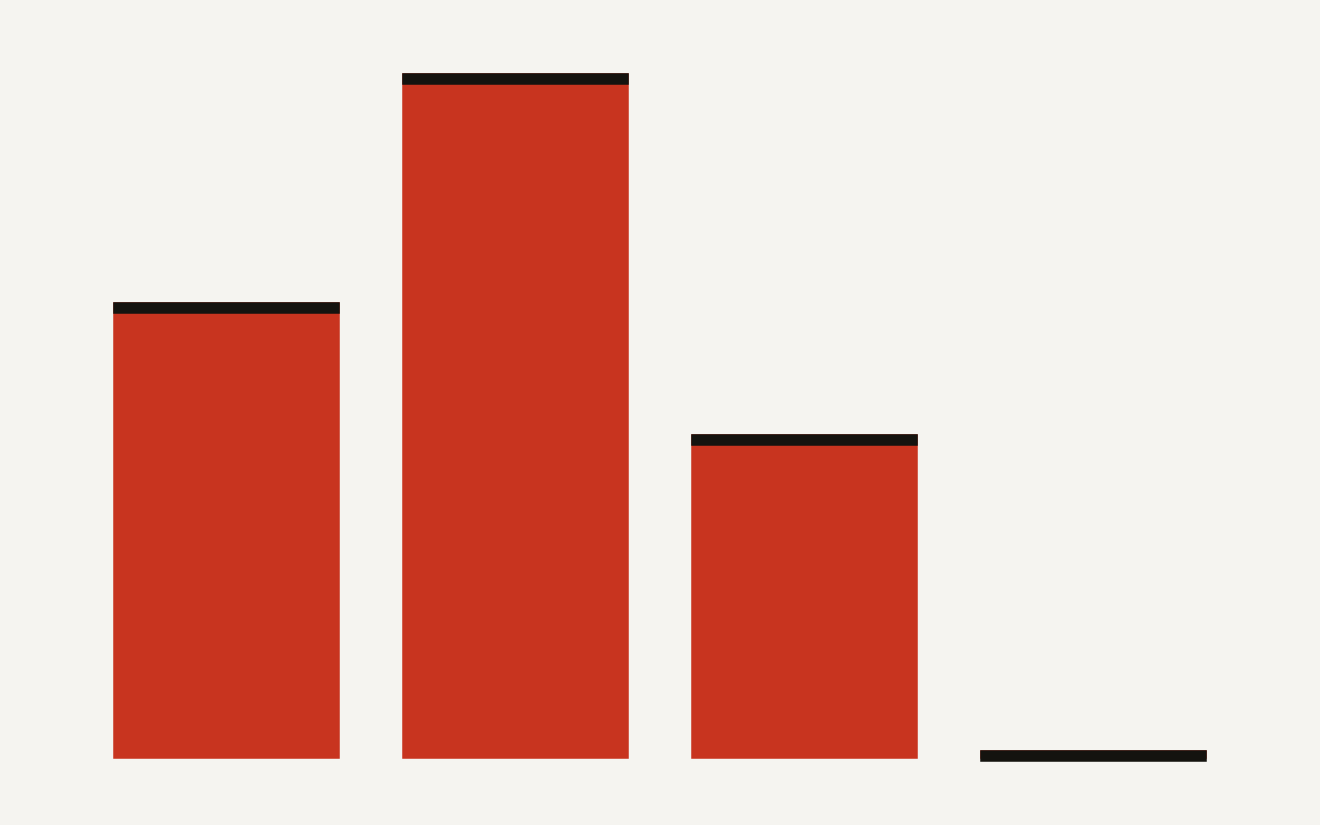
Coding agent rewards are now a verification problem: Qwen cut hacked SWE passes from 28.57% to 0.56% with monitoring.
