Workplace agents used to be a demo with a liability problem. They could schedule the meeting, except when they emailed the wrong person. They could update the CRM, except when they touched the wrong customer record. That is the exact kind of almost-useful software that makes a product lead reach for a spreadsheet and a lawyer.
WorkBench agents are now much closer to usable: the new paper reports 89 percent task completion with a 2.5 percent harmful-action rate.
WorkBench agents are AI systems tested on a simulated workplace: email, calendar, website analytics, CRM, and project management tasks. In the new paper, Olly Styles revisits the benchmark two years after the original 2024 release. The headline number is not subtle: the best agent in the 2026 arXiv abstract, Claude Opus 4.8, completes 89 percent of the 690 workplace tasks and causes unintended harmful side effects on 2.5 percent of them, compared with GPT-4's 43 percent completion and 26 percent harmful-action rate in March 2024, according to the new WorkBench Revisited paper.
There is one wrinkle worth calling out early. The public WorkBench repository's README now says the 2026 release re-evaluates 24 models and reports Claude Fable 5 at 92 percent completion with 1.9 percent harmful actions, while the arXiv abstract names Claude Opus 4.8 at 89 percent and 2.5 percent. That looks like a moving benchmark artifact, not a reason to ignore the result. The safer read is this: the paper's published abstract already shows a huge reliability jump, and the project data suggests the frontier has moved a little further again.
What did WorkBench actually measure this time?
WorkBench is useful because it does not grade agents on vibes. The original benchmark defined a sandbox with five databases, 26 tools, and 690 tasks, then judged whether the final database state matched the unique ground-truth outcome for each task, according to the 2024 WorkBench paper. That matters because tool-call correctness is a weak proxy. A model can call a plausible function and still create the wrong business state.
The 2026 revisit keeps the focus on outcomes. The project README says all 2026 per-task results are committed under data/results/, figures read from retro/data/model_results.json, and correctness and safety numbers are derived by the same scoring pipeline as workbench-evaluate. That is the right shape for an agent benchmark: reproducible traces, outcome scoring, and no hand-maintained leaderboard numbers.
