The easiest way to misunderstand diffusion language models is to treat them like a faster tokenizer. The interesting part is stranger: they generate text by starting with noise or masks, then refining whole spans in parallel. That gives builders a new set of knobs, and a new set of ways to fool themselves.
A new arXiv paper, Diffusion Language Models: An Experimental Analysis, puts that trade-off under a cleaner microscope: 8 state of the art diffusion language models across 8 benchmarks covering reasoning, coding, translation, knowledge, and structured problem solving. The authors, Thomas Bertolani, Davide Bucciarelli, Leonardo Zini, Marcella Cornia, and Lorenzo Baraldi, submitted the paper on June 17, 2026, and frame the work around a practical problem every AI team now recognizes: benchmark scores can move when the inference recipe changes.
That matters because diffusion language models are leaving the demo lane. Google says Gemini Diffusion samples at 1,479 tokens per second excluding overhead, while ByteDance Seed reports Seed Diffusion Preview at 2,146 tokens per second on H20 GPUs. Inception Labs says Mercury Coder Mini and Small reached 1,109 and 737 tokens per second on H100 GPUs in independent Artificial Analysis evaluations. Those numbers are not apples to apples. They are a warning label for your roadmap.
What did the diffusion language model study actually test?
The Bertolani paper is valuable because it treats diffusion decoding as a system, rather than a single model card number. The abstract says the team evaluated 8 modern DLMs across 8 benchmarks, then varied inference time factors including denoising steps, context length, block size, and parallel unmasking strategies.
That sounds procedural. It is the whole ballgame.
Autoregressive models usually give you a familiar contract: a prompt goes in, the model emits token 1, then token 2, then token 3. You can still tune sampling, caching, batching, and reasoning budgets, but the generation order is baked into the architecture. Diffusion language models expose more of the generation process to the deployer. You choose how many denoising steps to spend. You decide how aggressively to unmask tokens. You may generate in blocks. You may trade quality for latency in a way that feels closer to image generation settings than standard chat completion parameters.
Google’s public Gemini Diffusion page makes that shift explicit, saying the model generates entire blocks of tokens at once and supports iterative refinement. Dream 7B’s authors describe the same family of ideas in more research language: Dream 7B uses discrete diffusion modeling to refine sequences in parallel and supports arbitrary order generation, infilling, and tunable quality speed trade-offs.
The chart below shows why the field has momentum, while also showing why clean evaluation is hard. The reported speed spread runs from 737 to 2,146 tokens per second, but those claims come from different models, hardware, tasks, and measurement rules.
