A model that can finish a proof is useful. A model that can tell whether the last message moved the proof forward, introduced a mistake, or repaired someone else’s mistake is a different animal.
CrowdMath is a new test for that second animal.
CrowdMath, a paper submitted to arXiv on June 2, 2026, introduces a dataset of 164 expert annotated progress chains from the MIT PRIMES and Art of Problem Solving CrowdMath program. The primary keyword here is CrowdMath, and the key number is not the dataset size. It is the gap: models hit 83 to 88 percent accuracy when asked to predict the next post in a mathematical discussion, but the best model reaches only 0.42 macro F1 when asked to classify what role a post plays in the evolving proof, according to the CrowdMath arXiv paper.
That is a clean cut through a messy claim. The industry likes to say models are getting better at reasoning. Often, that means they can solve a packaged problem with a final answer. CrowdMath asks a more product relevant question: can an AI system read a live, unfinished intellectual process and understand what just happened?
If you are building agents for code review, research assistance, legal drafting, data analysis, or operations, this matters more than another benchmark score on a polished exam. Your users do not hand agents pristine theorem statements all day. They hand them Slack threads, half wrong tickets, pull requests with stale assumptions, and meeting notes where the important thing is buried in message 47.
The CrowdMath result says today’s models can follow the rhythm. They are still weak at judging the work.
What did CrowdMath actually measure?
CrowdMath is built from discussions in the MIT PRIMES and AoPS CrowdMath program, which began in 2016 as an online collaborative math research effort for advanced high school students. MIT PRIMES describes CrowdMath as a joint initiative with Art of Problem Solving that gives students around the world a year long collaborative research project in an online forum format, and says projects often result in research papers through the program FAQ.
The new dataset turns that history into an AI evaluation. Each of the 164 chains traces a multi participant discussion from an open problem statement to a completed proof. The authors label posts by function: partial progress, proof completion, erroneous reasoning, error identification, and related roles. This is not just another pile of math questions. It is a record of how a proof gets built in public, with wrong turns included.
That distinction is the whole story.
Most math benchmarks reward the final artifact. FrontierMath, for example, contains 350 original expert vetted problems, split into 300 problems in Tiers 1 to 3 and 50 in Tier 4, according to Epoch AI’s FrontierMath benchmark page. That kind of benchmark is valuable because it asks whether a model can solve hard problems. CrowdMath asks whether a model understands the social and logical process that produces a solution.
Here is the practical difference.
| Evaluation style | What it rewards | What it misses |
|---|---|---|
| Final answer benchmark | Getting the answer right | How the answer emerged |
| Complete proof benchmark | Producing a coherent proof | Whether intermediate work was useful or broken |
| CrowdMath style benchmark | Tracking progress through discussion | Broad coverage across all math domains |
The paper benchmarks 6 frontier models on two tasks. In next post prediction, models choose the likely next contribution in a discussion and score 83 to 88 percent accuracy. In post role classification, models identify the functional role of a contribution and the best score is only 0.42 macro F1.
