Hospital AI has a boring problem that keeps beating clever demos: the answer lives across a discharge summary, three radiology reports, two dates that almost match, and a lab value nobody tagged correctly.
Agentic clinical RAG is starting to look useful precisely because it accepts that mess. In a new University Medicine Essen study, the ACIE system reached 96.5 percent clinician acceptance across 7,326 extraction judgments in a retrospective lymphoma registry workflow, according to the arXiv paper by Osman Alperen Çinar-Koraş and coauthors. The paper is a preprint, not a regulatory green light. Still, it is one of the more useful recent signals for builders because the result came from physicians checking cited source passages, not from a leaderboard that rewards fluent guesses.
The keyword is agentic clinical RAG, but the important noun is clinical. A generic retrieval app can survive a bad citation. A registry workflow cannot. If you are building around patient records, the product question is no longer whether the model can produce a plausible answer. The question is whether a busy expert can audit the answer fast enough to trust it.
What did the ACIE paper actually test?
ACIE stands for Agentic Clinical Information Extraction. The authors describe it as an on-premise pipeline at University Medicine Essen that reasons over complete patient contexts and grounds every answer in source passages for clinician verification, as stated in the paper abstract. That detail matters because health systems do not buy chatbots. They buy workflow compression with an audit trail.
The evaluation sits beside an independent retrospective lymphoma registry study. Nuclear medicine physicians verified each extracted value against the cited evidence, and the system accumulated 7,326 judgments in that review process, according to the same arXiv record. Across those judgments, clinicians accepted 96.5 percent of extractions. The per-type acceptance range ran from 80 percent to 99 percent, which is the small crack in the headline number that a builder should stare at.
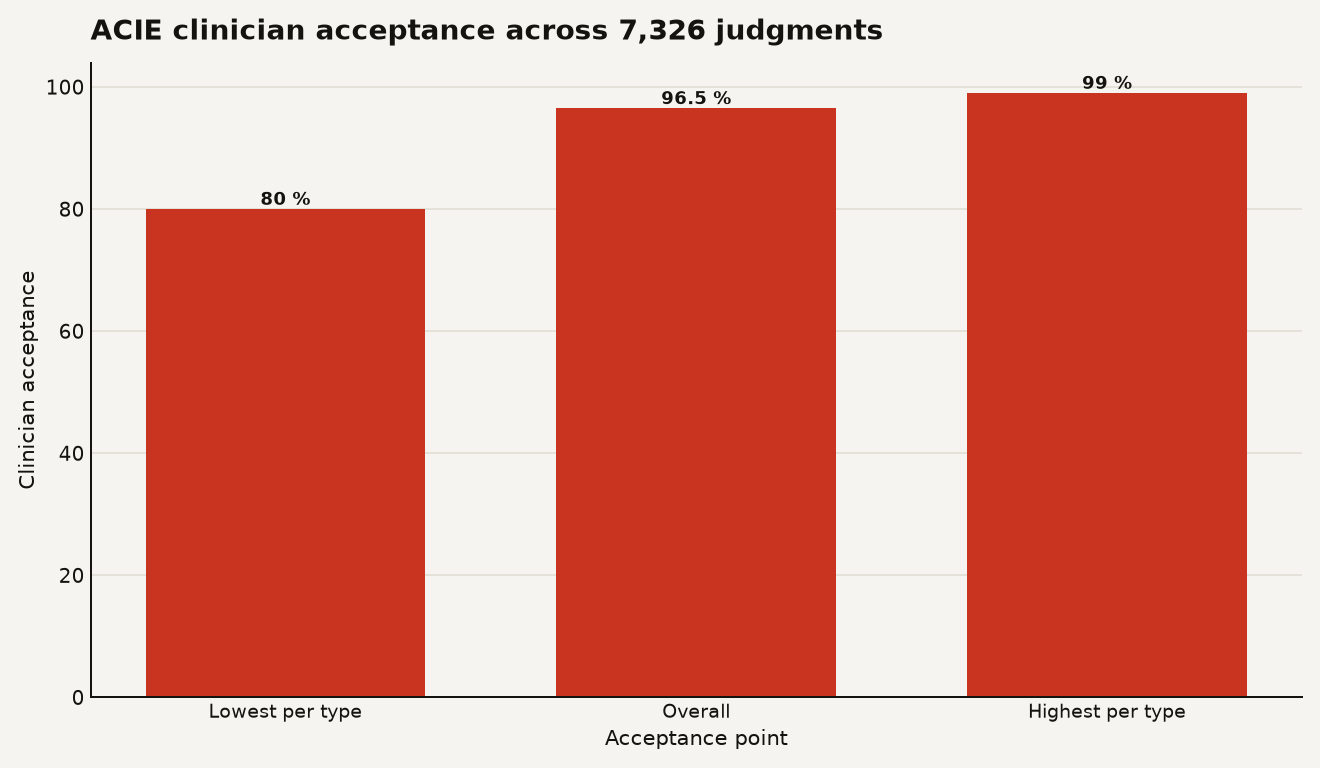
The chart shows the useful shape of the result: 80 percent at the lowest reported extraction type, 96.5 percent overall, and 99 percent at the highest reported extraction type. That spread says ACIE is strong in aggregate, while some clinical fields still punish the system. In medicine, the tail often writes the incident report.
