If your eval needs an oracle, you do not have an eval. You have a second product pretending to be a spreadsheet.
Audit then score is Amazon AGI and Duke University’s answer to a failure mode every serious AI team is about to meet: the label is wrong, the model is sometimes right, and the leaderboard cannot tell the difference. In a new DeepFact paper, researchers report that PhD-level specialists hit only 60.8% accuracy on hidden known-answer checks when labeling claims in AI-generated deep research reports, then reached 90.9% accuracy after models challenged the labels and experts audited the disputed evidence through the audit then score protocol in the DeepFact paper on arXiv.
The context matters. Deep research agents now write long reports that synthesize dozens or hundreds of sources, the kind of work OpenAI described in February 2025 as producing comprehensive reports from many online sources for intensive knowledge work in its deep research launch. That output is useful only if the claims are supported. The hard part is that a single sentence can combine three papers, one caveat, and a comparison no source states verbatim. Snippet matching starts to look like checking a bridge with a refrigerator magnet.
Amazon’s own June 3, 2026 write-up frames the shift plainly: ground truth for complex AI has to become a process, and its Amazon Science article says the audit then score protocol improved benchmark accuracy from 60.8% to 90.9%. The underrated part is not the fact-checker. It is the operating model for maintaining truth as model capability changes.
What did Amazon and Duke actually change about the benchmark?
The researchers built DeepFact around deep research reports, or DRRs. These are long, search-augmented syntheses that look like expert memos. DeepFact-Bench, the benchmark artifact, contains 944 claims from 20 reports across six domains, with 323 claims from 5 computer science reports used for validation and 621 claims in the test split, according to the paper’s benchmark description in DeepFact on arXiv.
The old workflow is familiar: hire experts, ask them to label examples, freeze those labels, score models against the freeze. DeepFact starts there, then makes disagreement productive. When a verifier disagrees with the current benchmark label, it must submit evidence and a rationale. An auditor compares the challenger’s case with the incumbent rationale. If the challenger has the stronger case, the benchmark is revised before scoring.
That ordering is the whole idea. Score after audit, not before.
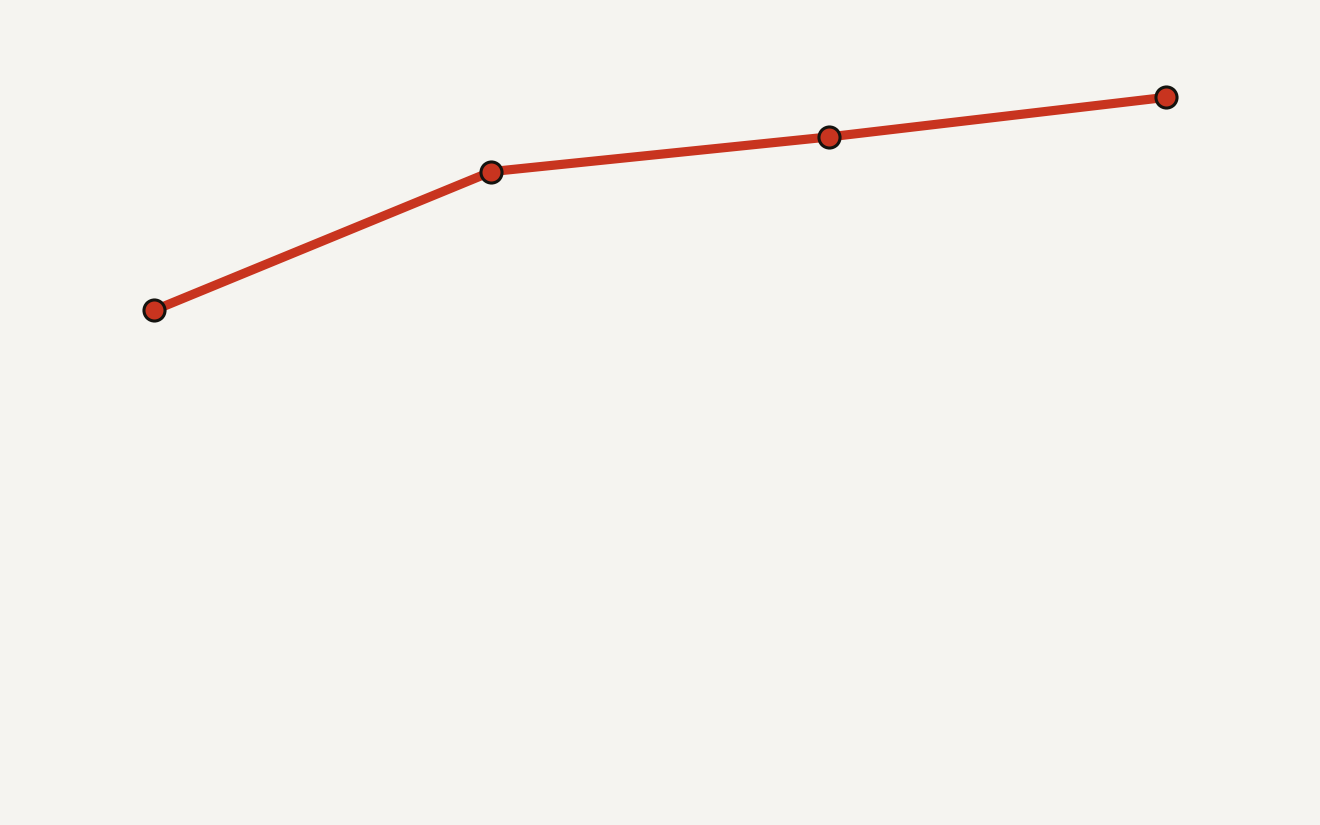
The chart above shows the full-audit path reported in the paper’s ablation: 60.8% in Round 0, 80.4% in Round 1, 85.3% in Round 2, and 90.9% in Round 3. The same section also tested cheaper audit frequencies. By Round 3, auditing 75% of detected conflicts reached 89.5%, only 1.4 points below full auditing at 90.9%, which is a useful clue for teams that cannot afford to adjudicate every dispute.
DeepFact-Eval is the verifier built around this premise. Instead of judging a sentence in isolation, it reads the report context, plans searches, summarizes retrieved documents, asks follow-up questions, and emits a verdict with a rationale. The released repository describes DeepFact-Eval as a document-level, multi-step verification agent and points to DeepFact-Bench as an evolving benchmark in the official DeepFact GitHub repo.
