The useful agent is not the one that writes the cleverest paragraph. It is the one that can sit in a loop, touch the data, run the experiment, read the ugly score, and make the next boring improvement without wandering off into vibes.
That is why generalist agents just got a more interesting test than another browser task. In a June 2026 arXiv preprint, Feiyang Kang, Hanze Li, Adam Nguyen, Mahavir Dabas, Jiaqi W. Ma, Frederic Sala, Dawn Song, and Ruoxi Jia introduce Curation-Bench, a benchmark that asks whether generalist coding agents can automate data curation for model training. The headline number is awkward in the right way: out-of-the-box agents can match strong published data selection baselines within 10 iterations, but the best result comes when the agent is forced to cite and adapt prior methods, after which it beats published baselines at one-tenth of their data budget in a vision-language instruction-tuning setup, according to the Curation-Bench preprint.
That is not a story about agents replacing research teams next quarter. It is a story about where the boundary has moved. Agents can now operate the data curation machine. They still need a method rail to do research rather than fidget with knobs.
If you build AI products, that distinction matters. Your next edge probably will not come from asking an agent to “improve the dataset” and walking away. It will come from giving it a constrained lab notebook, a searchable method library, a budget, and the authority to run small, auditable experiments.
What did Curation-Bench actually ask the agents to do?
Curation-Bench is designed around the part of AI development that teams talk about less because it is less glamorous: choosing and revising the data policy. The benchmark fixes the model, training recipe, and evaluation suite. The agent gets command-line access. It can inspect data, implement selection policies, submit them to a fixed train and eval pipeline, and revise based on the results.
That setup matters because it avoids the usual benchmark cheat. If the model architecture, recipe, and evaluation are all moving at once, you cannot tell whether the agent improved the data or just found a lucky training setting. Here, the variable under test is the curation policy. The agent lives in the loop that human data researchers already use: propose, implement, train, evaluate, revise.
The authors instantiate the benchmark in vision-language instruction tuning. That is a sensible test bed because multimodal models are visibly data-sensitive. The original LLaVA project, for example, built a visual instruction-tuning dataset with 158,000 unique language-image instruction-following samples, split into 58,000 conversations, 23,000 detailed descriptions, and 77,000 complex reasoning examples, as the project’s official LLaVA page describes. That kind of data mix is not incidental plumbing. It shapes what the model can do.
The broader field has been moving this way for years. DataComp, a multimodal data benchmark from 2023, made the data-policy problem explicit by giving participants a 12.8 billion image-text-pair candidate pool and a standardized CLIP training and evaluation setup across 38 downstream test sets, according to the DataComp paper. The lesson was clear: when training recipes become standardized, data selection becomes the battleground.
Curation-Bench pushes that battleground into the agent era. It asks whether a general-purpose coding agent can behave like a junior data researcher with shell access and a scoreboard.
The answer is: sort of. And “sort of” is more useful than “yes.”
Why is ten iterations a meaningful ceiling?
The paper’s most practical claim is not that agents become brilliant. It is that out-of-the-box agents reach strong published data-selection baselines within 10 iterations. For a builder, that is the unit to care about.
An iteration is not a chat message. It is a paid experiment. It can involve scanning data, editing code, launching training, running evaluation, storing logs, and deciding what to try next. In a real company, 10 iterations means GPU time, queue time, engineering attention, and a bigger chance that some flaky evaluation contaminates the decision.