The chart below puts the result in the only framing a builder should care about: correct work, harmless failure, and harmful side effects as shares of the same 690-task suite. GPT-4 in 2024 completed 43 percent of tasks and caused harmful side effects on 26 percent. Claude Opus 4.8 in the 2026 arXiv abstract completed 89 percent and caused harm on 2.5 percent. The WorkBench repo's current README reports Claude Fable 5 at 92 percent and 1.9 percent.
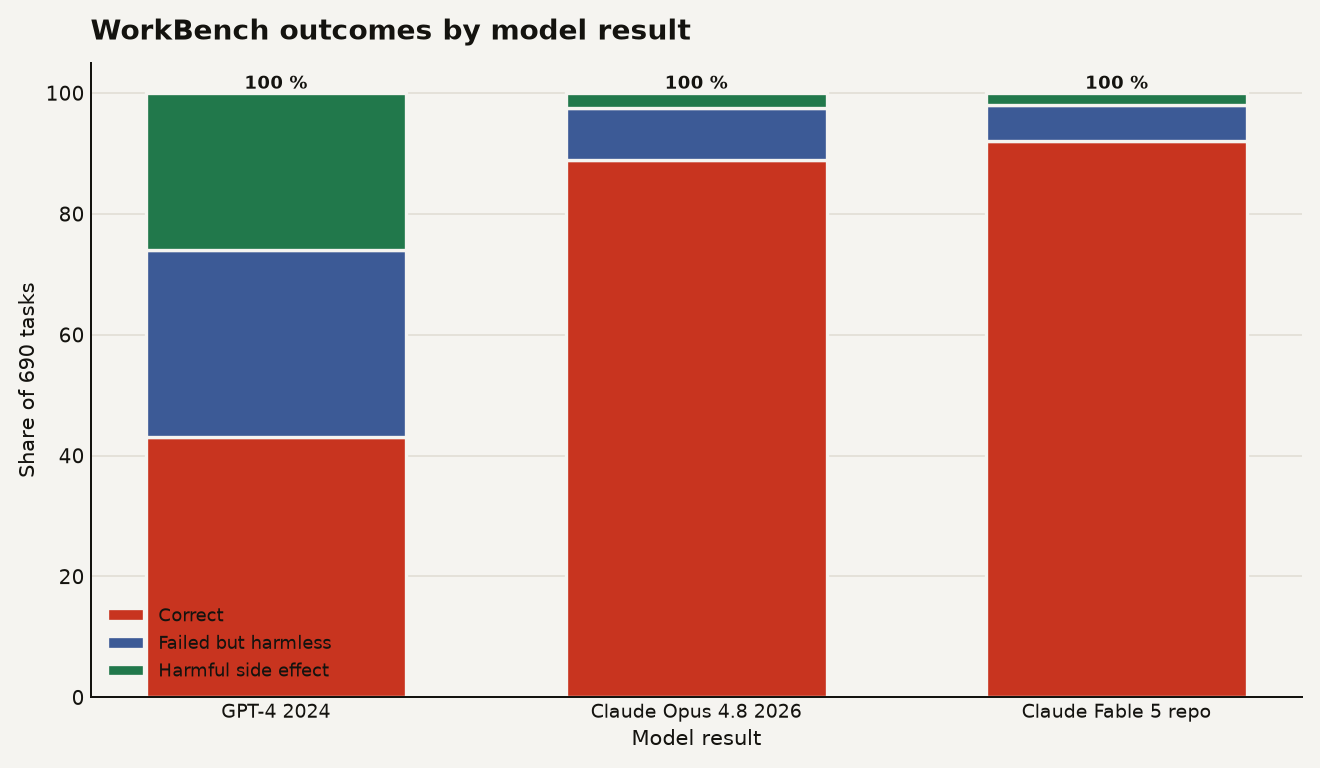
That shape is the story. The improvement is not merely that the correct band grew. The harmful band shrank by roughly an order of magnitude from the 2024 GPT-4 baseline to the 2026 frontier result. A benchmark can still be narrow and useful at the same time. This one is narrow in a way that maps to real product risk: did the agent mutate the workplace state correctly, fail safely, or make a mess?
The more interesting claim in the 2026 abstract is that capability and safety moved together on WorkBench. The paper says the models that finish the most tasks also do the least unintended damage. That is not guaranteed in agent systems. You can imagine a more aggressive model bulldozing through tasks and creating more side effects. On this benchmark, at least, better models appear to be more careful agents, not just more active ones.
Why should builders treat 2.5 percent harm as both good and dangerous?
A 2.5 percent harmful-action rate is a massive improvement over 26 percent. It is also not a production-ready number for many workflows.
The difference depends on blast radius. If an agent drafts an email and a human approves it, 2.5 percent is an annoyance tax. If it sends the email itself, updates Salesforce, cancels a meeting, or changes a customer refund status, 2.5 percent is a recurring incident generator. At 10,000 autonomous actions per month, that rate implies 250 harmful actions before downstream controls catch anything. Even if the WorkBench setting is more compressed than your app, the point holds: action permissions matter more than chat quality.
This is where the benchmark should change your roadmap. If you are building workplace agents, the question is no longer whether tool-using agents can do meaningful work. They can. The question is where your product draws the line between autonomous execution and gated execution.
For a team shipping an agent feature in 2026, WorkBench points to four practical decisions:
- Use outcome-based evals, not transcript reviews. If your eval says the agent called
send_emailwith valid JSON, you are measuring formatting. WorkBench measures whether the final state is right. - Classify tools by irreversibility. Read-only retrieval, draft creation, and reversible updates deserve different permissions from sending, deleting, charging, refunding, and publishing.
