A lot of reasoning-model training discourse treats GRPO, Dr. GRPO, and DAPO as three separate recipes. The useful new claim is smaller and sharper: GRPO standard deviation is the dial that decides whether a prompt teaches the model at all.
Yong Yi Bay and Kathleen A. Yearick argue that, for binary verifiable rewards, the per-prompt GRPO update has a magnitude equal to the sampled group’s empirical standard deviation, and their arXiv page lists the paper as submitted on June 30, 2026. That sounds like optimizer plumbing. It is really a budget question. If your RL run samples eight answers per math problem and all eight are right or all eight are wrong, that prompt can go silent. In their Big-Math analysis, 44% of problems were silent at group size 8, according to the authors’ public repository README.
This matters because RL for reasoning has become the default knob builders reach for after SFT. DeepSeekMath introduced Group Relative Policy Optimization as a PPO variant that improves reasoning while reducing PPO memory usage, and the DeepSeekMath paper reported 51.7% on the MATH benchmark for DeepSeekMath 7B without external toolkits or voting. Since then, variants have piled up: Dr. GRPO removed normalization terms to address bias, and DAPO added dynamic sampling to make large-scale runs more reproducible. Bay and Yearick’s paper gives builders a simpler diagnostic: inspect the group variance before you admire the algorithm name.
What did Bay and Yearick actually prove about GRPO standard deviation?
The paper’s core identity says that when rewards are binary, with k correct samples out of G attempts, the per-prompt GRPO update equals the empirical standard deviation times the contrast between correct and incorrect rollout directions. The authors state the closed form in their GitHub README as sigma equals sqrt(k times G minus k) divided by G.
That gives you a clean mental model. A split group teaches most. A unanimous group teaches nothing. The model learns from disagreement among its own sampled answers.
Here is the tiny version you could put beside a training loop:
sigma(k, G) = sqrt(k * (G - k)) / G
silent_rate(p, G) = p^G + (1 - p)^GThe first line says the update is largest when the group is evenly split. For G equals 8, k equals 4 gives sigma equals 0.5, while k equals 0 or 8 gives sigma equals 0. The second line says a prompt with true solve probability p goes silent when every rollout lands on the same side.
