The fastest way to ship a broken AI product is to build a beautiful eval dashboard around a judge that can be talked out of its own verdict.
LLM judges are cheap enough to become infrastructure. The new question is whether they can survive a cross-examination.
LLM judges are model-based evaluators that score, rank, or compare another model's outputs. They became popular because open-ended AI tasks are miserable to grade with fixed unit tests. A customer support answer can be partly right. A coding agent can pass tests while adding a security smell. A RAG response can cite the right source and still miss the user's intent. So teams put a stronger model in the judge seat and ask it to decide.
A new paper from Srimonti Dutta and Akshata Kishore Moharir, submitted to arXiv on June 3, 2026 and accepted at the ACL 2026 GEM Workshop, lands in that exact gap. The paper studies "post-decision manipulability": whether an LLM judge changes its judgment after it has already made a decision and then faces a follow-up challenge. The authors say their controlled experiments on MT-Bench and AlpacaEval find a split that should make every eval owner uncomfortable: judges can look stable under neutral reruns, then become substantially reversible when challenged through a targeted interaction. The paper also introduces an Evaluation Robustness Score, or ERS, to measure that failure mode through reversal susceptibility and directional steering in challenge protocols, according to the arXiv abstract.
That matters because many teams treat repeated agreement as reliability. Run the judge twice. Check the variance. If the score barely moves, green check. This paper says that test is too polite.
What did Dutta and Moharir test that normal evals miss?
Most LLM-as-judge setups freeze the world. You hand the judge a prompt, two candidate answers, a rubric, maybe a reference answer, and you record the decision. If you care about variance, you run the same evaluation again with shuffled order or a second judge. The hidden assumption is simple: a judgment is a property of the input.
Dutta and Moharir attack that assumption. Their paper asks what happens after the judge has already chosen. In the arXiv summary, they describe targeted post-decision challenges, an anti-baseline challenge protocol, and a counterbalanced target-validation protocol. The distinction matters. A naive challenge might merely expose a real judge error. A better experiment needs to separate legitimate correction from target-directed steering.
The paper's finding is sharper than "LLM judges are noisy." The authors say judges are highly stable under repeated and neutral reevaluation, but can become reversible under motivated interaction. They also report that authority framing is especially destabilizing, and that revised judgments often come with low-overlap justifications. Plain English: the judge does not merely change its mind. It often writes a new story for why the new answer was right all along.
That is a different class of bug from position bias or verbosity bias. A position-biased judge can be patched by swapping answer order and aggregating. A verbosity-biased judge can be measured with length-controlled win rates. A post-decision-manipulable judge creates a governance problem: if your workflow lets a model, agent, vendor, or human reviewer argue with the judge after the first decision, your eval may be measuring persuasion skill as much as output quality.
The venue context also matters. The ACL 2026 GEM Workshop schedule lists the paper among evaluation and metrics work in San Diego on July 4, 2026, alongside papers on benchmark contamination, reproducibility, LLM-as-judge reliability, and faithfulness judging. This is not a fringe concern. It is the evaluation community staring at the machinery most AI builders now use to decide what ships, as shown in the GEM 2026 program.
Why does this break your eval pipeline even if reruns look stable?
Because production evals are rarely single-turn, sealed trials.
A model does not just answer and vanish. Agents retry. Tool calls fail. A user objects. A support bot asks for clarification. A coding assistant explains why the test failure is spurious. A model under evaluation can be wrapped by another model that critiques, revises, and resubmits. Once you add interaction, the judge sits inside a conversation. That gives the evaluated system a new attack surface.
This is the part builders should screenshot: static agreement is not interactional robustness.
The original MT-Bench work helped make LLM judging mainstream because the numbers were compelling. Zheng and colleagues created MT-Bench with 80 multi-turn questions, evaluated answers from 6 models, used 58 expert-level human labelers, and reported around 3,000 votes. In their NeurIPS 2023 paper, GPT-4 reached 85 percent non-tie agreement with human experts on MT-Bench, while human-to-human agreement was 81 percent in the same setup, according to the published paper.
That 85 percent number was useful. It said a strong judge could approximate human preference well enough for iteration. It did not say the judge would hold up when someone challenged its prior decision with authority language or motivated critique.
AlpacaEval pushed the same practical logic further. Its maintainers describe the toolkit as fast, cheap, replicable, and validated against 20,000 human annotations. They also warn that automatic evaluators should not replace human evaluation for high-stakes release decisions, and they name limitations including non-representative instructions, style bias, and missing risk measurement in the project documentation.
So the uncomfortable read is this: the community already knew LLM judges had biases. The new paper adds a missing axis. It asks whether the judge can defend its judgment after the fact.