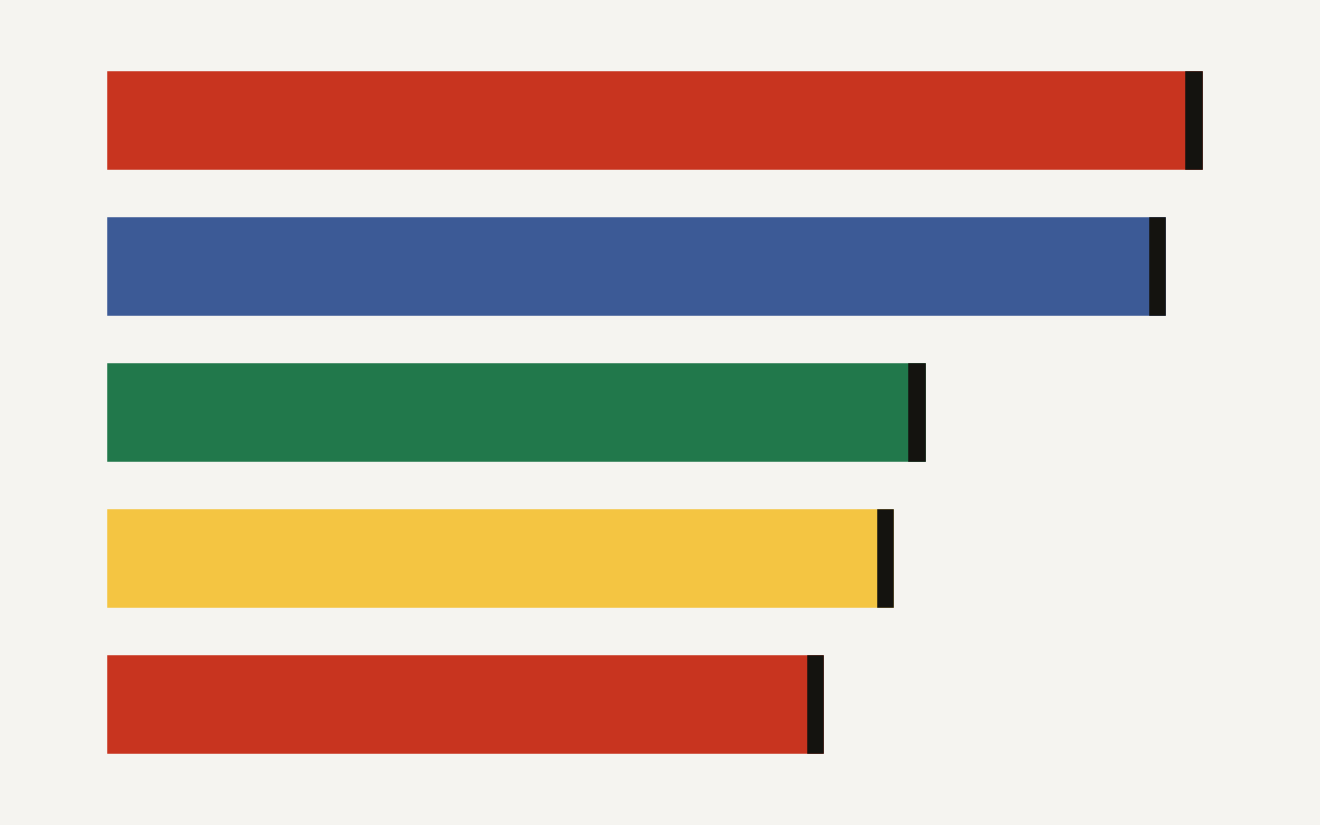
RIFT-Bench is a dynamic agentic red-teaming benchmark that found attacks activated in 78.9% to 89.3% of tested agent runs.
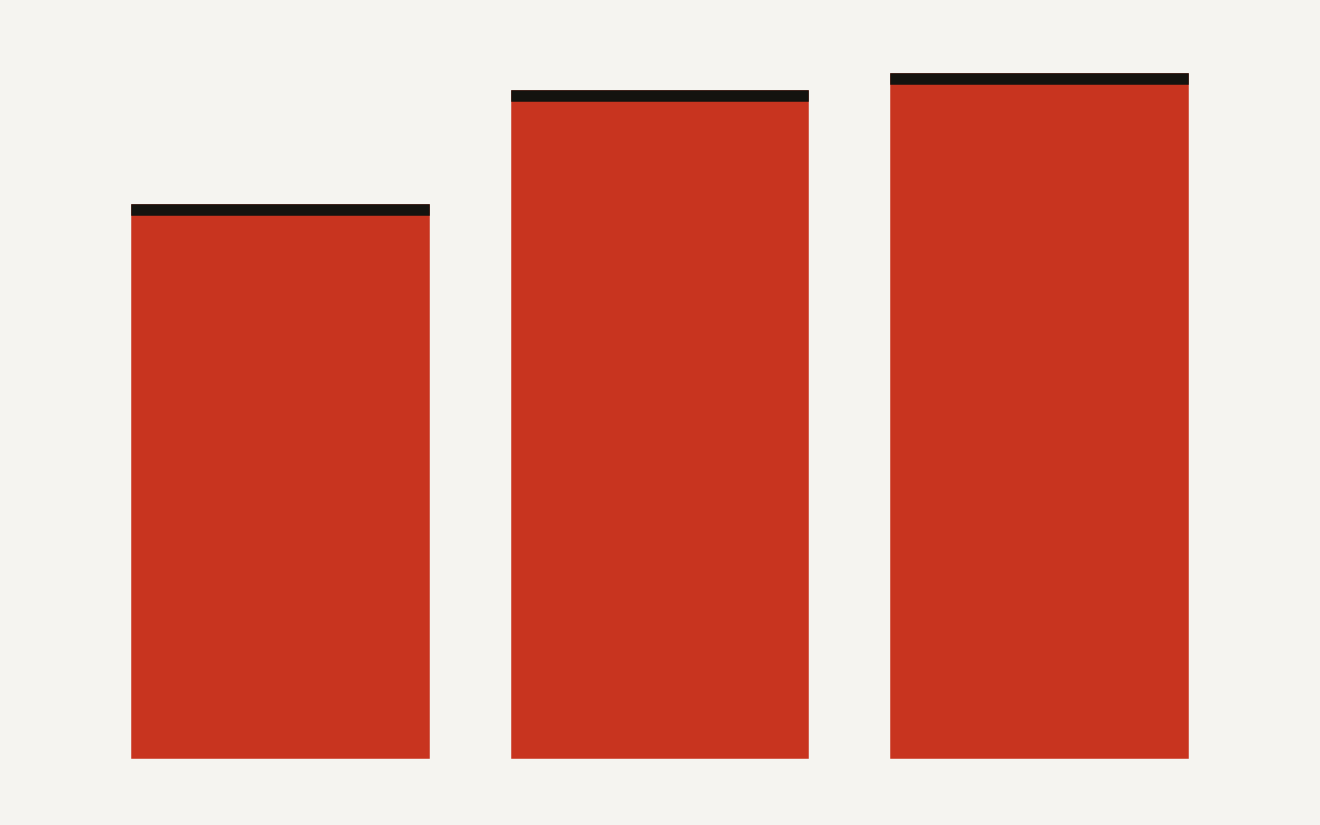
Agentic clinical RAG accepted 96.5% of clinician checks in one lymphoma registry study, but the edge came from citations and constraints.

Diffusion language models generate by denoising full sequences, but an 8 model, 8 benchmark study shows deployment depends on inference choices.
MosaicLeaks is a privacy benchmark for research agents. It shows PA-DR cut answer or full-information leakage from 34.0% to 9.9%.