The chart below uses Bay and Yearick’s silent-rate formula at G equals 8. It shows the practical trap: a prompt with solve probability 0.5 is almost never silent at 0.78%, while prompts near 0.1 or 0.9 go silent about 43.0% of the time.
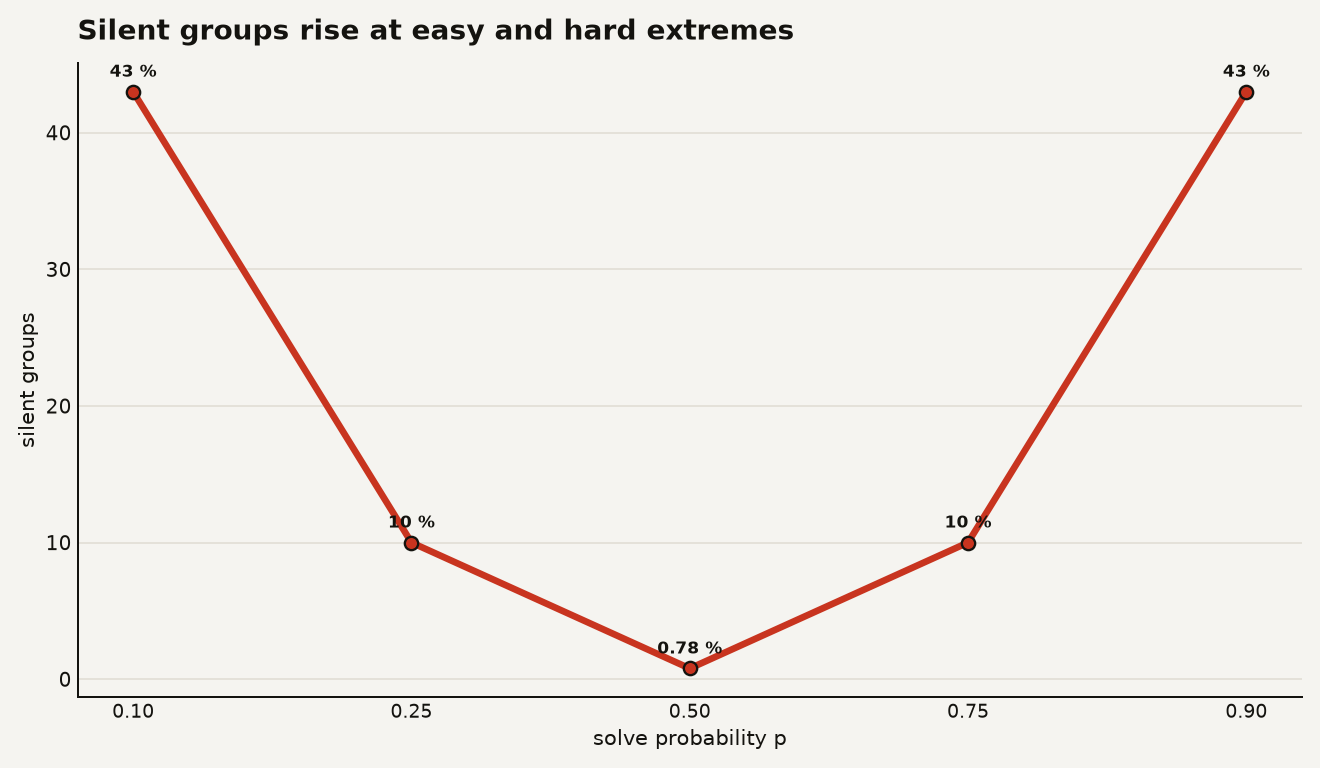
That U-shape explains why “more RL” can mean less learning than your GPU dashboard suggests. If your sampler is feeding the optimizer prompts the current model always fails or always solves, the batch can look busy while the useful gradient thins out.
Bay and Yearick also connect the identity to three named methods. Standard GRPO divides by the group standard deviation. Dr. GRPO drops that division. DAPO discards zero-variance groups. The DAPO paper says its Decoupled Clip and Dynamic Sampling Policy Optimization system reached 50 points on AIME 2024 using a Qwen2.5-32B base model, but this new paper recasts dynamic sampling as a direct response to silent groups rather than a mysterious scaling trick.
Why does a variance identity change your RL roadmap?
Because the identity turns an optimizer choice into an instrumentation choice. If you are training a reasoning model with verifiable rewards, you should stop thinking only in terms of average reward and start tracking how many prompts produce disagreement.
The uncomfortable part is that reward mean can improve while training signal collapses. A model that solves many prompts reliably will produce many all-correct groups. A model that fails many hard prompts reliably will produce many all-wrong groups. Both cases can starve the update under binary rewards.
Bay and Yearick quantify the problem on Big-Math. The original Big-Math paper describes a dataset of more than 250,000 high-quality math questions with verifiable answers, and the Big-Math arXiv abstract says it also introduced 47,000 reformulated questions with verified answers. The processed Hugging Face mirror used by the authors is listed as a 138 MB parquet dataset with files for levels and quintiles on the Open R1 dataset page.
On that solve-rate corpus, the authors report that standardization shifts implicit gradient mass on difficulty extremes from 13.9% to 24.7% and leaves 44% of problems silent at G equals 8 in their repository summary. The chart below puts those two consequences beside each other: more weight on extremes, and a large silent tail.