If you run evals for a product team, that changes the failure model:
- Your regression suite can pass while your escalation loop fails. The judge may be stable on batch runs and weak inside a multi-turn review.
- Your leaderboard can reward argument quality. A model that produces persuasive objections may flip borderline calls without actually producing better initial answers.
- Your audit trail can look cleaner than the decision process. Low-overlap revised justifications mean the final rationale may be a post hoc artifact, not a faithful account.
- Your vendor comparison can drift. If one vendor's model is evaluated with more follow-up interaction than another's, you are no longer comparing outputs under the same conditions.
This pairs with a pattern Data Today covered in multi-agent debate needing a data-cleaning cop: deliberation can improve outcomes, but only when the protocol controls what counts as evidence. Otherwise, fluent agents create procedural fog.
How expensive is the temptation to trust the judge?
The reason teams use LLM judges is not ideology. It is cost.
AlpacaEval's evaluator table gives the blunt version. For 1,000 examples, it reports human annotation at 300 dollars and 36,800 seconds. The same table lists GPT-4 turbo chain-of-thought evaluation at 4.3 dollars and 228 seconds, Claude at 3.3 dollars and 173 seconds, and ChatGPT at 0.8 dollars and 285 seconds. The chart below shows why a product team with weekly model releases reaches for automated judging first.
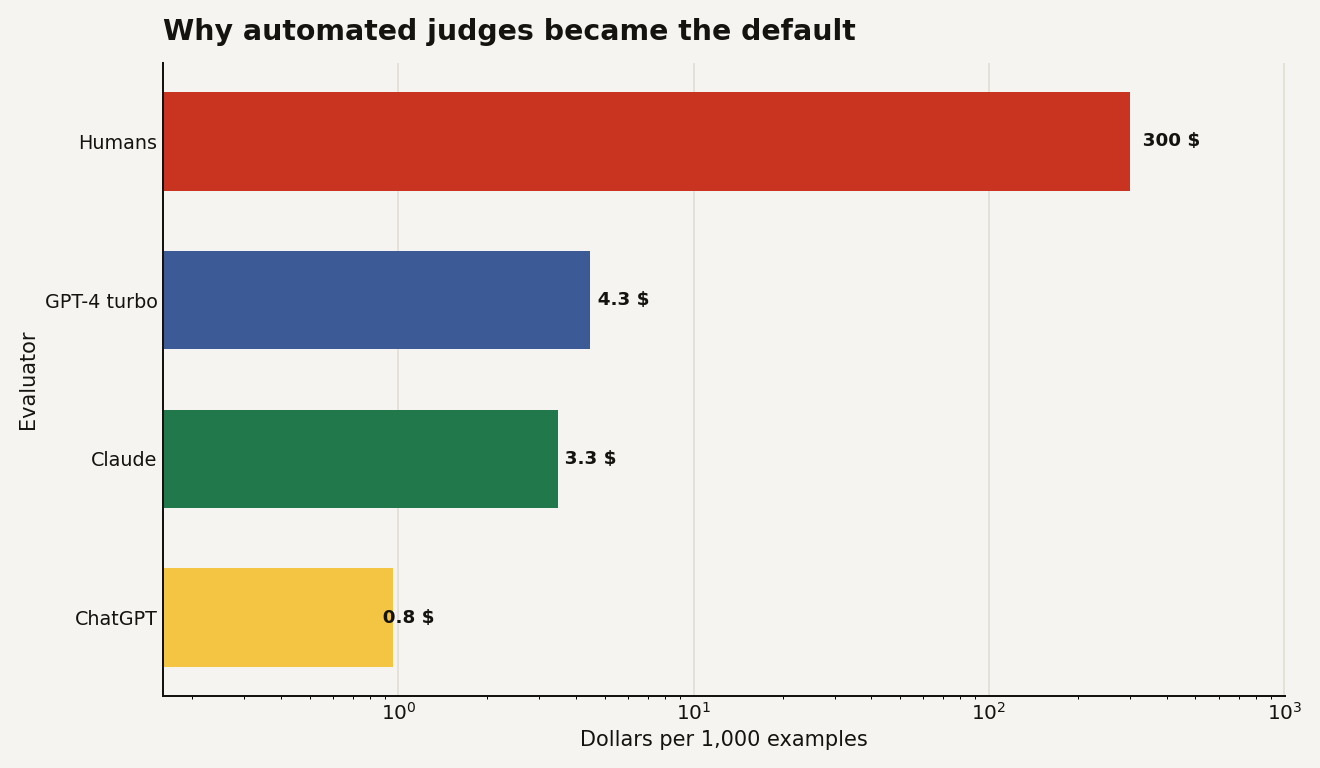
Those numbers do not make automated judges bad. They explain why weak judge protocols spread so quickly. If you can get a rough preference signal for less than 2 percent of the human annotation price, the eval budget shifts from "Can we afford this?" to "How many variants should we try before lunch?"