There is a public dataset too, although the dataset viewer currently reports a generation error on Hugging Face. The card still exposes useful metadata: the dataset is tagged for fact-checking, scientific literature, long-form reasoning, and evolving benchmarks, with a MIT license and a listed size bucket of 1K to 10K rows in DeepFactBench on Hugging Face.
Why did experts fail so badly at one-shot labeling?
The 60.8% number is uncomfortable because the annotators were not random crowdworkers. The paper says the team recruited PhD-level specialists from areas such as computer science, education, environmental science, healthcare, public health, control theory, and engineering. The failure came from task shape, not credentials.
A deep research claim can be true only under a qualifier buried in one paper, false because two entities were swapped, or inconclusive because the literature does not support the comparison. The paper’s micro-gold setup included adversarially modified claims with collection-stage errors, analysis-stage errors, and generalization-stage errors. That taxonomy maps painfully well to production RAG bugs: bad source, bad synthesis, bad extrapolation.
One example in the Hugging Face preview shows a subtle denominator switch: a claim turns a statistic about transposon activity into a claim about all mobile genetic elements. That is the kind of error a model can produce with a straight face and a citation. It is also the kind a busy reviewer can miss because every noun looks plausible.
This is where the result becomes more than an eval paper. The same experts became far more useful when they audited a concrete disagreement rather than starting from a blank page. By Round 3, fewer claims required expert work: the paper reports expert-reviewed claims falling from 621 in Round 0 to 361, 247, and 182 across later rounds. Round 0 consumed 65.5% of expert effort, while the three follow-up audit rounds consumed 34.5% and delivered the accuracy jump to 90.9%.
That matters for your team because expert time is the bottleneck in almost every high-value AI workflow. Lawyers, doctors, security engineers, scientists, tax specialists, and senior support agents do not scale like GPUs. If you are still asking them to label from scratch, you are spending scarce expertise on search and triage instead of judgment.
This also connects to a broader pattern in AI data work. As Data Today covered in the hard budget wall for agentic data curation, the expensive part is usually not calling the model. It is deciding which uncertain cases deserve human attention and preserving enough evidence that the next reviewer can move faster.
How strong is DeepFact-Eval compared with ordinary fact-checkers?
On DeepFact-Bench, DeepFact-Eval with GPT-4.1 reached 83.4% accuracy, above the best traditional fact-checking pipeline in the comparison at 58.5% and above GPT-Researcher Deep at 69.1%, according to the paper’s main results table in the DeepFact PDF. That is a large gap, but do not read it as generic magic dust for truth.
