The fastest way to make an enterprise AI roadmap sound fake is to say “agents” three times and point at a chatbot. The fastest way to make it feel real is to put the model behind a managed cloud contract, a known identity plane, and enough inference hardware that multi-step work does not collapse the first time 500 employees use it at once.
That is the read on Claude on GB300. NVIDIA said on June 29, 2026 that Anthropic’s Claude models in Microsoft Foundry are generally available on Azure, running on NVIDIA GB300 Blackwell Ultra GPUs. The headline number is the rack: Microsoft’s ND GB300 v6 documentation describes an NVL72 domain with 72 Blackwell Ultra GPUs, 36 Grace CPUs, about 20 TB of HBM, and up to 1.44 exaFLOPS of FP4 Tensor Core performance.
For a builder, this is less about the badge on the GPU and more about where Claude now sits in the enterprise stack. Claude is no longer only a model your team calls from a separate vendor account. It can sit inside Microsoft Foundry, use Azure procurement, and run on the kind of rack-scale inference system that was built for long context, tool calls, and concurrent agent traffic.
What did Microsoft, Anthropic and NVIDIA actually ship?
NVIDIA’s announcement says Claude in Microsoft Foundry is hosted on Azure and accelerated by GB300 Blackwell Ultra systems with Quantum-X800 InfiniBand networking. That matters because Foundry is where many Azure customers already manage model deployment, app wiring, identity, evaluation, and governance.
Anthropic first put Claude into Microsoft Foundry in public preview in late 2025. Anthropic said on November 18, 2025 that Claude Sonnet 4.5, Haiku 4.5, and Opus 4.1 were available in Foundry via serverless deployment, with support for Microsoft Entra authentication and Azure billing. General availability on GB300 moves the same cloud-channel story onto newer infrastructure.
The business context is large enough to change procurement behavior. Microsoft, NVIDIA and Anthropic announced on November 18, 2025 that Anthropic committed to purchase $30 billion of Azure compute capacity and contract additional capacity up to one gigawatt. That number is the quiet part of the announcement. Availability follows the money.
There is also a product design signal here. NVIDIA says enterprises can use its Secure Agent Workspace Reference Design to run Claude agents in a governed environment where identity, network access, credentials, and runtime policy are controlled at the infrastructure level. The GPU rack gets the press release. The permission boundary decides whether your security team lets the agent touch production systems.