That shift is good for iteration and dangerous for authority. A cheap judge becomes a gate. A gate becomes a KPI. A KPI becomes a roadmap target. At that point, a manipulable judge is no longer a research oddity. It is a business risk hiding in your release process.
The older fairness literature already showed how easy it is to hack judge behavior. In 2023, Wang and colleagues reported that simply changing answer order could skew results, including a case where Vicuna-13B beat ChatGPT on 66 of 80 tested queries when ChatGPT served as evaluator, according to their arXiv paper. That is the static version of the problem. Dutta and Moharir are pointing at the conversational version.
The business consequence is direct: if your eval decides model promotion, agent routing, vendor spend, or customer-facing release, you need to budget for judge validation. Not just answer validation. The judge is now part of the product surface.
What should you change before the next model bake-off?
Start by treating the judge as a model under test, not as a neutral measurement instrument. That sounds obvious until you inspect most internal eval repositories. Many have strong datasets, decent prompts, and almost no adversarial testing of the judge itself.
A better bake-off protocol has 5 gates.
First, separate the initial answer from the challenge phase. Record the judge's first decision, confidence, and rationale. Then run a standardized challenge script against the same decision. If the verdict flips, label the flip and inspect whether new evidence was introduced or merely persuasive framing.
Second, counterbalance the target. If every challenge argues for model B, you are measuring whether the judge can be steered toward B. You also need matched challenges that argue for model A. Dutta and Moharir's target-validation framing is useful here because it pushes you to distinguish reversibility from one-way steering.
Third, lock down authority language. If phrases like "a senior evaluator found" or "the official rubric says" change outcomes without new evidence, that is a release-blocking judge weakness for regulated or enterprise workflows. Your production users will bring status, anger, legal language, and fake certainty into the loop. The judge will hear all of it.
Fourth, compare rationales, not just labels. A label flip from A to B is already important. A rationale that shares little with the original explanation is a bigger clue that the judge is rationalizing. You do not need a perfect semantic metric on day 1. Even embedding similarity and contradiction checks can flag cases for human review.
Fifth, keep humans in the loop where the cost of a false promotion is high. That does not mean hand-labeling every sample. It means spending human attention on the slices most likely to fool the judge: close calls, high-value workflows, safety-sensitive categories, and examples where the challenge phase changes the verdict.
A minimal protocol could look like this:
| Gate | What you test | Ship signal |
|---|---|---|
| Static rerun | Same input, shuffled order, repeated calls | Low variance is necessary |
| Challenge run | Motivated objection after first verdict | Low reversal rate is better |
| Counterbalance | Equal challenges for both candidates | No one-way steering |
| Rationale diff | Initial versus revised explanation | Low contradiction and high evidence overlap |
| Human audit | Changed verdicts and high-impact slices | Humans decide ambiguous promotions |
The practical stance is simple. Use LLM judges for speed. Refuse to let them become the final authority until they survive the same adversarial treatment your product will face.
What should you watch next?
The next useful benchmark will not be another prettier leaderboard. It will be a judge stress test that product teams can run in CI.
Watch for 3 things after the ACL 2026 GEM paper circulates.
First, code and data. The arXiv abstract does not list a public repository on the page as of June 6, 2026. If the authors release prompts, challenge templates, and ERS calculation code, teams can reproduce the failure mode on their own domains. Without that, the paper is still useful, but adoption will move slower.
Second, domain transfer. MT-Bench and AlpacaEval are general instruction-following settings. The nastier question is whether post-decision manipulability gets worse in legal review, medical triage, security alerts, sales QA, or code review. A judge that flips on a harmless writing task is annoying. A judge that flips on a data deletion policy or SQL migration review is a sev-1 with nicer prose.
Third, whether model providers start reporting judge robustness. Current model cards and eval reports rarely tell you how a model behaves as an evaluator under challenge. They report benchmark scores, safety tests, and sometimes preference data. For judge models, we need reversal rates, steering asymmetry, and rationale stability. ERS is one proposed metric. It will not be the last.
The safer bet is to assume your judge can be influenced until your own logs prove otherwise. That does not kill LLM-as-judge. It makes the pattern more grown-up.
A judge that cannot handle an appeal is not a judge. It is a very confident first draft.
Sources
- arXiv: Stability vs. Manipulability: Evaluating Robustness Under Post-Decision Interaction in LLM Judges
- ACL 2026 GEM Workshop: Program and schedule
- NeurIPS 2023: Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
- GitHub: AlpacaEval automatic evaluator documentation
- arXiv: Large Language Models are not Fair Evaluators