The study also argues that standard retrieval-augmented generation fails on this kind of data because patient contexts span hundreds of heterogeneous documents and thousands of structured data points, while key metadata can be absent or incomplete, according to the authors' abstract. That is a familiar failure mode if you have tried to retrieve over EHR exports: document titles lie, dates drift, and the most important sentence may be a negated finding buried in a scanned note.
This is why the paper lands differently from another agent benchmark. In our coverage of the workplace reliability gap for agents, the lesson was that multi-step systems need testable work products. ACIE pushes that lesson into a higher-risk domain: the work product is a clinical data point, and the test is whether a physician accepts the citation.
Why did ordinary RAG break on these patient records?
Ordinary RAG assumes the index contains enough metadata to fetch the right chunk. Clinical records often break that assumption before the model sees a token. A document may have no clean encounter date. A lab result may be structured, while the interpretation sits in prose. A staging detail may require combining a radiology report, a pathology note, and a later treatment plan.
The ACIE authors call out temporal reasoning, cross-document dependencies, and missing metadata as standard RAG failure points in patient contexts, and they make that critique in the opening abstract of the paper. For builders, that is the architecture note. The hard part is not vector search alone. The hard part is deciding which retrieval failures deserve another tool call, another query reformulation, or a human handoff.
Public clinical datasets show the scale of the text problem even before you reach a private hospital system. MIMIC-IV-Note contains 331,794 deidentified discharge summaries from 145,915 patients and 2,321,355 radiology reports from 237,427 patients, according to the PhysioNet dataset page. That is just one research dataset from one institution. A real deployment inherits local templates, local abbreviations, historical systems, and years of quiet schema compromise.
FHIR helps with the plumbing, but it does not magically make the note searchable in the way an extraction agent needs. HL7 says the FHIR R4 DocumentReference resource indexes a document, clinical note, or other binary object so it can be made available to a healthcare system, according to the official R4 specification. Indexing the object is table stakes. Understanding whether the fifth PET report supersedes the second PET report is the expensive part.
That is where agentic clinical RAG earns its keep. An agent can route between retrieval steps, structured data checks, document-level reasoning, and citation assembly. The boring implementation detail becomes the product: every extracted value needs a provenance chain short enough for a clinician to inspect.
Why should builders care about a 96.5 percent acceptance rate?
A 96.5 percent acceptance rate sounds close to done until you translate the miss rate into work. If 3.5 percent of 7,326 judgments were not accepted, that implies roughly 256 challenged extractions at this evaluation scale, using the paper's reported acceptance rate and judgment count from the arXiv abstract. That is acceptable if the system reduces hours of chart review and routes uncertain cases cleanly. It is dangerous if the UI hides the tail behind a green badge.
The business consequence is blunt: agentic clinical RAG should be priced, staffed, and monitored as review infrastructure, not as a replacement for clinical ownership. The first buyer is likely a registry, trial matching, quality abstraction, prior authorization, or cohort discovery team. Those teams already pay humans to read records. The wedge is a faster evidence trail.
For you, the builder, the lesson breaks into four product decisions:
- Design for verification first. The ACIE result is compelling because clinicians checked extracted values against cited passages across 7,326 judgments, according to the paper abstract. A citation panel is not a feature garnish. It is the review surface.