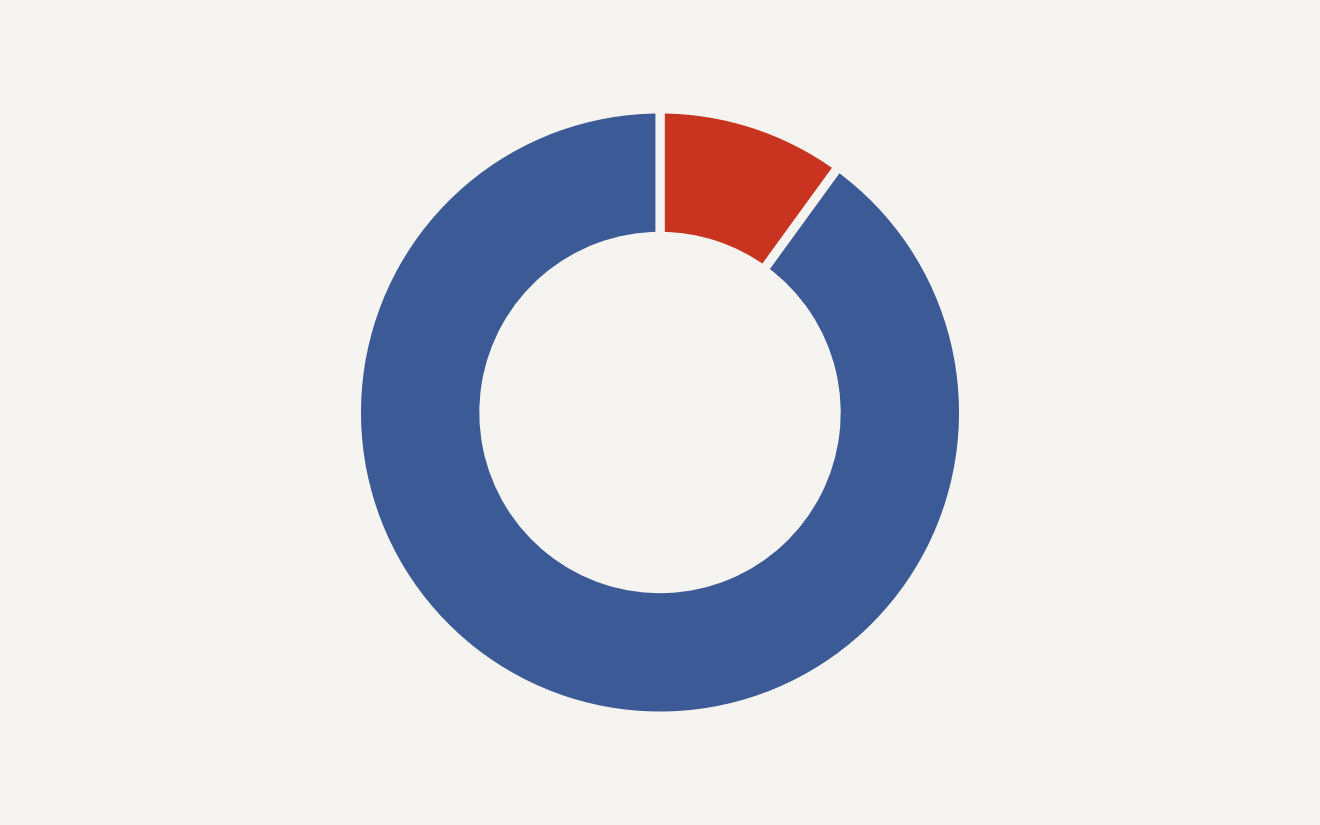
This is where the chart for this story lands. The Curation-Bench paper reports that the scaffolded agent beats strong published baselines at one-tenth of their data budget. Relative to a 100 percent baseline budget, that means 10 percent used and 90 percent avoided. The chart visualizes that ratio, not as magic savings, but as the economic reason this line of work matters.
A 10 percent data budget changes the shape of a project. You can run more ablations before the weekly model review. You can test narrower slices of customer data without hauling the whole warehouse into the training job. You can keep more experiments inside a laptop-scale or single-node workflow before you ask finance for the spicy cloud bill.
There is a catch. The budget saving came from a scaffolded agent, not pure open-ended prompting. The preprint says the authors saw a persistent “execution-research gap”: agents mostly tuned local policy variants instead of exploring new policy families, even when given strategy guides and paper references. In plain English, the agent kept rearranging the furniture instead of asking whether the house needed another room.
That tracks with what agent benchmarks have been teaching outside data curation. OpenAI’s MLE-bench used 75 Kaggle competitions to test machine-learning agents, and its launch result found the best setup at the time, o1-preview with AIDE scaffolding, reached at least a Kaggle bronze-medal level in 16.9 percent of competitions, according to OpenAI’s MLE-bench announcement. The important word there is scaffolding. The model alone is not the product. The loop is the product.
What breaks when the agent has to invent the research plan?
The failure mode is subtle, which makes it dangerous. The agent does useful work. It writes code. It runs the pipeline. It improves scores. Then it plateaus because it searches near what it already tried.
That is a familiar engineering trap. Local search feels productive because every diff is concrete. A data policy gets a new threshold. A sampler gets a new weight. A filter gets a different score cutoff. The spreadsheet moves. The benchmark may even improve by 0.2 points. Meanwhile, the unexplored method family that would have changed the result sits untouched in the literature.
Curation-Bench’s answer is to change the agent’s job description. The stronger scaffold requires each iteration to cite, instantiate, and adapt a prior method. That forces the agent to move through a method space rather than just a parameter space.
This is the most important product takeaway: data curation agents need research memory, not just tool access.
A naive agent loop looks like this:
- Read the last metric.
- Modify the current policy.
- Run again.