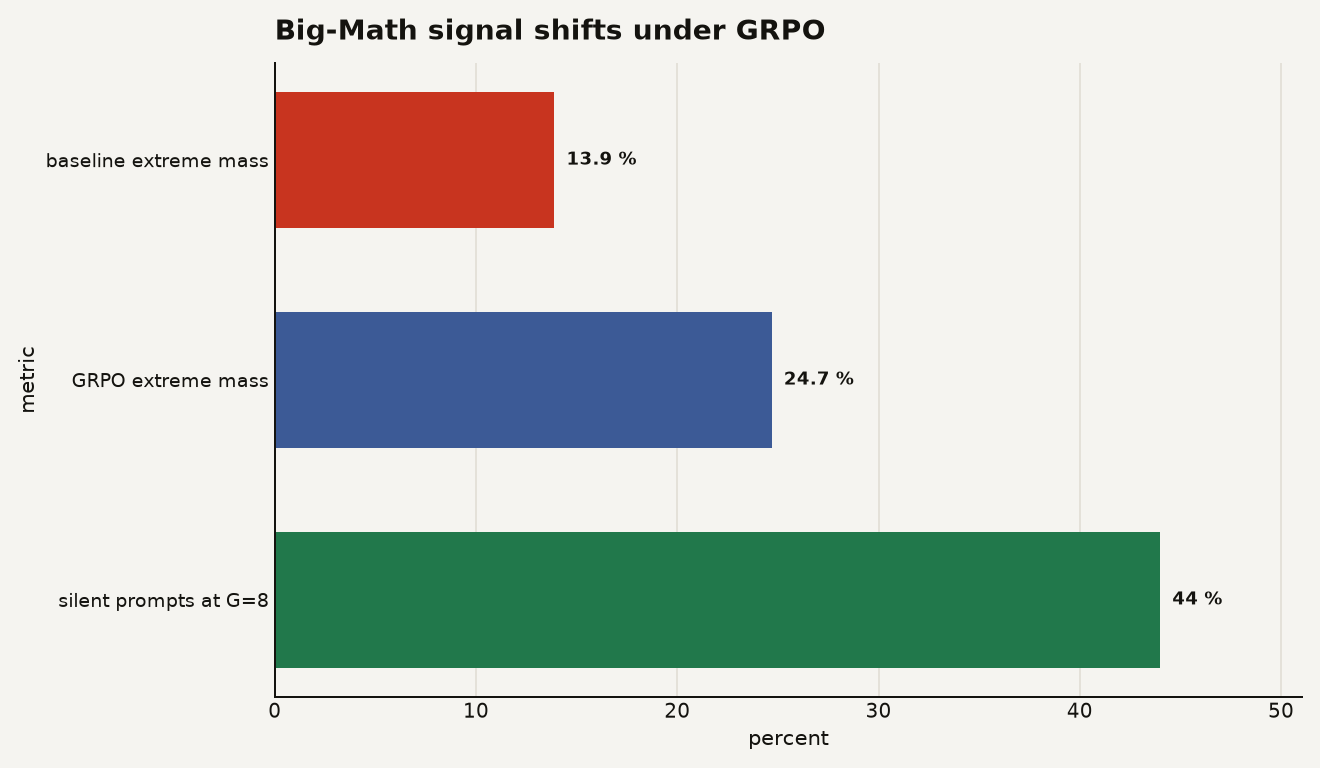
For a builder, this changes three decisions:
- Your data mixer becomes part of the optimizer. If your prompt pool is too easy, you pay for all-correct groups. If it is too hard, you pay for all-wrong groups. The sweet spot is the boundary where the current model disagrees with itself.
- Your group size is a cost control, not a ritual. Bay and Yearick’s README gives a group-size law of G roughly at least 1 divided by 8 epsilon p times 1 minus p, so the needed samples rise near easy and hard extremes.
- Your eval dashboard needs a silent-rate panel. Accuracy, reward, and length are downstream symptoms. The optimizer’s usable signal is closer to the share of groups with both correct and incorrect rollouts.
This also reframes Dr. GRPO. Zichen Liu and coauthors introduced Dr. GRPO after identifying that standard GRPO can artificially increase response length, especially for incorrect outputs, and their arXiv abstract reports 43.3% accuracy on AIME 2024 with a 7B base model. Bay and Yearick do not make Dr. GRPO obsolete. They explain one of the knobs Dr. GRPO removes.
The bigger business consequence is dull but expensive: if your team copied a public GRPO recipe into a domain agent, your bottleneck may be prompt difficulty calibration rather than model size. That affects roadmap and hiring. You may need someone who can build reward diagnostics and data curricula more than another person chasing CUDA utilization.
This is especially true for code and tool agents. We argued in our recent look at coding agent rewards that verification becomes the hard boundary once agents leave toy tasks. The same lesson applies here. A reward checker only helps if the sampled outputs create usable contrast.