- Treat field types differently. A per-type range from 80 percent to 99 percent means one metric can hide brittle labels, as reported by the authors. Your roadmap should rank fields by clinical consequence, not by demo appeal.
- Keep deployment local when data demands it. The authors describe ACIE as on-premise at University Medicine Essen in the paper summary. That choice raises ops cost, but it matches the privacy and integration reality of hospital data.
- Instrument disagreement. A rejected extraction is product gold. It tells you which document class, time relation, note template, or schema hole needs a better tool.
Regulation makes the same point with less romance. The FDA says its September 2022 clinical decision support guidance explains which CDS functions can fall outside device regulation and which may remain medical devices, according to the FDA FAQ. If your extraction product starts steering diagnosis, triage, or treatment, you have crossed from productivity software into a different budget, timeline, and evidence burden.
What would you build differently after reading this paper?
Start with a field registry, not a general assistant. Define 20 to 50 target variables, the acceptable source types for each variable, and the exact rule for when the model must say it cannot extract. ACIE's strongest lesson is that configurability matters because clinical information extraction is a schema negotiation with reality.
A practical build plan would look like this:
- Map every target value to source evidence.
- Store document metadata separately from chunk embeddings.
- Add temporal normalization as its own service.
- Require the model to return value, confidence, source span, document ID, and extraction rationale.
- Log every clinician correction as a typed failure.
That plan sounds heavier than a vanilla RAG app because it is. The paper's on-premise deployment at University Medicine Essen, described in the arXiv abstract, points to a future where serious clinical AI resembles data engineering with a model inside. You will need connectors, observability, reviewer queues, permission boundaries, and data retention controls before the LLM prompt becomes interesting.
The FDA's August 2025 guidance on predetermined change control plans also nudges builders toward lifecycle thinking for AI-enabled devices, saying a PCCP should describe planned modifications, validation methods, and the impact of those modifications in a marketing submission for covered products, according to the FDA guidance page. Even if your tool stays outside device scope, the discipline is useful. If you change the retriever, the prompt, the model, or the extraction schema, you need to know which accepted fields move.
The underrated moat is integration memory. A hospital-specific note taxonomy, a mapping from document classes to trusted extraction fields, and a corpus of physician corrections become hard to copy. Model choice matters, but the local evidence graph becomes the asset.
What should we watch before calling this deployment-ready?
The caveats are the story. The ACIE paper is a June 2026 arXiv preprint, and arXiv lists version 1 as submitted on 17 June 2026 in the paper record. Peer review, external replication, and prospective workflow data still matter.
The evaluation is also retrospective and tied to a lymphoma registry workflow. That is useful because registries have clear variables and expert reviewers. It also narrows the claim. A system that extracts registry fields well may struggle with emergency triage, multi-disease medication reconciliation, or patient-facing summaries. Same hospital data swamp, different crocodiles.
Watch three follow-up numbers:
- Time saved per accepted extraction. A 96.5 percent acceptance rate means little if review time barely drops.
- Rejected extraction severity. A wrong date, wrong stage, and wrong treatment status do not carry the same risk.
- Cross-site performance. University Medicine Essen is one deployment context. Templates and documentation habits can change the retrieval problem overnight.
Also watch the lowest-performing field types. The reported floor of 80 percent per-type acceptance in the paper abstract should drive the next ablation study. Builders need to know whether those failures come from missing metadata, ambiguous documentation, extraction schema design, or model reasoning.
The moat is the evidence trail
Agentic clinical RAG will win hospital work only when it stops performing intelligence and starts shrinking audit time. ACIE's 96.5 percent clinician acceptance rate is promising because it points to that shape of product: configurable extraction, grounded answers, and a human reviewer who can see the evidence.
The sharp read is simple. The model is the least defensible part of the stack. The defensible part is the pipeline that knows where the answer came from, why it chose that passage, when to ask again, and when to get out of the clinician's way.
Sources
- arXiv: Configurable Clinical Information Extraction with Agentic RAG: What Works, What Breaks, and Why
- PhysioNet: MIMIC-IV-Note: Deidentified free-text clinical notes
- HL7: FHIR R4 DocumentReference
- FDA: Clinical Decision Support Software Frequently Asked Questions
- FDA: Predetermined Change Control Plan guidance for AI-enabled device software functions

