
Agent builders have been treating parallelism like a coupon code: run more trajectories, hope one of them finds the answer, then vote or rank the outputs. DivInit, a new method for agentic search, says the waste starts earlier than that. The problem is the first search query.
If four agents all ask the web the same question, you bought four receipts for one idea.
The paper, by Sidhaarth Murali, João Coelho, Jingjie Ning, João Magalhães, Bruno Martins, and Chenyan Xiong, was submitted to arXiv on June 15, 2026. Its claim is narrow and useful: when a ReAct-style search agent runs several parallel rollouts, those rollouts often collapse onto similar first queries, which makes their retrieved evidence overlap and limits the value of breadth.
The headline result is the part you can actually use. Across five open-weight models and eight benchmarks, DivInit improved pass@4 by 5 to 7 points on multi-hop QA at matched compute. The method does not train a model, add a reward model, or require a new retriever. It samples a pool of first-query candidates, picks diverse seeds, and then lets the usual parallel agents run.
If you have been following our coverage of agent reliability gaps, this lands in a familiar place. Agent quality often improves less from a larger brain than from removing a dumb bottleneck in the loop. Here, the bottleneck is the first query.
What did DivInit actually change in the search loop?
DivInit changes one step: the initialization of parallel search trajectories. The authors' repository describes the method as generating a pool of candidate queries in one LLM call, selecting k diverse seeds with greedy max-min Jaccard, and launching one trajectory per seed.
That matters because the normal setup is surprisingly fragile. Standard parallel sampling launches k threads independently, but the authors say those threads cluster around near-identical turn-one queries with QPD around 0.2. Once the first retrieval overlaps, later reasoning sees much of the same evidence, so the rollouts can fail together.
The paper frames this as a test-time scaling problem. The old self-consistency idea, published in 2022, sampled many reasoning paths and selected the most consistent answer, reporting gains such as 17.9 percentage points on GSM8K. DivInit borrows the spirit of breadth but applies it to tool-using search, where the model's first action changes the evidence it will see.
The ReAct setup matters here because the agent alternates between reasoning and external actions. In the original ReAct paper, the authors described a language model that generates reasoning traces and task-specific actions in an interleaved manner, which means early actions can shape the rest of the run.
The practical version is simple enough to fit in a code review comment:
candidate_queries = llm.generate_pool(question, n=16)
seeds = max_min_jaccard(candidate_queries, k=4)
run_parallel_agents(question, first_queries=seeds)The repository's reproduction command uses k equal to 4, pool size equal to 16, and max turns equal to 8. Under the authors' formula, standard parallel sampling costs k times T calls, while DivInit costs one plus k times T minus one, so that example moves from 32 turn calls to 29 before counting retrieval and ranking details.
That is a rare kind of agent paper result: better accuracy with a control-flow change you can explain to a backend engineer before coffee goes cold.
How big were the gains when the model size changed?
The cleanest read comes from the Qwen3 multi-hop QA averages. The authors report that Qwen3-1.7B moved from 25.0 percent to 27.8 percent pass@4, Qwen3-4B moved from 29.5 percent to 36.6 percent, and Qwen3-8B moved from 38.6 percent to 46.0 percent in the published results table.
