A saturated benchmark looks useless if you only read the leaderboard. The new CORE-Bench paper argues that benchmark saturation still has a job: once agents bunch up near 100 percent accuracy, the benchmark can expose the parts of the system that a single score hides, including cost, reliability, scaffold behavior, and whether a human actually moves faster.
The key number is 2.11: in a small randomized reproducibility study, manual sessions lasted 2.11 times as long as human-agent sessions.
CORE-Bench is a benchmark for computational reproducibility, the grimy work of taking a scientific paper, running its code, fixing dependency messes, and reproducing a reported result. The original CORE-Bench paper described 270 tasks based on 90 scientific papers across computer science, social science, and medicine in 2024, which made it a useful test bed for agent workflows that look more like real work than multiple-choice exams. The original benchmark paper framed this as a way to measure whether agents can help verify published research.
The June 2026 follow-up, written by Nitya Nadgir, Sayash Kapoor, Kangheng Liu, Peter Kirgis, Matilda Orona, Stephan Rabanser, Tilman Bayer, Abhishek Shetty, Yue Ling, Derrick Chan-Sew, Rumi Nakagawa, Saiteja Utpala, Zachary S. Siegel, and Arvind Narayanan, asks a sharper question. If top agents now hit near-ceiling accuracy, should CORE-Bench be retired, or should evaluators squeeze it for the operational signal builders actually need? The new arXiv paper says the authors found six useful dimensions after saturation: validity threats, out-of-distribution generalization, efficiency, reliability, model versus scaffold effects, and human-agent uplift.
That answer matters if you are choosing an agent for a codebase, a research pipeline, or an internal ops workflow. A 97 percent score can still hide a stack that burns twice the tokens, fails silently under a different scaffold, or needs a human at the exact moment your product promised autonomy. The leaderboard may be flat. Your bill and incident queue will have texture.
What did the CORE-Bench team actually change after saturation?
The team did the opposite of the usual leaderboard reflex. Instead of throwing CORE-Bench Hard away, they inspected logs from strong agents, found benchmark defects, and rebuilt the test so it could keep producing signal.
In CORE-Bench Hard, the authors found 15 task-level errors and 20 tasks with exploitable shortcuts after log analysis of agent runs, a class of problem that becomes easier to detect once agents are strong enough to reach weird corners of the benchmark. The paper’s benchmark construction section says these issues included incorrect ground truths, malformed questions, grading errors, unsolvable tasks, and tasks where an agent could read the answer from pre-existing artifacts.
The repaired version, CORE-Bench v1.1, contains 39 tasks: 13 computer science tasks, 10 social science tasks, and 16 medical science tasks. The authors’ table of CORE-Bench variants says v1.1 also added 10 new tasks while preserving the original disciplines, languages, and construction pipeline.
They also built CORE-Bench OOD, an out-of-distribution suite with 19 tasks spanning two economics tasks, 10 engineering tasks, five physics tasks, and two computer science tasks. The OOD section says the goal was to test whether saturation transfers across research fields with different repository structures, software ecosystems, and manuscript conventions.
The headline result is awkward for anyone hoping the repaired benchmark would restore a clean leaderboard. On CORE-Bench v1.1, the top agent reached 100 percent accuracy, and the next four agents tied at 97.4 percent. The results table also shows that on CORE-Bench OOD, two Codex CLI configurations reached 100 percent and the top five Codex CLI agents were statistically indistinguishable.
That sounds like the benchmark is dead. The better read is that the accuracy column has done its job and should stop pretending to be the whole product review.
The chart below shows where the remaining signal appeared once the authors classified 56 failed runs by root cause. Wrong metric or computation errors led with 18 failures, followed by 14 spiraling timeouts, 7 no-answer failures, 6 dependency failures, 5 vision or web fallback failures, 3 environment timeouts, 2 precision or rounding failures, and 1 format mismatch.
