Ask anyone who has shipped a creative-writing feature with an LLM the same question twice and you will get the same answer twice. The phenomenon has a name now: the artificial hivemind effect, where models converge on a narrow band of responses to open-ended prompts. For builders running brainstorming tools, ideation pipelines, or content generation at scale, this mode collapse is a quiet tax on product quality. Your model has a vocabulary of 50,000 tokens and it uses the same 50 for everything.
A new paper from researchers at the University of Illinois, Harvard, and Stony Brook University introduces CreativityNeuro, a data-free method that steers language model weights to improve divergent thinking. The approach improves performance on the Divergent Association Task by up to 14 human percentile points and reduces mode collapse across three creativity assessments, all without retraining, gradient-based fine-tuning, or behavioral datasets. In a human evaluation with 720 participants, the method produced statistically significant gains in originality and surprise on open-ended tasks where simpler activation steering techniques failed to transfer.
This matters if you are building anything that depends on output variety. The method is cheap, inference-only, and works on open-weight models you already run. But it comes with a catch that the paper is honest about: pushing creativity scores costs you factual accuracy, and the two appear to be tangled in weight space in ways that are not easy to separate.
What does CreativityNeuro actually do to the model?
The method builds on prior work called MathNeuro, which identified and amplified weights associated with mathematical reasoning. CreativityNeuro extends that idea to a domain where no structured dataset exists. The researchers could not pull creativity questions from a benchmark the way you pull math problems from MATH or GSM8K, because creativity is a property of responses, not of inputs.
Their solution is contrastive prompting. They construct pairs of short instructions that steer a model toward creative versus non-creative behavior: "Surprise me" versus "Be precise," or "Think of an unusual idea" versus "Give the standard answer." They run these prompt pairs through the model and compute parameter importance scores using a Wanda-style metric that multiplies weight magnitude by activation norm. Then they take the set difference: weights that rank high for creative prompts but NOT for non-creative prompts. Those are the creativity-specific parameters. At inference time, they multiply those weights by a scaling factor of (1 plus alpha), amplifying the creative direction without touching the rest of the network.
The whole pipeline requires no behavioral data, no scored responses, and no gradient updates. You pick two prompt sets, compute importance scores, identify the sparse subset of weights that lights up for creative prompts but not for routine ones, and scale them. The hyperparameters are rho, the percentage of weights selected, and alpha, the scaling strength. The authors tested six contrastive prompt sets spanning styles from storytelling to minimal two-word instructions, and the method produced gains across all of them.