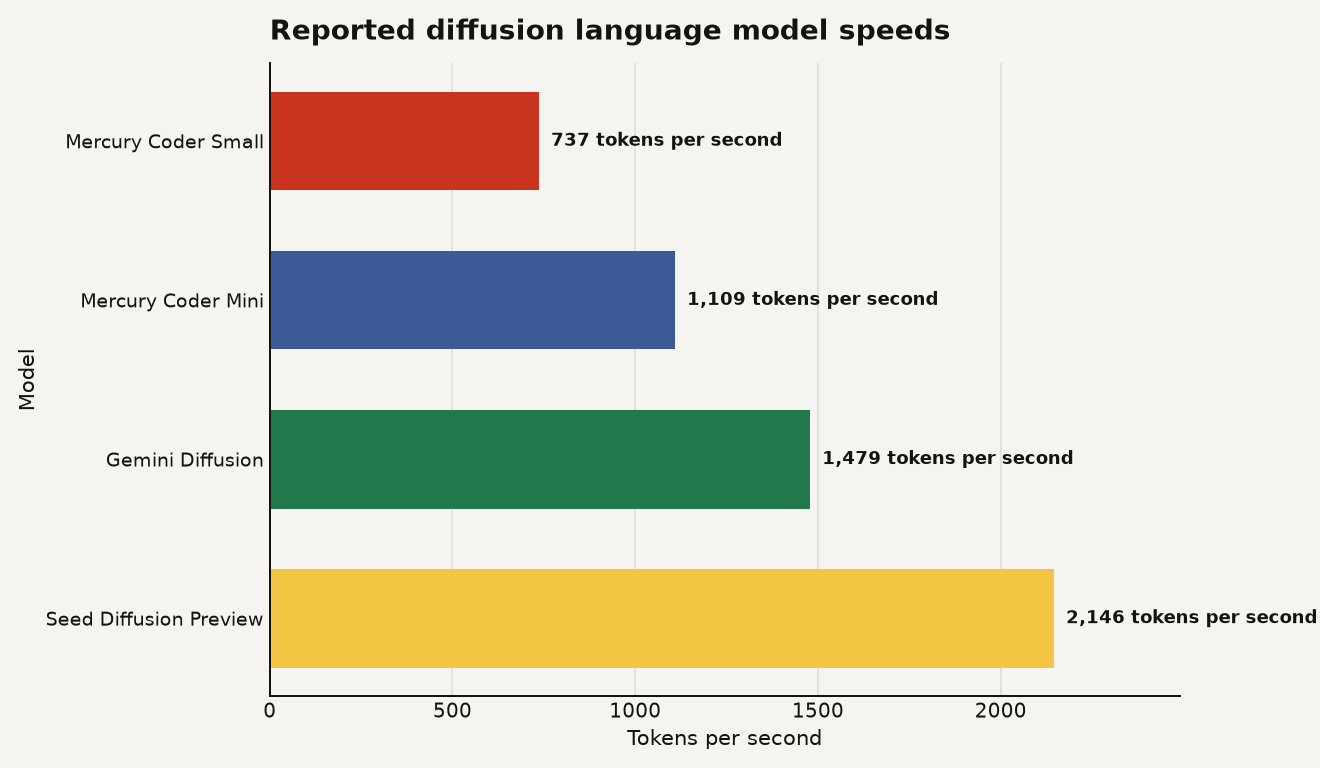
The right reading is boring in the best possible way: diffusion language models have credible latency upside, and the exact upside depends on the full inference stack. Seed Diffusion’s own paper cautions that direct comparisons are hard because Mercury used H100s, Gemini used unknown hardware, and Seed measured over H20 GPUs. That caveat is more useful than another victory lap.
Why do inference settings matter so much here?
Diffusion language models buy speed by breaking the one token at a time habit. The bill arrives as inference policy.
In the new paper, the authors call out denoising steps, context length, block size, and parallel unmasking as factors that shape both quality and compute. Those are not cosmetic parameters. They decide how much of the sequence the model tries to settle at once, how many refinement passes it gets, and how expensive each pass becomes.
Seed Diffusion’s paper states the engineering issue cleanly: a single parallel inference step can be expensive, so many tokens must be generated at once to amortize that overhead. This is the piece that many product demos hide. If your workload is short answers, small edits, or tool calls with tight latency budgets, parallel decoding may shine only after the framework, batching, and prompt shape line up. If your workload emits long code patches, translations, or structured documents, the same architecture may look far more attractive.
That is why the Google and Mercury numbers are exciting but incomplete. Google reports 0.84 seconds of overhead for Gemini Diffusion in addition to 1,479 tokens per second sampling speed. Inception Labs reports 737 and 1,109 tokens per second for Mercury Coder Small and Mini, but those are coding focused models measured under a separate evaluation setup. ByteDance reports 2,146 tokens per second for Seed Diffusion Preview over H20 GPUs and emphasizes code benchmarks.
For builders, the practical consequence is simple: benchmark the inference policy, not only the checkpoint.
That means logging at least four things beside the score:
- Denoising steps, because fewer steps can cut latency while changing accuracy.
- Output length, because parallel generation pays off differently at 40 tokens and 4,000 tokens.
- Block size or unmasking schedule, because aggressive parallelism can change coherence.
- Hardware and overhead, because tokens per second excluding overhead can flatter interactive products.
This is where Data Today’s earlier argument for statistical discipline in model eval loops fits. If your eval harness treats a diffusion model like a drop in autoregressive endpoint, it will miss the very variables that make the architecture useful.
What changes for your codebase and product roadmap?
The best near term use case is not general chat. It is any place where generation is long enough, structured enough, and latency sensitive enough that parallel refinement changes the user experience.