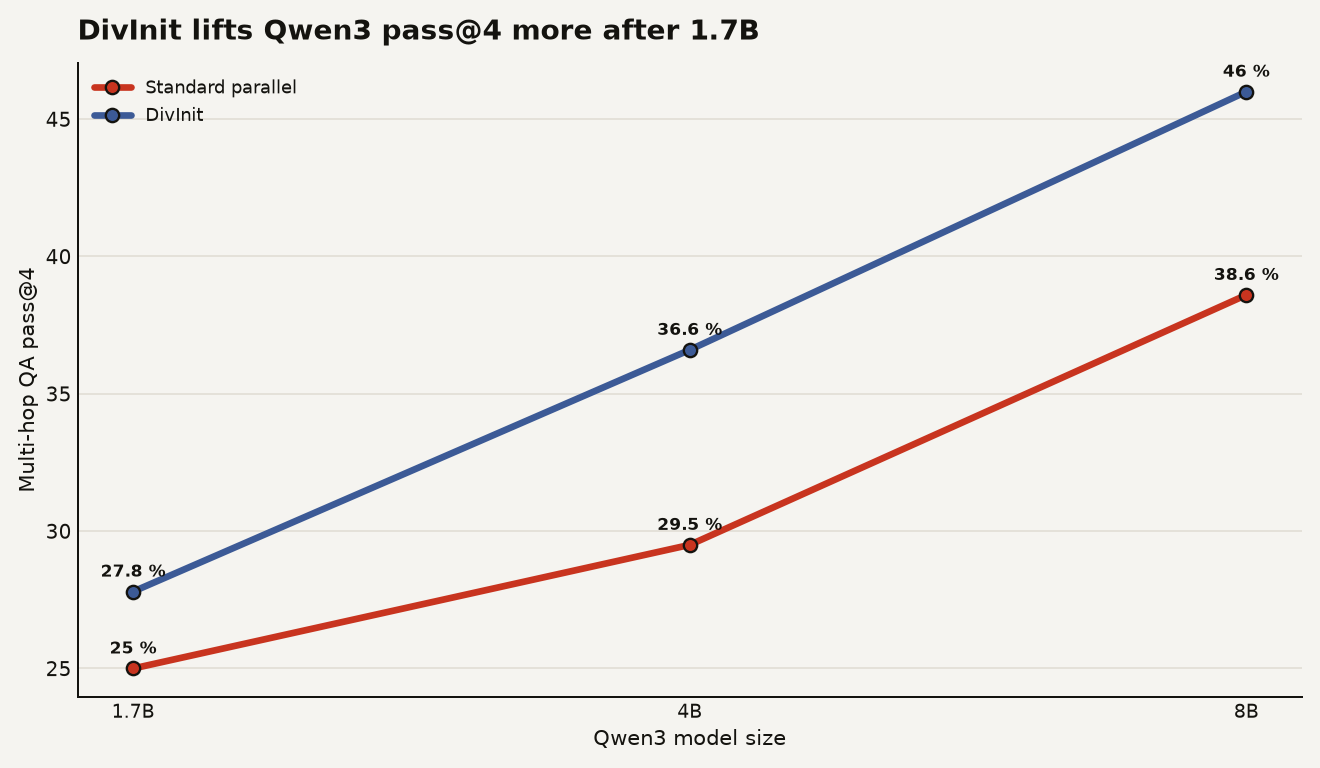
The chart below is the useful shape: DivInit barely moves the smallest model, then starts paying off once the model has enough capacity to exploit different evidence. The absolute gain is 2.8 points at Qwen3-1.7B, 7.1 points at Qwen3-4B, and 7.4 points at Qwen3-8B, using the same repository table.
That capacity floor should calm down two bad instincts. The first is to throw DivInit onto every tiny local agent and expect magic. The second is to decide retrieval diversity is solved because a bigger model can reason harder. The data says the method and the model interact.
Qwen's official model post says the Qwen3 dense family includes 0.6B, 1.7B, 4B, 8B, 14B, and 32B open-weight models. Google says Gemma 3 ships in 1B, 4B, 12B, and 27B sizes, and the DivInit repository reports results for Gemma3-4B and Gemma3-12B as well as the Qwen models.
The Gemma numbers mostly rhyme with Qwen. Gemma3-4B rises from 28.0 percent to 34.0 percent on the five multi-hop datasets, while Gemma3-12B rises from 45.0 percent to 50.2 percent in the same results table. That is a smaller gain for the 12B model than Qwen3-8B shows, but it still supports the main claim: diverse first queries make breadth less redundant.
The authors also tested open-web tasks. For Qwen3-4B, the repository reports open-web average pass@4 rising from 23.7 percent to 29.0 percent, while Qwen3-8B rises from 25.2 percent to 28.2 percent in the GAIA, HLE, and WebWalker columns. Those gains are smaller and messier, which is exactly what you should expect when the web, retrieval, and grading all add noise.