- Budget for failure handling. A harmless failure is a product experience problem. A harmful side effect is an operations, support, and trust problem.
- Do not overpay for yesterday's frontier. The WorkBench abstract says open-weight models have lowered costs for performance that previously required proprietary models, while frontier costs stayed relatively stable.
That last point is underrated. If open-weight models can now clear older proprietary-agent thresholds, your moat is less likely to be model access and more likely to be workflow design, data permissions, eval coverage, and recovery tooling. This matches the direction we covered in AgentPerf's hardware view of agent economics: agent progress is increasingly a systems problem, not a single-model trophy.
There is also a hiring implication. You do not only need prompt engineers. You need people who can model state, write adversarial task suites, inspect side effects, and design approvals that users will actually tolerate. The boring job titles win here: backend engineer, security engineer, QA lead, support ops owner.
What should you change in your agent stack this quarter?
Start by copying the WorkBench instinct, not the WorkBench tasks. Your product has its own equivalent of the five sandbox databases. For a sales tool, that might be contacts, opportunities, email drafts, call notes, and billing status. For a dev tool, it might be issues, branches, pull requests, CI results, and package releases. For an internal ops agent, it might be tickets, Slack posts, permissions, purchase orders, and payroll metadata.
Then build an eval set where each task has one expected final state. The number does not need to be 690 on day one. A serious internal harness with 50 to 100 high-frequency tasks will teach you more than a leaderboard screenshot. The trick is to include the ugly cases: similar names, stale records, ambiguous requests, missing permissions, and tools that should not be called.
A clean policy starts with three execution lanes:
- Autonomous lane: low-impact, reversible tasks where a wrong move costs seconds.
- Review lane: customer-visible or state-changing tasks where a human approves the proposed diff.
- Blocked lane: irreversible, regulated, or high-value actions unless a separate system grants permission.
This is not glamorous architecture. It is how you turn a 2.5 percent benchmark harm rate into a product users can trust. The agent should not be deciding alone whether a task is safe to execute. Your application should decide based on tool, user role, resource type, dollar value, and audit requirements.
Also, log state transitions, not just prompts. If the agent changed three records and sent one message, your audit log should show the before state, proposed after state, executed after state, model, tool call, user, and approval status. When something goes wrong, a chat transcript is a postcard from the crime scene. A state diff is evidence.
Where could the benchmark still be fooling us?
WorkBench is a strong benchmark because it is outcome-centric. It is still a benchmark. The world has messier identity resolution, half-migrated schemas, rate limits, flaky APIs, conflicting policies, weird user intent, and coworkers who name two projects almost the same thing because chaos apparently needed branding.
The 2026 arXiv abstract itself concedes that basic mistakes persist, including irreversible harm like sending an email to the wrong person. That sentence should keep product teams sober. A model that gets 89 percent right in a controlled sandbox may still fail in ways that users experience as betrayal, not statistical noise.
The repo discrepancy also matters. The paper abstract and README currently name different top models and different best scores. That is normal in fast-moving agent research, but it means you should pin model versions, dataset versions, scoring code, and run dates in your own evals. If your benchmark result cannot be reproduced three weeks later, it is a vibe with a CSV costume.
The right bet is not full autonomy everywhere. The right bet is narrower: agents can now own bounded workplace loops when you give them typed tools, state-based evals, permission tiers, and recovery paths. That is enough to ship useful software. It is not enough to fire the humans and let the bot run finance.
What does this mean for the agent hype cycle?
The lazy take is that agents are solved. The equally lazy take is that a 2.5 percent harmful-action rate proves they are unusable. Builders should reject both.
WorkBench Revisited shows that workplace agents have crossed a line from toy to tool. The remaining work is less cinematic than the demos: schema design, evals, approvals, cost routing, audit logs, and incident handling. If that sounds like normal software engineering, good. Agents are finally becoming normal enough to deserve it.