The design choice is specific. Traditional systems such as SAFE and VeriScore are closer to claim extraction plus retrieval plus stance judgment. They work best when evidence can be found in a compact retrieved span. Deep research factuality often needs the full report context and evidence distributed across documents. DeepFact-Eval wins by doing more of the work a careful reviewer would do: read context, search broadly, ask narrow follow-ups, and explain the verdict.
The cost side is less flattering. The paper reports DeepFact-Eval with GPT-4.1 using 516.9K input tokens, 18.6K output tokens, and an estimated $1.16 per claim. The grouped version with 10 related claims drops to 93.5K input tokens, 3.5K output tokens, and $0.21 per claim, while still reaching 76.3% accuracy. That grouped mode beats GPT-Researcher Deep’s 69.1% at a similar budget.
So the practical read is not to run maximal verification on every sentence. Use tiers:
- Cheap screening for low-risk, high-volume content where occasional misses are tolerable.
- Grouped verification for related claims in long reports, especially where shared context cuts duplicate retrieval.
- Full audit then score loops for claims that affect customer decisions, regulatory exposure, medical guidance, security posture, or revenue.
If your product roadmap includes agent-generated memos, procurement research, market intelligence, diligence packs, science summaries, or customer-facing explanations, the eval plan needs a dispute lane. A static gold set will decay as models improve and as the external literature changes. Worse, it can punish the very behavior you want: surfacing better evidence than the original labeler found.
What should builders change in their eval stack now?
Start by treating ground truth as versioned infrastructure. Every labeled claim should have a label, a rationale, the evidence consulted, the model or human that proposed it, the auditor, the timestamp, and the benchmark version that used it. If that sounds like a lot, compare it with debugging a production incident where nobody knows why a gold label became gold.
The minimum viable version is simple:
- Store rationales beside labels, not in a separate doc nobody opens.
- Route model and human disagreements into a queue with evidence attached.
- Track accepted label revisions as benchmark versions.
- Report scores against a named version, not the benchmark in the abstract.
- Sample hidden micro-golds to measure whether your reviewers are improving or drifting.
The DeepFact paper’s statistical appendix also gives a useful caution for small evals: it treats the report as the independent unit because claims inside the same report are correlated, then runs 20,000 paired bootstrap replicates for significance testing. That is the grown-up version of eval hygiene. If your 500 test cases came from 12 user journeys, pretending you have 500 independent observations will make your confidence intervals lie politely.
For business leaders, the staffing implication is sharper. Do not hire scarce experts to be labeling machines. Build tooling that turns them into auditors. The work product should be a stronger benchmark, not just a pass or fail note on this week’s model.
For developers, the product implication is equally concrete. Your eval harness needs an API for challenges. A model run should be able to say: I disagree with case 143, here are the sources, here is the rationale, here is why the incumbent label is under-supported. That challenge should be reviewable, reversible, and attributable.
The moat is not owning a frozen dataset. The moat is the loop that keeps correcting it.
Where does audit then score still break?
There are limits. DeepFact verifies claims against existing literature. The authors state that current verifiers function as expert literature reviewers rather than active laboratory scientists, so they cannot run new experiments or simulations when the literature is silent or conflicted. That matters in science, but it also matters in business. If a claim depends on your private warehouse data, customer contracts, or live system telemetry, public web retrieval will not settle it.
The protocol can also amplify the challenger if the auditor is weak, rushed, or biased toward polished rationales. Better evidence and better prose are not the same thing. A good implementation should require source provenance, uncertainty labels, and counterevidence search, especially for high-stakes domains.
Cost remains the other constraint. At $1.16 per claim for the full GPT-4.1 setup, verifying a 200-claim report can become a line item. The grouped variant helps, and the paper’s audit-frequency ablation suggests you can get close to full auditing by sampling conflicts. Still, the system asks you to pay for truth maintenance. That is annoying. It is also cheaper than shipping confident nonsense into a workflow where one bad claim changes a decision.
The next useful benchmark paper will not just report higher accuracy. It will show how often revised labels later get reverted, how adversarial the challenge process can become, how well agent auditors behave without human backup, and how much private-domain evidence changes the results. Static leaderboards made sense when the test set was the hard part. For agentic research systems, the maintenance process is the hard part.
The benchmark is the product
The lesson from DeepFact is blunt: if a model can find evidence your benchmark missed, your evaluation system needs to listen before it grades. The winning teams will not be the ones with the prettiest gold set on day 1. They will be the ones whose truth machinery is still getting better on day 90, when the model, the literature, and the business have all moved.