The chart below shows the uncomfortable part: 88 percent can coexist with 42 percent when the easier task is local continuation and the harder task is role judgment.
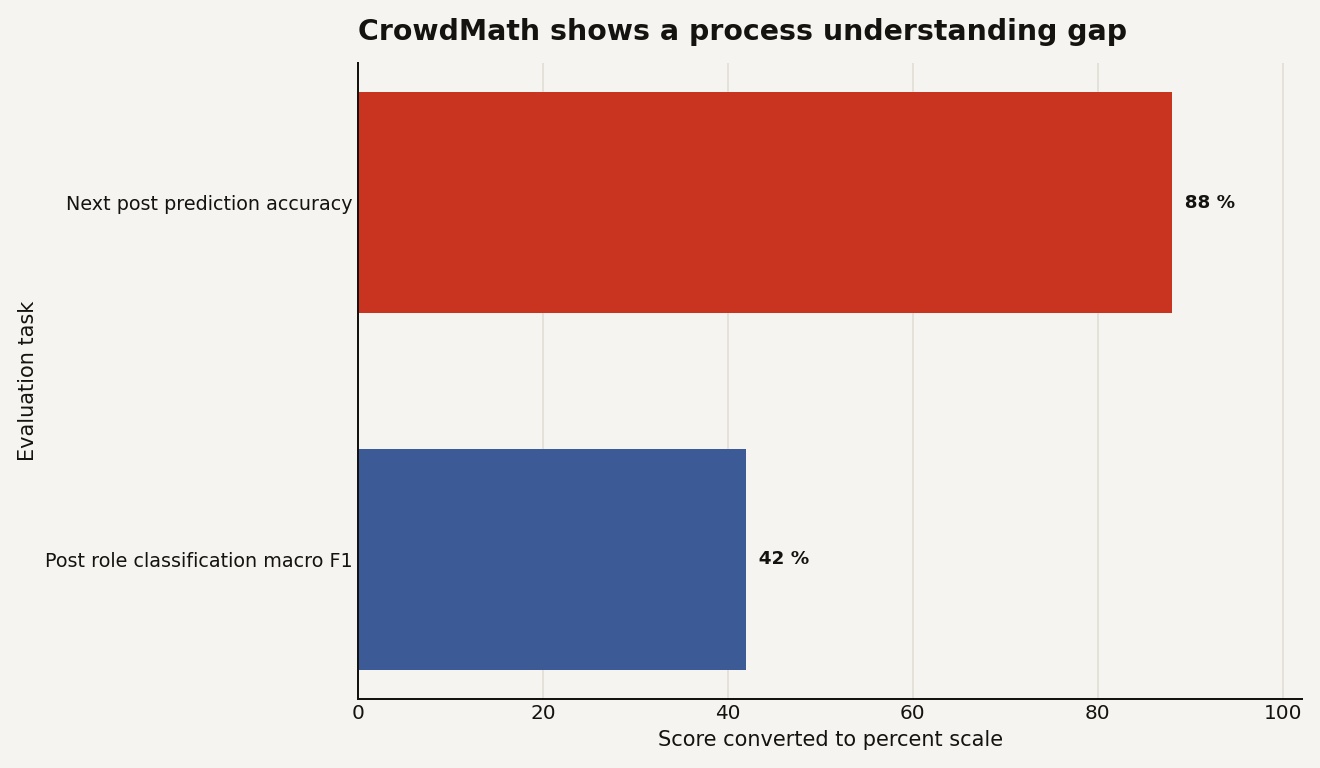
That gap is the point. Predicting what comes next in a thread is closer to reading the surface flow. Classifying whether a post completes a proof, spots an error, or merely nudges a partial argument requires a model of usefulness.
Why is 88 percent accuracy still not enough?
The 88 percent result sounds strong until you ask what it buys you. Next post prediction is a recognition task. A model can use local cues, style, notation, topic continuity, and the shape of forum conversation. That is useful, but it is not the same as knowing which post changed the state of the proof.
Post role classification is harder because it asks for judgment under uncertainty. If a student proposes a lemma, it might be a dead end, a key partial result, or a flawed bridge that someone else later repairs. The right label depends on how the discussion evolves. In production language, CrowdMath is testing whether the model can maintain a live state machine of an intellectual project.
A 0.42 macro F1 score is not a small rounding error. Macro F1 gives each class weight, so weak performance on rare but important roles hurts. That matters because rare roles are often exactly what you want an assistant to catch. In a math thread, error identification may be rare. In a code review, the analogous event is the one comment that prevents an outage.
This is why the benchmark feels more relevant than its narrow domain suggests. Replace theorem posts with engineering artifacts:
- A bug report thread with 23 comments.
- A pull request where an early reviewer is confidently wrong.
- A product spec where one late constraint invalidates the first architecture.
- A research notebook where a failed experiment teaches more than the successful run.
The agent’s job is not to autocomplete the next comment. The job is to know which comment matters.
Data Today has covered a similar evaluation trap in agent safety, where attack selection made systems look safer than they were. The lesson from that safety benchmark failure applies here too: if your test rewards the wrong behavior, your dashboard gets prettier while your product gets riskier.
CrowdMath’s underrated contribution is that it treats reasoning as process supervision. It asks whether models can read the difference between motion and progress. Builders should care because most useful AI work happens in the middle, not at the final answer.
Why should builders care about a math forum dataset?
Because your agent roadmap is probably drifting toward collaborative work, even if you do not call it that.
The first wave of LLM products answered questions. The second wave drafted artifacts. The current wave is being asked to sit inside workflows: review code, triage incidents, inspect contracts, generate analyses, coordinate subagents, and keep track of long running goals. That shift makes process understanding a core capability, not a research luxury.
CrowdMath gives you a sharper way to think about failures. If an agent reads a 90 message incident channel and writes a plausible summary, that may be next post prediction in disguise. It learned the flow. The harder test is whether it can say which message introduced the key diagnosis, which one was a false lead, and which one should change the remediation plan.