- Hope the leaderboard smiles.
A better loop looks like this:
- Pick a method family from an indexed method library.
- State why it fits the dataset failure mode.
- Implement the smallest faithful version.
- Compare against the current policy under the same budget.
- Record what changed, including dead ends.
That is less cinematic. It is also how serious teams avoid spending six weeks rediscovering a weaker version of an old paper.
Data Today has been skeptical of unstructured agent loops for exactly this reason. In our earlier piece on why agents are working too hard, the useful pattern was not “give the agent more freedom.” It was narrowing the task until the agent could produce reliable work inside a bounded controller. Curation-Bench points in the same direction. The agent gets better when the workflow becomes more opinionated.
What should you change in your data pipeline now?
Do not reorganize your roadmap around autonomous data scientists. That title is still doing more marketing than engineering.
Do reorganize your pipeline so agents can safely run bounded curation experiments. The Curation-Bench result says the loop is automatable when the environment is fixed, the commands are clear, and the evaluation is repeatable. Most internal ML stacks are not there. They are a tangle of notebooks, undocumented filters, stale validation splits, and one person named Maya who remembers why train_v7_final_final.csv exists.
If you want generalist agents to help with data curation in 2026, your first hire may not be another prompt engineer. It may be the engineer who turns your data research process into a harness.
Concretely, build for this:
- A fixed evaluation contract. The agent should not be able to silently change the model, recipe, or metric while claiming a data win. Curation-Bench fixes these variables for a reason.
- A versioned policy interface. Treat data selection logic like code. Every policy needs a name, inputs, outputs, diff, and rollback path.
- A method library. Store papers, internal experiments, failed attempts, and reusable templates in a format an agent can retrieve and cite before it edits code.
- A hard budget. Make the agent spend from a visible allowance: 10 runs, 20 GPU hours, 5 million examples, whatever matches your economics.
- A human review gate for promotion. Let the agent explore. Do not let it bless production data alone.
The business consequence is just as direct. If your moat is “we have proprietary data,” that is thinner than it sounds. The operational moat is knowing which slices of that data matter, how to test them, and how fast you can turn failed experiments into reusable method knowledge. Curation-Bench suggests agents can compress the loop, but only if your organization has made the loop legible.
This also changes vendor evaluation. When an agent platform claims it can improve your model, ask for the boring proof: How many iterations? What budget? Which variables were fixed? Can it cite the method it adapted? Can it reproduce the losing runs? If the demo cannot answer those five questions, it is theater with a progress bar.
What would prove this is more than a tidy demo?
The next test is breadth. The current Curation-Bench result is in a vision-language instruction-tuning instantiation. That is important, but not enough to declare victory across tabular fraud models, retrieval systems, speech pipelines, recommendation models, or safety classifiers.
The benchmark also needs pressure from messier settings. Real curation work includes mislabeled data, privacy constraints, legal holdouts, moving distributions, duplicate customer records, and evaluation sets that age badly. A fixed pipeline is good science. Production is a raccoon in the vents.
The useful follow-up work should answer four questions:
- Can the scaffold transfer across 3 or more model families, not just one vision-language recipe?
- Does the agent still find new method families when the evaluation signal is noisy or delayed?
- How much of the gain comes from the scaffold versus the underlying model?
- What is the total cost per successful policy, including failed runs and reviewer time?
That last number will decide adoption. A policy that beats a baseline at 10 percent of the data budget is exciting. A policy that burns 40 expensive failed attempts to get there may still be worth it in frontier-model training, but not for a mid-market SaaS classifier retrained every Friday.
There is also a governance angle. Once agents can autonomously select training data, they can also autonomously select away inconvenient cases. If your evaluation does not cover minority cohorts, edge cases, or failure-critical scenarios, an optimizer will learn that absence. Data curation is not neutral because data selection is model behavior by another route.
So the near-term bet is narrow and strong: use agents to generate candidate data policies under strict experiment control. Do not use them as free-range arbiters of what your model should learn.
The boring moat is the method library
Curation-Bench is a useful cold shower. Generalist agents can run the curation loop. They can even deliver a striking budget result when the workflow forces them to adapt real methods. But open-ended prompting still behaves like a talented intern with no lab notebook: energetic, plausible, and too local in its search.
The advantage goes to teams that make their data work inspectable. Not prettier. Inspectable.
If your curation knowledge lives in Slack threads and abandoned notebooks, an agent will inherit the mess. If it lives in versioned policies, reproducible evals, and a method library the agent must cite before acting, you have something better than a demo. You have a compounding system.
That is the least flashy version of the agent future. It is also the one most likely to ship.