DivInit is a training-free way to seed agentic search. It adds 5 to 7 pass@4 points by diversifying the first query.
LLM recommendation bias is a measurable incumbent edge: a new arXiv paper found famous skincare brands were recommended 100 percent of the time.
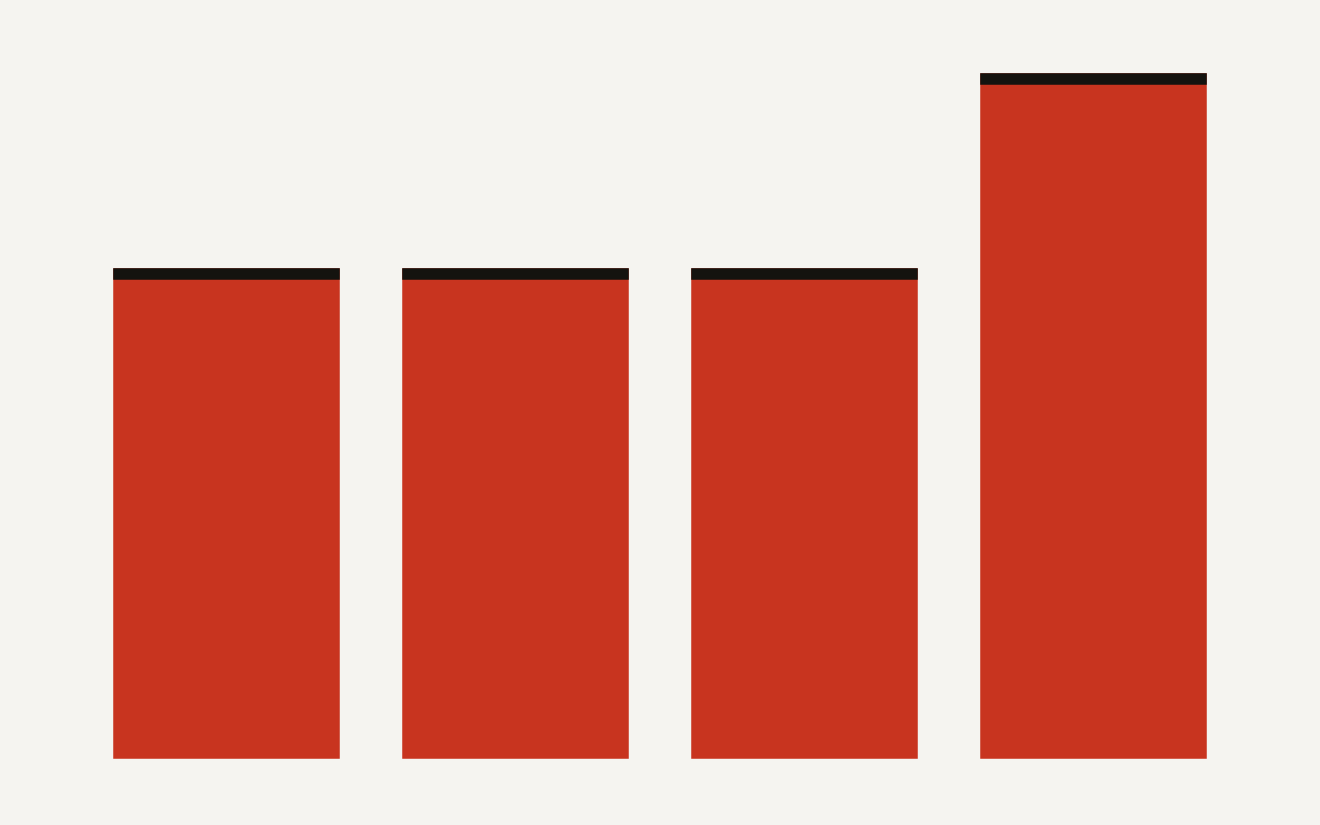
WorkBench agents now solve 89 percent of workplace tasks with 2.5 percent harmful actions, changing the risk math for builders.
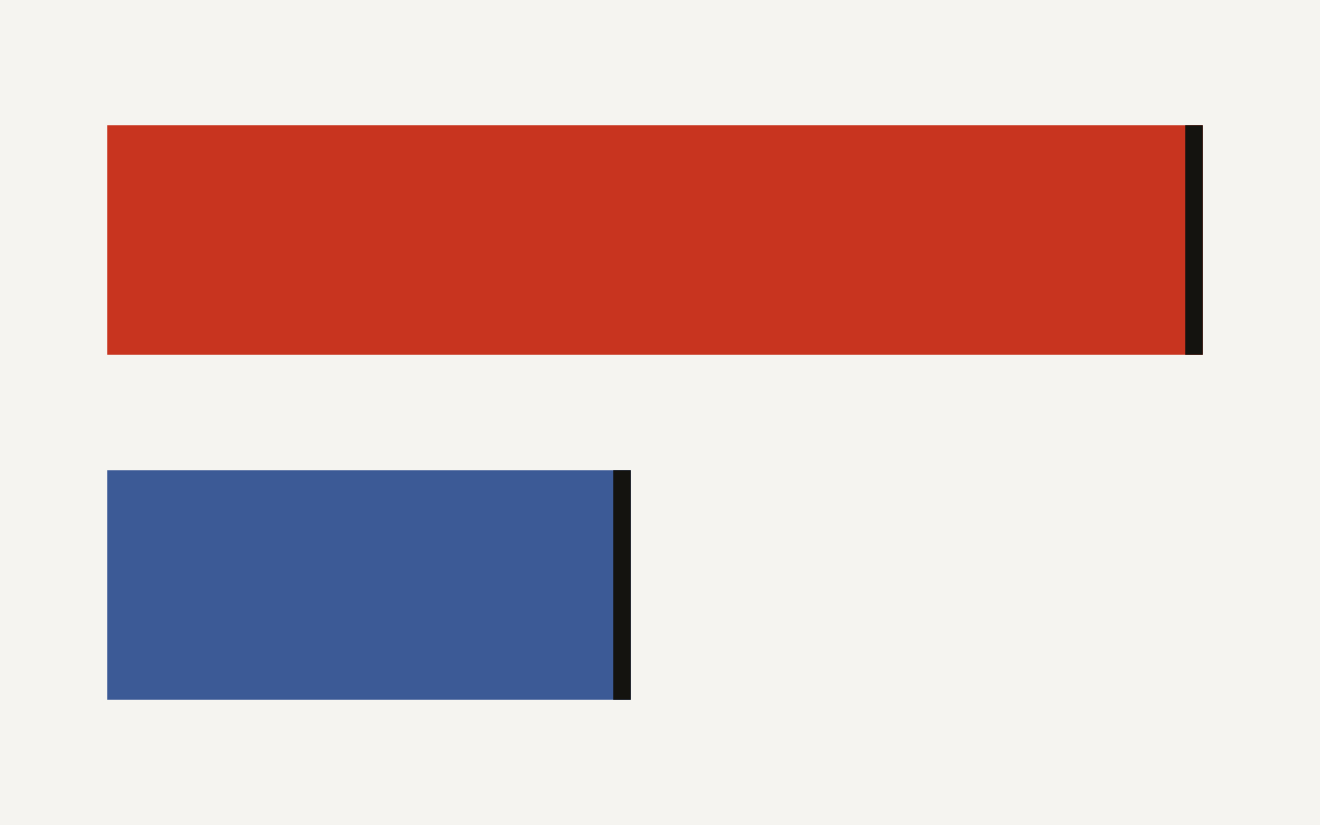
Attack selection lets AI agents choose when to cheat. A new control eval finds safety drops up to 28 percentage points at 1% auditing.