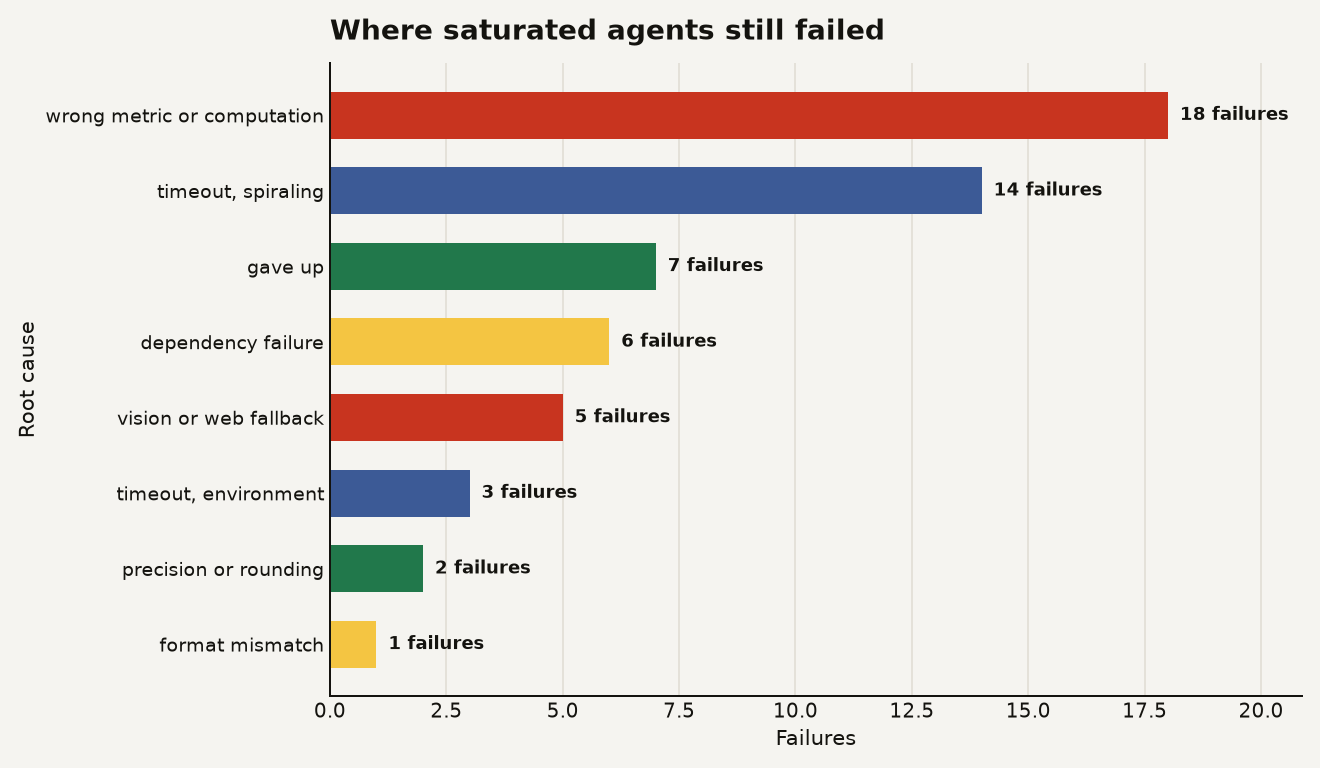
This is the useful shape of post-saturation evaluation. The failures are operational. They look like your production bugs: wrong target metric, dependency hell, timeout loops, fallback behavior, and output formatting.
Why should builders care when the accuracy score is already near 100 percent?
Because agents are no longer sold as answer machines. They are sold as workflow machines. A saturated accuracy metric can tell you that a task is often solvable, but it cannot tell you what the agent will cost, how repeatable it is, or which part of the stack deserves credit.
The CORE-Bench team’s reliability analysis found a mean empirical pass rate of 93 percent across repeated Codex CLI runs, while the agents’ mean reported confidence was only 32.1 percent. The reliability section says the agents were broadly under-confident and did not beat a simple random-guessing baseline for separating correct from incorrect tasks by confidence.
