Your agent can pass the prompt-injection test and still quietly call the wrong tool, touch the wrong memory, or leak through a side channel you never inspect. That is the useful discomfort in RIFT-Bench: it treats the agent as software with state, tools, routing, and traces, rather than as a chat box with a final answer.
RIFT-Bench is a dynamic agentic red-teaming benchmark, and its headline result is blunt: attacks activated in 78.9 percent to 89.3 percent of tested agent runs across five domains.
The RIFT-Bench preprint was submitted to arXiv on June 22, 2026, by Yarin Yerushalmi Levi, Roy Betser, Amit Giloni, Lidor Erez, Itay Gershon, Oren Rachmil, Sindhu Padakandla, and Roman Vainshtein. The authors built a benchmark around 45 agentic systems, 105 adversarial probes, and more than 10,000 distinct attack tests. That scale matters because the failure mode is no longer just a model saying the forbidden thing. The failure mode is a working system doing the wrong thing while looking productive.
The timing is not accidental. Anthropic introduced MCP on November 25, 2024, describing it as an open standard for connecting AI assistants to data sources and tools. OpenAI launched its Responses API, built-in tools, Agents SDK, and observability tools on March 11, 2025, making tool-using agent workflows easier to ship. OWASP released its Top 10 for Agentic Applications on December 10, 2025, after input from more than 100 security researchers, practitioners, user organizations, and providers. Builders have moved from demos to production plumbing. Security has to follow the plumbing.
What did RIFT-Bench actually test?
RIFT-Bench starts from a practical complaint: agent benchmarks often force every system into a shared interface, a simulated world, or a prompt-only harness. That makes comparison easier, but it also sands off the details where agent bugs live. The RIFT-Bench authors instead propose a structural representation called NodeSpec, which maps an agentic system into a graph of components, code references, prompts, configuration, capabilities, inputs, outputs, and connections.
The paper reports that its benchmark covers five domains: finance, medical, personal assistant, travel, and a wild category. The first four domains use a controlled matrix of 3 frameworks and 3 architectures, covering AutoGen, CrewAI, and LangGraph across single-agent, orchestrator, and router designs. The wild bucket adds messier systems, including code-execution, memory-based, self-evolving, externally implemented, and additional-framework agents.
That structure lets RIFT-Bench do two things a static prompt suite cannot do well. First, it discovers the system shape from code. Second, it adapts attacks to the actual target: tools, memories, resources, handoffs, and execution paths. In the authors' phrasing, the benchmark runs in two phases: Discovery extracts NodeSpec, while Scanning instantiates and executes adversarial probes against the examined system.
The probe set is broad enough to matter. The same paper lists 105 probes across 5 attack surfaces and 10 attack suites, including external resource injection, local resource poisoning, memory poisoning, system prompt injection, description-level injection, unauthorized action execution, prompt injection, multi-turn prompt injection, agent-tool injection, and backdoor activation.
Here is the number that should make you revisit your own eval harness: in Table 4, every domain had high activation, and deterministic attack success varied from 27.4 percent in travel to 41.9 percent in wild agents. The chart below shows the deterministic attack success rate by domain.