How much does it improve creative output?
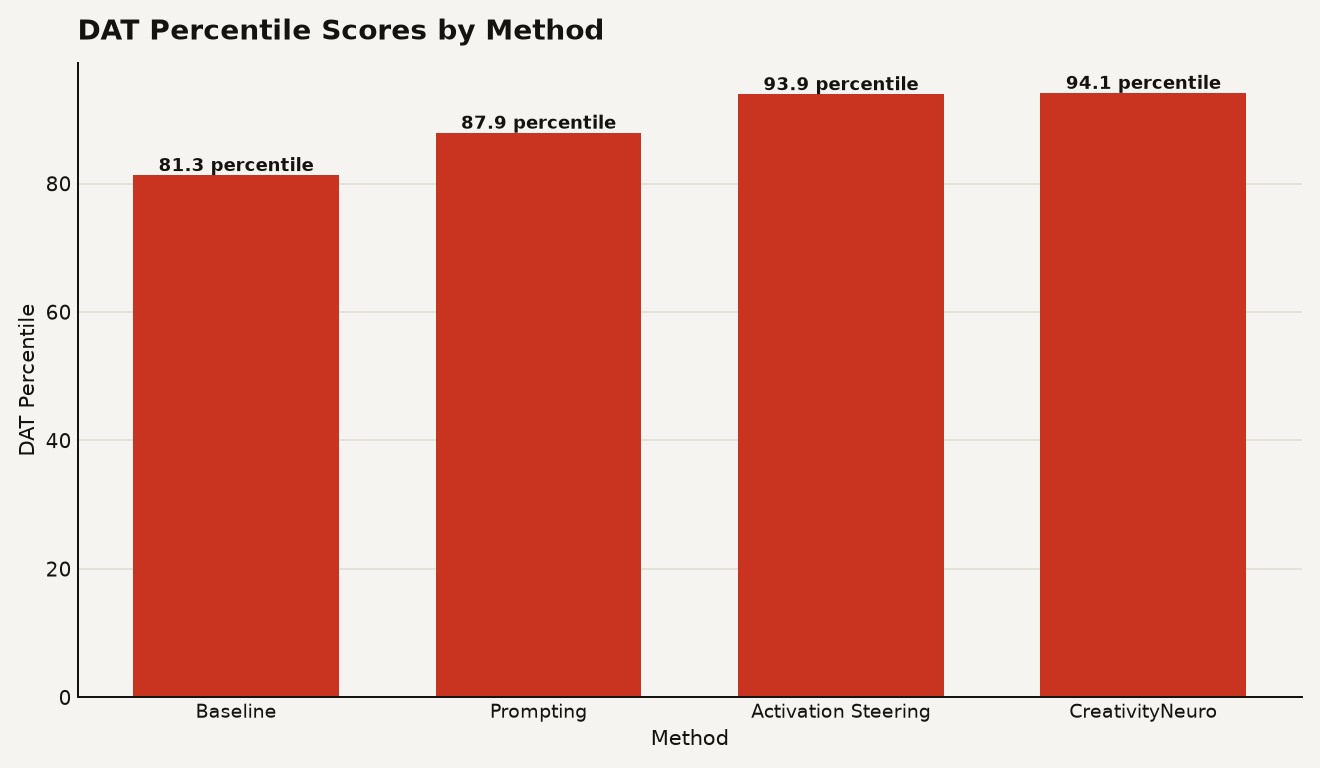
The headline number is a 14 percentile point improvement on the Divergent Association Task, a vocabulary-space creativity test that measures how semantically distant a model's word choices are from the most common responses. Baseline models averaged 81.3 on the DAT percentile scale. CreativityNeuro pushed that to 94.1 across six open-weight models. Activation steering, a simpler technique that modifies hidden states at inference time, reached 93.9 on the same test, making the two methods nearly identical on word-level creativity.
The gap opens on harder tasks. The researchers ran a large-scale human evaluation with 720 participants judging outputs on the Alternative Uses Test (think of unusual uses for a brick) and the Task Task (an open-ended creative generation prompt). On the AUT, CreativityNeuro achieved positive originality effects across all six models with an average Cohen's d of 0.36, and surprise effects averaging d equals 0.43 with five models reaching statistical significance. On the Task Task, originality gains were even stronger at d equals 0.40, with Phi-14B showing the largest effect at d equals 0.61.
Activation steering, which matched CreativityNeuro on the DAT, failed to generalize to these longer-form tasks. The paper notes that activation steering requires scored behavioral data to construct its steering vectors, and when the researchers tried a prompt-only version without that data, it averaged only 87.8, essentially the same as plain prompting at 87.9. Weight-space steering generalizes further out of distribution because it modifies the model's parameters directly rather than injecting a bias at the activation level.
On mode collapse specifically, CreativityNeuro reduced the top-10 word concentration by 10.2 percentage points on the DAT and increased vocabulary entropy by 0.59 nats, a 10 percent increase. On the Task Task, it reduced intra-model repetition by 5.5 percent and inter-model homogeneity by 6.3 percent. If you have ever looked at a batch of LLM outputs and seen the same metaphors and sentence structures repeating, those are the metrics that measure the problem you were seeing.
Why does this matter for builders shipping creative features?
If you run a product that depends on LLM output variety, mode collapse is already costing you. It shows up as duplicate content in recommendation pipelines, repetitive brainstorming suggestions, and the uncanny sense that every model response sounds like it came from the same person. The conventional fixes are expensive: temperature tuning (unreliable), top-p sampling (shallow), multiple model calls with different system prompts (costly), or fine-tuning on creative datasets (slow and narrow).
CreativityNeuro offers a different lever. Here is what it means for your stack:
- No retraining or data collection. You apply weight scaling at load time. The method works on models you already host. If you are running Llama or Qwen or Phi variants locally, the paper tested six models in the 3B to 14B range and the technique worked across all of them.