Why should builders care if the first query collapses?
Because agentic search cost scales in more places than the model bill. Every parallel trajectory can mean more tool calls, more search API calls, more retrieved documents to store, more traces to inspect, and more failure cases for support to explain.
If your current plan is "run 8 agents and pick the best answer," DivInit points to a sharper question: are those 8 agents actually exploring 8 evidence neighborhoods? The authors' central warning is that standard parallel threads can retrieve the same evidence and fail together. That is deadly for enterprise search, legal research, customer support, and any RAG system where the missed document matters more than the average answer.
Here is the builder consequence:
- Your roadmap should treat query diversity as a first-class metric. Log the first query for every rollout, compute token overlap or Jaccard distance, and alert when parallel rollouts converge.
- Your cost model should price redundant retrieval. Four trajectories with overlapping first results are a worse product than one good trajectory with a verification pass.
- Your evals should separate answer voting from evidence discovery. If all rollouts see the same pages, a majority vote is just a louder single mistake.
- Your moat is less likely to be the wrapper. A small routing change can deliver several pass@4 points, so proprietary advantage comes from instrumented workflows and domain-specific evidence, not from calling parallelism a platform.
This is where DivInit is underrated. The paper is easy to file under agent benchmarks, but the deeper lesson is product instrumentation. If you sell an AI research assistant, the customer does not care that your agents ran in parallel. The customer cares that one thread found the document the other thread missed.
The method also fits existing stacks. The repository says DivInit is training-free and plugs into any ReAct-style agent. That makes it especially attractive for teams that cannot fine-tune the base model, either because they rely on closed APIs or because their regulated customers dislike model customization.
What should you do before shipping DivInit?
Start with an audit, not a rewrite. Pull a sample of production questions, run your current parallel agent with k equal to 4 or k equal to 8, and compare the first query strings before you look at final answers. If the first-turn overlap is high, DivInit deserves a sprint.
The first experiment is cheap. Recreate the authors' setup in miniature: generate 16 candidate first queries, pick 4 with max-min Jaccard, and run your existing agent loop unchanged. The repository exposes conditions named diversity_parallel, naive_parallel, and sequential, which is the evaluation split you want inside your own harness.
Do not overfit to pass@4. In customer-facing products, you may care more about calibrated refusal, source coverage, latency, or support-ticket reduction. A 7.4 point pass@4 gain on Qwen3-8B multi-hop QA is exciting, but your procurement-search agent may be judged by whether it finds the one buried PDF clause.
The main caveats are straightforward. The paper is an arXiv preprint that the authors list as under review at EMNLP 2026. The code repository had one public GitHub star when accessed through GitHub's page, which means the implementation has not yet had the kind of community pounding that exposes edge cases.
A sensible shipping path looks like this:
- Add a first-query diversity dashboard before changing prompts.
- Run DivInit beside your current parallel agent on a fixed evaluation set.
- Measure answer quality, unique source coverage, retrieval spend, and p95 latency.
- Keep the winner per domain, because support search and open-web research may behave differently.
The bet to make: first-query selection becomes a standard knob in serious agent frameworks. The bet to avoid: every agent gets better just because its first queries look different. Diversity without competence gives you more ways to be wrong.
The first query is a product decision
Agent teams love to talk about planners, memories, verifiers, and orchestration graphs. DivInit is a reminder that the boring first tool call can dominate the rest of the run.
If the first query anchors the trajectory, then initialization is not a prompt flourish. It is part of the retrieval policy, the cost policy, and the product policy. Spend it like it matters.
Sources
- arXiv: Beyond Parallel Sampling: Diverse Query Initialization for Agentic Search
- GitHub: cxcscmu/diverse-query-initialization
- arXiv: Self-Consistency Improves Chain of Thought Reasoning in Language Models
- arXiv: ReAct: Synergizing Reasoning and Acting in Language Models
- Qwen: Qwen3: Think Deeper, Act Faster
- Google: Gemma 3: Google’s new open model based on Gemini 2.0