For a builder, the consequences are concrete:
- Codebase: do not trust an agent just because it can generate a passing patch. Test whether it can identify the comment or commit that invalidated the old approach.
- Roadmap: if you are selling “AI research assistant” or “AI analyst,” add role labeling and contribution tracking to your evals before adding another chat feature.
- Costs: long context alone will not fix this. A 200,000 token window can preserve the transcript while still failing to understand which turns mattered.
- Hiring: teams need evaluation engineers who can label process, not only prompt engineers who can coax polished outputs.
- Moat: domain specific process data becomes more valuable than generic Q&A data because it captures how experts move from wrong to right.
The business point is blunt: if your product claims to help experts think, the model has to understand partial progress. That is different from producing fluent final answers.
This is also where small datasets can matter. CrowdMath has 164 chains, not millions of examples. But each chain is dense. It contains errors, repairs, dependencies, and eventual proof completion. For evaluation, that structure can be more valuable than another mountain of solved exercises scraped from the web.
There is a caveat. CrowdMath is math. Mathematical forums have explicit notation, relatively strong norms, and a truth target. Enterprise work is messier. A sales strategy thread does not end in a proof. A compliance review may have several acceptable resolutions. Still, math is a good stress test because the roles are crisp enough to label. If a model cannot separate progress from error in a proof discussion, do not assume it can do it inside your 37 tab product planning mess.
How should you test agents after CrowdMath?
Start by stealing the shape of the benchmark, not the domain.
You do not need a mathematical research dataset to apply the lesson. You need transcripts where work unfolded over time and the final outcome is known. Then label the steps that changed the state of the work. A small internal benchmark with 50 examples can expose more than a broad public score if the examples match your actual product risk.
For software teams, that might mean closed GitHub issues, incident retrospectives, failed migrations, or design review threads. For data teams, it might mean analysis notebooks where the first 3 hypotheses were wrong. For customer support, it might mean escalations where a single message revealed the real bug.
The minimum useful eval has 4 labels:
- Partial progress: a step that moves the task forward but does not finish it.
- Completion: a step that resolves the task or locks the final answer.
- Error: a step that introduces a wrong assumption, wrong calculation, or bad plan.
- Error identification: a step that catches or corrects a previous mistake.
Then ask 2 questions. First, can the model predict or generate the next reasonable step? Second, can it label the role of each step after reading the full thread? CrowdMath suggests those scores may diverge sharply. If they do, believe the worse number.
There is a product design implication here too. Agents should expose their state of belief. A useful research or coding assistant should be able to maintain a ledger: open claims, accepted claims, rejected claims, unresolved gaps, and dependency links. Without that ledger, the agent may sound coherent while losing the proof.
A simple version looks like this:
- Extract claims from the thread.
- Link each claim to supporting or contradicting messages.
- Mark each claim as open, supported, contradicted, or resolved.
- Ask the model to justify any state change with message IDs.
- Score the state changes, not just the final summary.
That is less glamorous than “agentic reasoning,” but it is closer to what users need. If you are building an AI teammate, make it accountable for the work history.
What should happen next for CrowdMath and process benchmarks?
The next step is scale, but not sloppy scale.
The CrowdMath paper is a 16 page first release, with 4 figures and a focused benchmark. The right follow up is not to inflate 164 chains into a giant noisy corpus. It is to build adjacent process datasets where expert work is visible and outcomes can be audited. Math is one domain. Code review, science, law, medicine, and security response all have versions of the same structure.
The hard part will be annotation. Role labels require domain expertise. A crowdworker can often judge whether a final answer matches a key. They usually cannot tell whether a lemma is the moment a proof turns. That makes these datasets expensive, but it also makes them valuable. Scarce evaluation data is a moat for teams that collect it honestly.
There are 3 open questions worth watching after June 2026:
- Can models improve role classification with tool use, retrieval, or explicit claim graphs, or is this mainly a training data gap?
- Do models fail because they do not understand the math, or because they do not track long horizon contribution state?
- Will process labels transfer across domains, from proofs to code reviews to incident response?
The strongest near term bet is not “AI mathematician replaces mathematician.” The stronger bet is “AI assistant gets better when it can mark which human contribution mattered.” CrowdMath points toward evaluators that score judgment inside the conversation, not just polish at the end.
That is where builders should aim. Stop asking only whether the model can produce the answer. Ask whether it can tell when the group got closer.