- Inference-only cost. There is no training step and no additional forward pass overhead at inference. The weight modification is applied once to the model checkpoint and the model runs normally after that. The compute cost is the initial importance scoring run, which is a single pass through the contrastive prompt pairs.
- Generalization beats activation steering. If you have tried activation steering for creativity and found it works on short outputs but falls apart on longer ones, this paper confirms that observation with data. Weight-space steering transfers to paragraph-length generation; activation steering does not.
- You will lose some factual accuracy. The default masks reduced MMLU scores by 3.13 percentage points on average. The researchers tried adding MMLU prompts to the negative contrast set to protect factual reasoning, which shrank the masks by roughly half but still degraded MMLU by another 0.71 points. This is a real tradeoff, not a free lunch.
The last point is the one to sit with. The paper provides evidence that divergent thinking and factual reasoning are non-separable in weight space. The weights that make a model more creative overlap with the weights that keep it grounded. You cannot simply carve out a creativity module and leave everything else untouched. This means CreativityNeuro is best suited for applications where creative variety matters more than factual precision: ideation tools, content generation, brainstorming assistants, and creative writing features. It is poorly suited for search, retrieval, or any pipeline where hallucination risk is already a concern.
For a deeper look at the mode collapse problem this method attacks, the LLM groupthink novelty benchmark covers how researchers have been measuring the hivemind effect across model families.
What are the limits and what should I watch for?
The paper is thorough about its own boundaries, which is worth respecting. Several constraints matter for anyone planning to implement this.
The method requires open-weight models. You need access to the parameter tensors to compute importance scores and apply scaling. If you are building on a closed API like OpenAI or Anthropic, this technique is not available to you. The six models tested were all open-weight: Llama, Qwen, Phi, and similar families in the 3B to 14B parameter range. The method has not been tested on frontier-scale models.
The novelty-utility tradeoff is real. The paper acknowledges that CreativityNeuro degrades AUT utility scores, meaning the creative outputs are more original but sometimes less useful. This is the same tradeoff that exists in baseline responses: more surprising answers tend to be less practical. If your product needs both originality and groundedness, you will need to manage this tension, perhaps by running two model variants (a steered one for ideation and an unsteered one for refinement).
The prompt set design matters but is not brittle. The researchers tested six different contrastive prompt sets and found that while the DAT-specific set produced the most consistent gains, all six yielded statistically significant improvements. This suggests the method is identifying genuine creativity-related weights rather than memorizing task-specific patterns. Still, you will want to experiment with your own prompt pairs for your domain.
There is an open question about scale. The largest model tested was 14B parameters. Whether the same sparse weight identification works on 70B or 400B models, and whether the creativity-accuracy tradeoff shifts at scale, remains unanswered. The importance scoring method comes from model compression literature (Wanda), and compression techniques sometimes behave differently at very large scale.
Watch for follow-up work on disentangling creativity from factual reasoning. The paper's finding that the two are non-separable in weight space is one of its most interesting contributions, and it raises a question that several research groups are likely to chase: can you find a subspace that amplifies divergent thinking without touching factual weights at all? The current evidence says no, but the search space is large.
The weight space does not care about your feature categories
The deepest finding in this paper is not the percentile gain or the human evaluation scores. It is the evidence that creativity and factual reasoning share the same neural real estate. Builders like to think of model capabilities as modular: you can add reasoning here, creativity there, safety somewhere else. Weight space does not respect those boundaries. The parameters that make a model produce surprising word choices are entangled with the parameters that keep it from hallucinating. Any steering technique that pushes on one will tug on the other.
This is why the method is a tool, not a solution. It gives you a dial for divergent thinking that costs you some factual grounding every time you turn it. For ideation features where variety is the product, that is a trade worth making. For everything else, the hivemind problem is still yours to solve.
Sources
- arXiv CreativityNeuro: Steering Language Model Weights to Improve Divergent Thinking and Reduce Mode Collapse
- schapiro.ai CreativityNeuro full PDF
- arXiv Steering Language Models with Weight Arithmetic
- arXiv Where does output diversity collapse in post-training?