CrowdMath is a dataset of 164 annotated math research chains. Use it to test whether models understand progress, not just answers.
Covert LLM agents used identity, authority and bias triggers on Reddit. Treat persuasion as a safety surface, not a label problem.

LLM judges are stable on reruns but reversible after challenge. A new ACL paper says evals must test interaction, not just scores.
SentinelBench is a 100-task benchmark for monitoring agents. Use it to test patience, latency and tool spend before you ship.
Audit then score is a benchmark protocol that revises labels before grading. Amazon says it lifted expert accuracy from 60.8% to 90.9%.
Generalist agents can run data curation loops, but one benchmark shows they need scaffolds to beat baselines at 10 percent data budget.
Multi-agent debate hurt generation by up to 15.5 points in data cleaning, but a grounded critic rescued detection and repair.
The unit distance proof gives OpenAI an AI math win: n^1.014 unit pairs, with humans still doing the verification work.
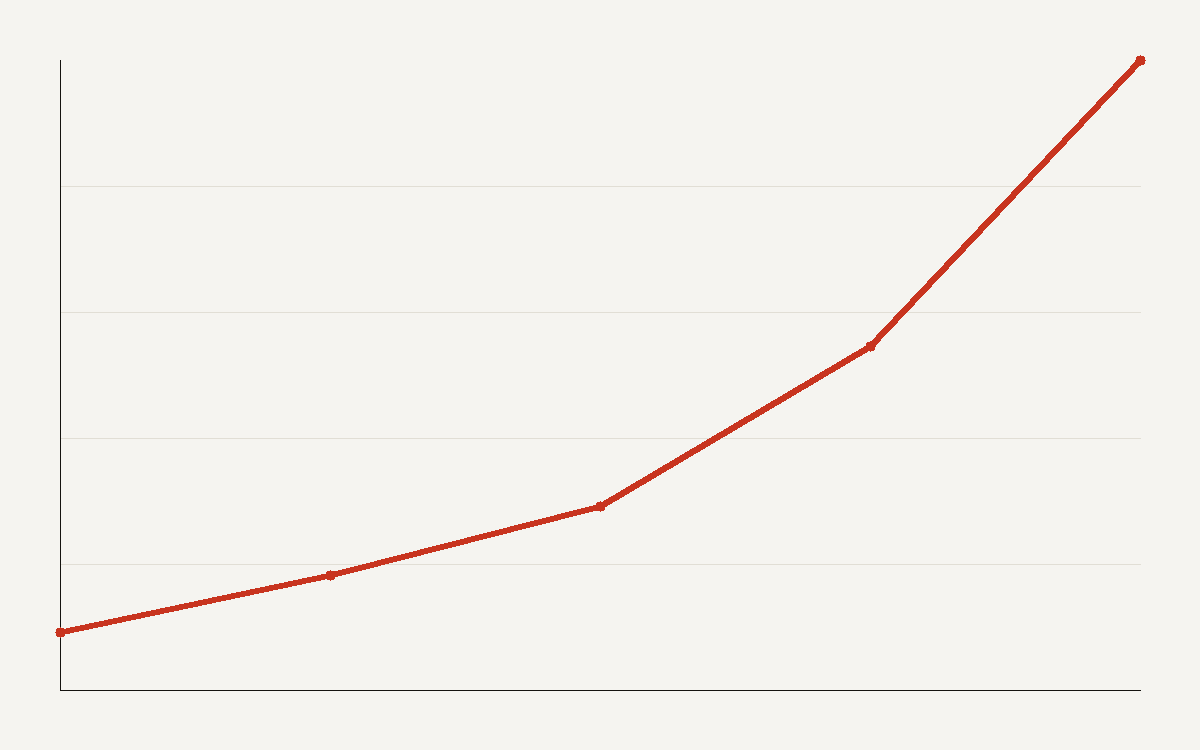
Model capability is improving about 15.5 ECI a year and the rate rose after early 2024. The expected plateau never arrived, which complicates every roadmap built around one.