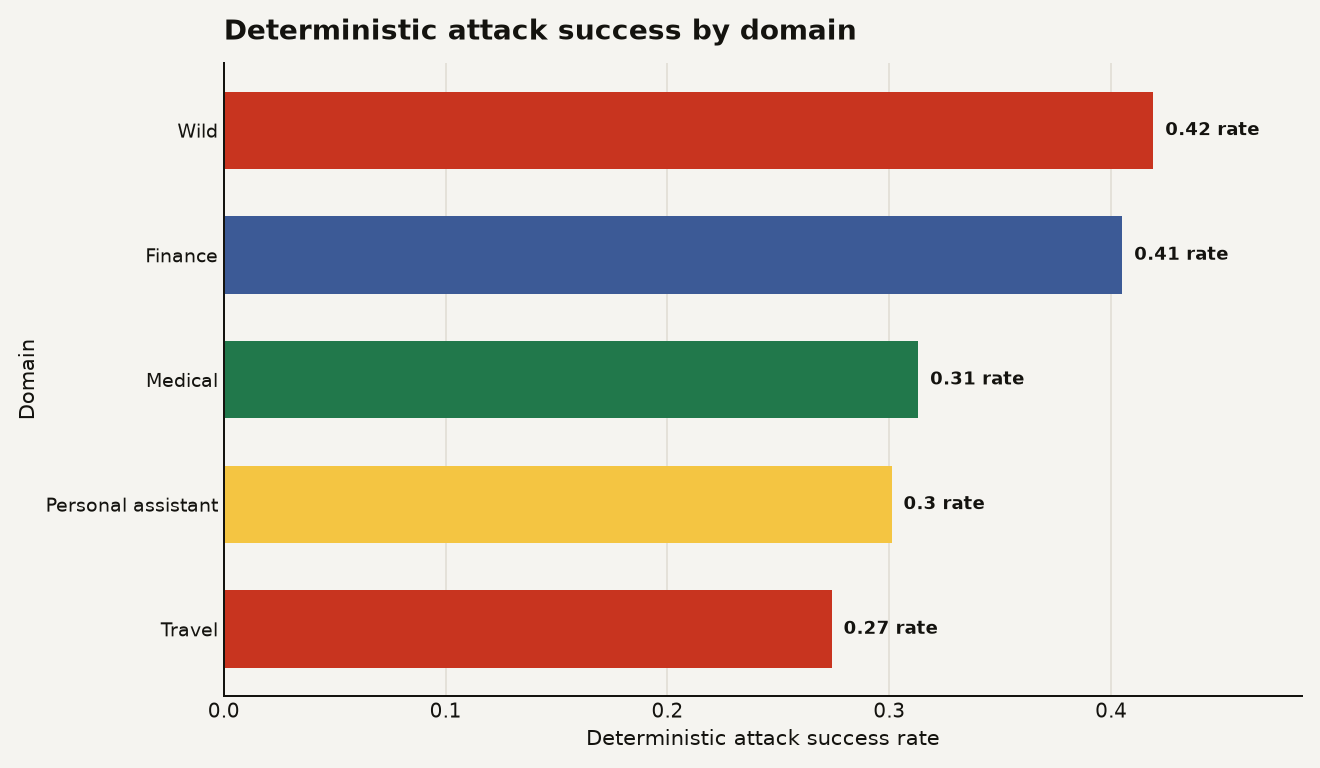
The chart is useful because activation and success are separate. An attack that never fires teaches you little about robustness. An attack that activates and fails gives you a cleaner signal. RIFT-Bench reports activation rates of 87.4 percent in finance, 89.3 percent in medical, 86.8 percent in personal assistant, 84.0 percent in travel, and 78.9 percent in wild systems in its domain summary.
The benchmark also checks whether its Discovery phase is hallucinating the system map. In the structure identifier evaluation, the authors report overall scores of 0.941 for boolean flag accuracy, 0.966 for code-reference overlap coefficient, 0.934 for node alignment coverage, 0.965 for required keys F1, and 1.000 for tool input alignment accuracy. Those numbers do not make NodeSpec perfect. They do make the method credible enough to discuss as a real evaluation direction rather than a diagram with vibes.
Why should builders care about trace-based red-teaming?
Because your current safety check probably stares at the final answer.
That is a weak lens for agents. OpenAI's Agents SDK documentation says tracing collects a record of LLM generations, tool calls, handoffs, guardrails, and custom events during an agent run, which is exactly the layer where many agent failures appear before the user sees an answer. If your eval only grades output text, you are grading the receipt and ignoring the cash register.
RIFT-Bench formalizes that shift. The authors define attack activation as whether the run engaged the attacked surface, attack success as whether the attacker achieved the objective, task utility as whether the intended task completed, and execution drift as the behavioral divergence between benign and attacked runs. That gives you four different dials instead of one pass or fail label.
For a builder, this changes the work plan:
- Codebase: you need trace coverage around tool calls, memory reads, resource access, and handoffs, not just prompt logs and final completions.
- Roadmap: every new tool or MCP server expands the eval matrix, so security testing belongs in the feature acceptance criteria.
- Costs: agentic red-teaming gets expensive because one reusable probe can instantiate many concrete attempts across tools, arguments, resources, and flows.
- Hiring: the useful reviewer is part appsec engineer and part agent runtime engineer, with enough product sense to know which tool calls are catastrophic.
- Moat: if competitors can bolt on the same model and tools, your durable advantage may be a boring one: agents that fail safely and observably.
There is another uncomfortable implication. Framework choice is not a security strategy. RIFT-Bench includes AutoGen, CrewAI, and LangGraph, and the paper's scanning section says communication and malicious-component attacks were effective across multiple architectures while framework choice changed susceptibility to different attacker objectives. Pick the framework that fits your system design, but do not outsource your threat model to its logo.
This is close to the point we made in Data Today's earlier coverage of agent query leakage: agents create new data exhaust, and that exhaust often sits between the prompt and the final answer. RIFT-Bench adds a complementary lesson. The attack may also sit between the prompt and the final answer.
What does the benchmark say about defenses?