That is a deployment problem, not a philosophical quirk. If an agent says it is unsure after it has actually succeeded, your product may route too many cases to humans. If it says it is sure when the failure mode is hidden, your product may ship bad work. Calibration belongs in the product spec.
The cost story is just as practical. The authors found that GPT-5.3-Codex at medium reasoning matched GPT-5.4 at high reasoning at 97.4 percent accuracy on CORE-Bench v1.1, while costing roughly 60 percent less. The efficiency section says token usage and dollar cost told different stories because provider pricing, caching, and scaffold behavior varied.
If you run agents at scale, that sentence should make you reach for your own eval harness. A model upgrade that adds no accuracy on your workload but doubles spend is a roadmap tax. A scaffold that caches aggressively can beat a bigger model on margin. The model card will not rescue you from that math.
The scaffold results are the part product teams underrate. With Opus 4.5, CORE-Agent and OpenCode both scored 82.1 percent accuracy, yet they disagreed on 12 of 39 capsules, or 31 percent of tasks. The model-scaffold analysis also found that an oracle router choosing the best scaffold per task would reach 100 percent for both Opus 4.5 and GPT-5.4.
That means the wrapper is no longer a neutral wrapper. File search depth, retry policy, environment repair, vision fallback, timeout handling, and tool permissions can decide whether the same model succeeds. This lines up with the broader point we made in our earlier piece on coding-agent verification: agents need reward and verification loops that match the work, not just bigger pass rates on public tasks.
Here is the business consequence in plain terms:
- If you are buying an agent, ask for cost per completed task, not just pass rate.
- If you are building one, log the full trajectory, because failures often live in tool use rather than model reasoning.
- If you are choosing between models, test the same model under multiple scaffolds before you call the model better.
- If you are staffing a team, hire for evaluation and workflow instrumentation, because prompt polish will not expose a 2,700 second timeout pathology by itself.
The paper also puts CORE-Bench inside a wider benchmark fatigue cycle. A February 2026 saturation study analyzed 60 LLM benchmarks and reported that nearly half exhibited saturation. That systematic benchmark-saturation paper found that hiding test data did not provide a protective effect, while expert-curated benchmarks resisted saturation better than crowdsourced ones.
OpenAI made a similar move in coding-agent evaluation earlier this year. On February 23, 2026, OpenAI said it no longer evaluated models on SWE-bench Verified because the benchmark had become saturated and contaminated. OpenAI’s Frontier Evals post said its audit found task issues such as overly specific tests, missing dependencies, and correct fixes that could be rejected.
The CORE-Bench lesson is more constructive than another funeral for old benchmarks. Saturation can be the moment when you stop ranking mascots and start measuring systems.
What should your own agent eval measure after pass rate flattens?
Start by treating accuracy as an entry ticket. If two agents are within the confidence interval on task success, force the comparison onto the axes your business feels.
For a developer tool, that means time to green tests, tokens per accepted patch, revert rate, and whether the agent touched files outside the intended blast radius. For a data or research workflow, it means environment recovery, reproducibility of intermediate artifacts, citation handling, and whether a human can audit the final path in under 10 minutes. For customer operations, it means escalation quality, confidence calibration, and consistency across repeated attempts.
CORE-Bench gives a clean example of why. In the paper’s scaffold comparison, targeted fixes succeeded 95.2 percent of the time across 269 cases, while rewrites from scratch succeeded 67.8 percent of the time across 59 cases. The scaffold section says Codex CLI used direct fixes 82 percent of the time, while CORE-Agent did so 49 percent of the time.
That is a product-design finding disguised as a benchmark finding. If your agent fails, you want it to patch the smallest broken part, rerun the relevant command, and preserve the original program’s intent. A rewrite can look clever in a transcript and still smuggle in a different computation.