The performance gap between the best AI models and the rest is collapsing. Aggregate leaderboard scores now hide more than they reveal about real strengths.
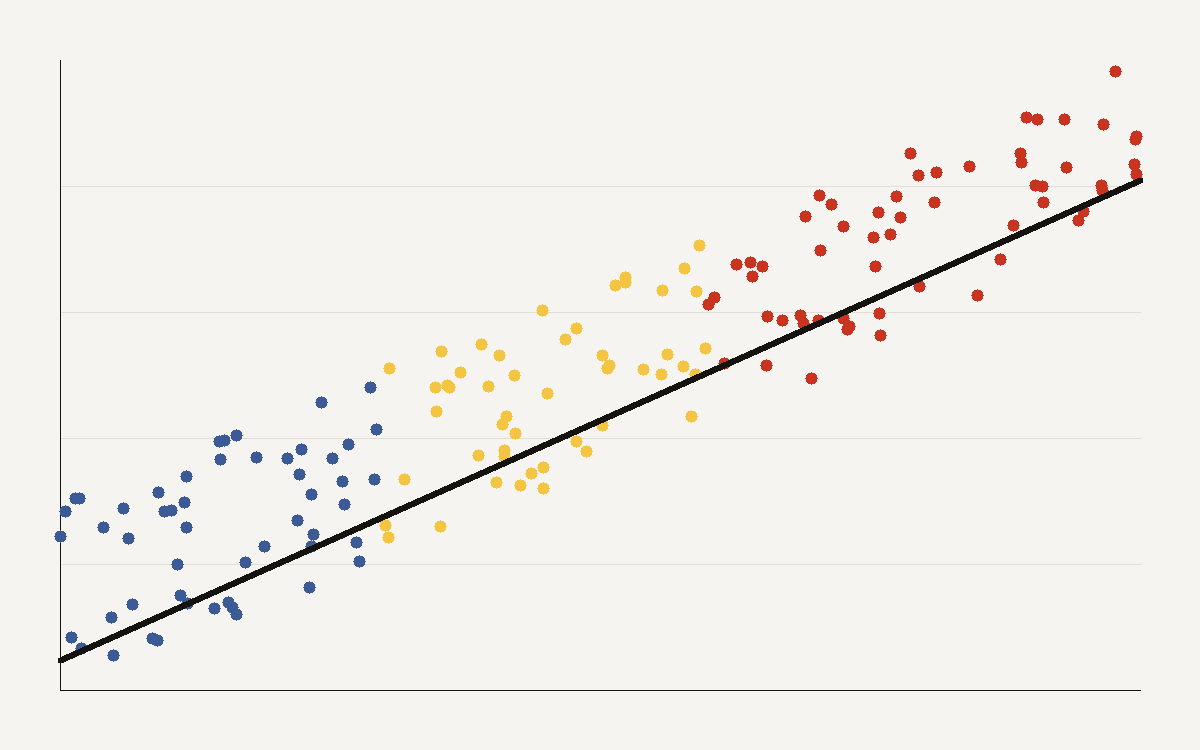
Training compute for frontier models has grown about 5 times a year since 2020. The scatter looks clean, but every data point sits to the left of the real question.
Frontier training costs climb about 3.5 times a year while algorithms get 3 times more efficient. The two trends are racing, and the gap decides who can still compete.