Code is the obvious candidate. Inception Labs built Mercury Coder for programming tasks and says the family was designed for coding applications. Google’s Gemini Diffusion benchmark table is also heavy on code, reporting 89.6 percent on HumanEval, 76.0 percent on MBPP, and 30.9 percent on LiveCodeBench v6. ByteDance’s Seed Diffusion paper evaluates across code related tasks and reports Seed Diffusion Preview at 54.3 pass at 1 on CanItEdit in its table.
Here is what this means for you if you ship AI features:
- Autocomplete gets a new latency ceiling. A model that can refine blocks may feel better for whole function completions than token streaming, especially if the UI can display a coherent chunk instead of dribbling text.
- Patch generation becomes more interesting. Diffusion models can naturally support infilling, and Dream 7B’s paper says diffusion models can fill missing text segments without specialized training.
- Cost models get messier. Fewer wall clock seconds do not automatically mean lower GPU cost if each denoising step is heavy or overhead dominates short outputs.
- Evaluation needs workload buckets. A single average score will hide whether the model helps long edits, translation, coding fixes, or short answers.
The hiring implication is also real. If diffusion language models become part of production stacks, the scarce skill will not be prompt writing. It will be inference engineering: kernels, batching, scheduling, cache behavior, and benchmark design. The model may be open. The latency moat will sit in everything around it.
There is a business consequence too. Fast generation changes what you can afford to ask a model to do. A coding agent that can regenerate several candidate patches quickly can use search where a slower model uses a single shot. A data cleaning tool can propose multiple schema repairs. A support agent can draft, critique, and revise before the user sees anything. The user still judges the final answer. Your margin depends on how many hidden passes you bought to get there.
What should teams test before betting on diffusion language models?
Start with your own latency distribution. Average tokens per second will mislead you if your product is gated by time to first useful output, request overhead, or tool round trips.
A solid internal test should include at least 100 prompts per workload bucket, even for an early bake-off. Split them by output length and structure: short answers under 100 tokens, medium answers from 100 to 800, long code or document generation above 800, and infilling tasks where the model must respect both left and right context. Run each diffusion model with several denoising step budgets, then plot quality against wall clock time and GPU seconds.
Do not hide failures inside a single win rate. Diffusion models can fail differently. A left to right model often paints itself into a corner late. A diffusion model can produce global inconsistency after seeming to refine the whole answer. That is a different bug class for code review, translation QA, and structured output validation.
Also test the boring integration layer. LLaDA’s official repository says the team open sourced LLaDA 8B Base and Instruct on February 14, 2025, but also says it does not provide the full training framework and data. That may be fine for inference experiments. It is a warning if your roadmap assumes full reproducibility, custom pretraining, or regulated deployment.
The bets worth making now are narrow:
- Use diffusion models in sandboxes for code completion, bulk rewriting, translation, and infill heavy workflows.
- Build eval harnesses that treat denoising steps and block policies as first class variables.
- Track total request latency, not only sampling speed.
- Keep autoregressive baselines in every test until diffusion wins on your actual workload.
The bet to avoid is architectural cosplay. Swapping in a diffusion model because the token per second number looks huge is how teams buy complexity without a product win.
The model is only half the benchmark
Diffusion language models are the healthiest kind of AI news: weird enough to matter, early enough to punish lazy conclusions.
The new 8 model, 8 benchmark study does not crown a permanent winner. It gives builders a better question. When a model can revise a whole sequence in parallel, your product is no longer benchmarking only intelligence. It is benchmarking the policy that spends computation.
That is a good trade if you measure it honestly. It is an expensive magic trick if you do not.
Sources
- arXiv: Diffusion Language Models: An Experimental Analysis
- Google DeepMind: Gemini Diffusion
- Google Blog: Gemini Diffusion, Google DeepMind’s experimental research model
- arXiv: Mercury: Ultra-Fast Language Models Based on Diffusion
- arXiv: Seed Diffusion: A Large-Scale Diffusion Language Model with High-Speed Inference
- arXiv: Dream 7B: Diffusion Large Language Models
- GitHub: ML-GSAI LLaDA official repository