The human-agent uplift experiment is the strongest case for keeping the benchmark connected to actual work. The authors ran 50 replication experiments across 20 machine learning and social science papers, with five evaluators each attempting 10 papers under randomized assignment. The study methodology says each paper was attempted by two or three participants, with at least one manual and one human-agent attempt.
The result was a statistically significant speedup. Manual sessions lasted 2.11 times as long as human-agent sessions, with a CR2 standard error of 0.09 and a two-sided p-value of 0.00176. The results section says five of 25 manual runs hit the three-hour time limit, while zero human-agent runs did.
That is the number a founder can use, carefully. It does not prove every research agent doubles productivity across the world. It says that for a narrow, code-heavy reproducibility task with skilled evaluators and a standardized Codex CLI setup, the agent removed a lot of operational drag.
The collaboration logs add texture. In 19 of 25 human-agent runs, evaluators reported that the agent completed the work autonomously aside from two setup steps assigned to humans. The collaboration-pattern table says the remaining runs involved minor suggestions, scope clarification, major redirection, or an agent checking in after wasting time on the wrong path.
The authors also report that evaluators saw agent value in environment setup in 25 of 25 sessions, running code in 23 sessions, identifying main scripts in 20 sessions, and navigating README files in 19 sessions. The same results section says agents fully or partially resolved all but 2 of 114 individual blockers, while humans left 11 of 60 unresolved.
So build your eval around blockers, not vibes. Count how often the agent resolves a missing package, repairs a path, detects the right script, escalates before wasting 30 minutes, and leaves behind a trace a human can trust.
Where is this paper weakest?
The uplift result is promising, but the sample is small. The paper’s limitations section says the randomized study used 20 papers and 5 participants, all of whom were coauthors with master’s-level data science training and reproducibility experience. The limitations section also says the study lacked verified ground truth for the reproduction attempts beyond the paper’s reported results.
That matters. A speedup that produces an unchecked wrong result is just expensive confidence theater. The authors are clear that the uplift study measured process-level gains rather than final correctness against a verified oracle.
There is also a benchmark-maintenance lesson hiding in the footnotes. The authors say their log analysis is not exhaustive because it requires specifying target behaviors, some validity threats appear only in particular runs, and LLM-based classifiers still need manual validation. The OOD discussion says CORE-Bench v1.1 and CORE-Bench OOD should be treated as active benchmarks that update as new threats appear.
That is the right posture. Static benchmarks are convenient for leaderboards. Living benchmarks are better for builders, even if they make marketing slides messier.
The public artifact helps. The authors provide code, data tables, logs, and scripts in a GitHub repository, including runs.csv, efficiency_per_agent.csv, reliability_per_agent.csv, and RCT_responses_cleaned.csv. The CORE-Bench analysis repository says those files back the reliability, efficiency, and uplift figures in the paper.
If you maintain internal evals, copy that habit before you copy the task design. Keep raw trajectories. Keep per-run costs. Keep retries. Keep failed commands. Keep the boring CSV that proves your agent improved for the right reason.
So what survives when the score maxes out?
A saturated benchmark can still be useful if you stop asking it to crown a winner.
CORE-Bench shows that the next layer of agent evaluation looks less like an exam and more like an incident review. Which component failed? How expensive was the success? Did the agent know when it was done? Did the scaffold recover, thrash, or rewrite the world? Did the human move twice as fast, or just watch a confident machine do the wrong thing?
For builders, that is good news with homework attached. The easy chart is the leaderboard. The durable moat is the eval system that tells you why the leaderboard stopped mattering.
Sources
- arXiv: Life After Benchmark Saturation: A Case Study of CORE-Bench
- GitHub: nnadgi01/corebench-analysis
- arXiv: CORE-Bench: Fostering the Credibility of Published Research Through a Computational Reproducibility Agent Benchmark
- arXiv: When AI Benchmarks Plateau: A Systematic Study of Benchmark Saturation
- OpenAI: Why we no longer evaluate SWE-bench Verified