What should you instrument before changing algorithms?
Start with four counters. None requires a new model. All four can be logged from your existing RL batches.
First, track the distribution of k correct samples per prompt. For G equals 8, groups with k equals 0 and k equals 8 are silent, while k equals 4 carries the maximum sigma of 0.5 under the Bay and Yearick identity. That one histogram tells you whether your training set is centered on the model’s current frontier.
Second, log silent rate by source dataset. The public Big-Math card lists subsets including Orca-Math at 83,215 problems, cn_k12 at 63,609, olympiads at 33,485, and Big-Math-Reformulated at 47,010 on the SynthLabsAI dataset page. Your internal corpus will have the same unevenness. Some sources will be too easy. Some will be vanity-hard. Both waste samples.
Third, log variance beside reward mean. A rising mean with falling variance can be good in eval, but in training it may indicate that the current batch has stopped teaching. This is where the “GRPO versus DAPO” debate gets practical: DAPO-style filtering is valuable when zero-variance groups are common enough to distort the run.
Fourth, separate length from correctness. Liu and coauthors warned that GRPO can induce longer incorrect outputs, and their paper frames Dr. GRPO as an unbiased method that improves token efficiency while maintaining reasoning performance. If your incorrect rollouts get longer while your variance falls, you have built a very expensive way to watch a model stall.
A simple policy follows:
- If silent groups are high because prompts are too easy, upweight harder prompts or lower sampling temperature less aggressively.
- If silent groups are high because prompts are too hard, add easier bridge tasks or increase group size where the payoff justifies the tokens.
- If middle-difficulty prompts are scarce, invest in data generation and filtering before swapping optimizers.
- If incorrect outputs grow longer, test Dr. GRPO-style length handling before celebrating longer chains of thought.
The temptation will be to turn this into yet another algorithm taxonomy. Resist it. The immediate win is operational: make every RL job report where gradient mass comes from, how much data is silent, and which prompt bands are burning tokens.
What remains unproven before teams bet production training on it?
The paper is an identity plus empirical confirmation, not a full recipe for every RLVR workload. That distinction matters. Bay and Yearick’s arXiv listing describes an 18-page paper with 10 figures and 4 tables, and the abstract says the result is confirmed on Big-Math and in a controlled training run. That is useful evidence. It does not prove that every agentic task with messy rewards behaves like binary math verification.
The open question is how far the identity travels once rewards become graded, multi-step, or judge-model based. A unit test gives you a clean 0 or 1. A code patch with partial correctness, performance tradeoffs, and style constraints gives you a messier signal. The standard-deviation diagnostic should still be informative, but the exact binary identity will need care.
There is also a product question. If your moat is a proprietary data curriculum, this paper points toward a measurable advantage: prompts that sit near the model’s frontier are more valuable than prompts that merely look difficult to humans. The teams with good solve-probability estimates can spend fewer tokens to get the same update.
One bet looks safe: add variance and silent-rate diagnostics now. One bet looks premature: declaring any single member of the GRPO family the winner for all reasoning tasks. The paper’s practical lesson is that optimizer names hide a smaller accounting problem.
The dial was hiding in the batch
The best research papers sometimes make a fashionable stack look embarrassingly legible. Bay and Yearick’s identity does that for reasoning RL. The next time a training run improves, ask a colder question than “Which algorithm did we use?” Ask how many prompts disagreed with themselves.
If the answer is “not many,” your model may be learning less than your invoice suggests.
Sources
- arXiv: GRPO, Dr. GRPO, and DAPO Are Three Operations on One Number
- GitHub: bay-yearick-lab/grpo-standard-deviation-identity
- arXiv: DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
- arXiv: DAPO: An Open-Source LLM Reinforcement Learning System at Scale
- arXiv: Understanding R1-Zero-Like Training: A Critical Perspective
- arXiv: Big-Math: A Large-Scale, High-Quality Math Dataset for Reinforcement Learning in Language Models
- Hugging Face: open-r1/Big-Math-RL-Verified-Processed
- Hugging Face: SynthLabsAI/Big-Math-RL-Verified