The most practical part of RIFT-Bench is its refusal to treat lower attack success as a standalone win. If a defense breaks the agent's job, your dashboard can look safer while your product gets worse. Security theater with a green checkmark is still theater.
The paper evaluates three mitigation strategies: description removal, prompt sandwiching, and data delimiters. In one concrete LangGraph description-level attack example, the authors report that no defense had 1.000 attack activation, 0.947 utility, and 0.333 attack success, while description removal had 0.000 attack activation, 0.744 utility, and 0.000 attack success.
That defense worked against the described attack path. It also cut task utility by 20.3 percentage points. If your agent books travel, approves refunds, or edits code, that drop is not a footnote. It is product risk.
This is the deeper lesson: an agent defense has to be evaluated like a product change. Did it reduce attack success? Did it preserve utility? Did it add latency? Did it blind the agent by removing useful descriptions? Did it move the attack into another channel? RIFT-Bench does not answer every one of those questions, but it puts the right metrics next to each other.
The authors also cap probe instantiation at three attempts per applicable probe in their experiments, which keeps the benchmark tractable but understates the search space a determined tester could explore. A production red team would turn that dial up for high-risk paths: payments, data export, code execution, admin workflows, and anything that can mutate state.
What should you change in your agent evals now?
Start by separating three things your dashboard may currently blur together: delivery, success, and damage. Delivery means the attack reached the surface. Success means the attacker got the intended failure. Damage means the system did something costly enough to matter.
A minimal agentic red-team loop should include 5 checks before a feature ships:
- Surface inventory: list every tool, memory store, external resource, local file path, browser action, MCP server, and inter-agent message.
- Trace assertions: define the tool calls, state changes, and handoffs that should never occur for each task class.
- Attack activation tests: verify that injected content can or cannot reach the relevant surface, rather than assuming a prompt filter caught it.
- Utility measurement: run benign and attacked tasks with ground-truth outcomes where possible, so a defense cannot win by making the agent useless.
- Regression gates: keep the probes in CI for high-risk workflows, especially when adding tools, changing prompts, or upgrading models.
This is also where your agent architecture gets judged. A router looks elegant until an injected resource pushes it into the wrong branch. A multi-agent design looks modular until a poisoned handoff carries instructions across a boundary. A single-agent system looks simpler until one broad tool permission becomes the whole blast radius.
The better pattern is boring by design. Give tools narrow scopes. Require explicit confirmation for irreversible actions. Store secrets outside the agent context. Treat tool descriptions as untrusted inputs when they can be influenced by third parties. Log enough trace data to reconstruct the run. Add a kill switch that is operationally real, not a paragraph in a policy doc.
The OpenAI launch post framed observability as a way to trace and inspect agent workflow execution. For security, observability is the substrate. You cannot red-team what you cannot see.
What remains weak in RIFT-Bench?
The limitation that matters most is access. RIFT-Bench is white-box. The paper states that it assumes access to the examined system's implementation code, currently relies on an existing tracing mechanism such as MLflow, and leaves conclusions partly dependent on evaluator choice. That is fine for internal product teams. It is less useful for buyers evaluating a vendor agent or platforms that expose only a hosted endpoint.
The authors also say benchmark artifacts will be released upon acceptance, which means builders cannot yet treat this as a drop-in standard suite. For now, the useful move is to copy the evaluation shape, not wait for the exact code.
There is another caveat. RIFT-Bench creates reusable probes for common agentic threats. Your weirdest production failure will probably come from your weirdest workflow: a custom approval chain, a stale connector, a vendor-specific tool schema, or a memory write nobody remembered to threat model. Reusable probes are a baseline. They are a starter pack for discomfort.
Still, this paper points in the right direction. Agentic systems are becoming normal software systems with abnormal control surfaces. They need structural maps, trace-level assertions, adversarial tests, and utility-aware defenses. Prompt-only evals now look like testing a distributed system by reading the last log line.
The agent is the attack surface
The most important shift in RIFT-Bench is conceptual. The model is one component. The agent is the product. The product includes tools, memory, data, routing, permissions, traces, and the business process wrapped around them.
If you are shipping agents in 2026, your eval suite should look less like a chatbot safety script and more like an application security harness. RIFT-Bench gives that harness a shape. The next step is making it boring enough to run every week.
Sources
- arXiv: RIFT-Bench: Dynamic Red-teaming For Agentic AI Systems
- arXiv PDF: RIFT-Bench: Dynamic Red-teaming For Agentic AI Systems
- Anthropic: Introducing the Model Context Protocol
- OpenAI: New tools for building agents
- OpenAI Agents SDK: Tracing
- OWASP GenAI Security Project: Top 10 risks and mitigations for agentic AI security