If you read our earlier coverage of agentic AI work moving from chat to delegation, this is the same story at a different layer. The model layer is getting pulled into the cloud control plane, because delegated work needs logs, roles, network rules, and kill switches.
How much bigger is the GB300 setup than the last rack?
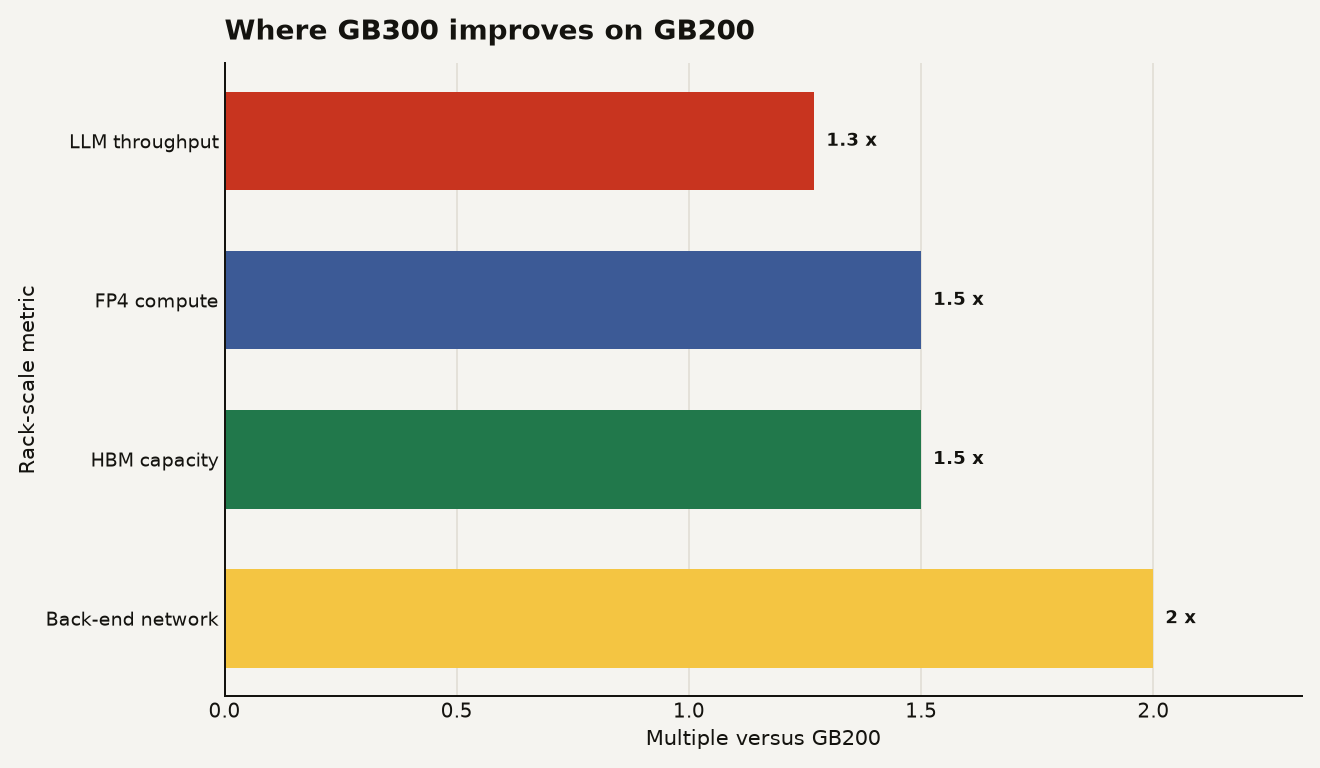
The useful comparison is GB300 against GB200, because both are NVIDIA rack-scale systems aimed at frontier inference. Microsoft says ND GB300 v6 delivers about 1.1 million tokens per second of LLM inference throughput per rack, about 27 percent higher than ND GB200 v6. The same Microsoft page says GB300 brings about 1.5 times FP4 compute, 50 percent higher HBM capacity, and 2 times the back-end network bandwidth per GPU compared with GB200.
The chart below shows the shape of the upgrade. Network bandwidth doubles, while throughput rises by a smaller 27 percent, which is a useful reminder that agent performance is usually gated by more than raw math.
The NVIDIA rack numbers explain why cloud providers care about this class of machine. NVIDIA’s Blackwell Ultra technical overview says a GB300 NVL72 connects 72 Blackwell Ultra GPUs and 36 Grace CPUs in a single NVLink domain with 130 TB per second of total NVLink bandwidth. For long-context and multi-agent systems, that shared domain can reduce the penalty of moving state, keys, values, and intermediate activations across a cluster.
This is where the agent story becomes technical rather than theatrical. A single request to a complex agent can trigger a planning call, retrieval, code execution, verification, tool retries, and a final synthesis. Multiply that by thousands of users and you get a traffic pattern that looks less like chat and more like a small distributed system having an argument with itself.
NVIDIA’s own framing points in that direction. NVIDIA says GB300 NVL72 provides 2 times higher attention-layer acceleration than Blackwell GPUs, a spec aimed squarely at reasoning and long-context workloads. Attention is where long prompts, large tool traces, and heavy retrieval contexts turn into latency and cost.
Why should an Azure builder care before the invoice arrives?
The first consequence is vendor consolidation. Anthropic’s Foundry launch note said developers could use Claude through Foundry APIs with Python, TypeScript, and C# SDKs, plus Microsoft Entra authentication. If your company already lives inside Azure, that trims a whole class of legal, billing, and IAM work.
The second consequence is model competition inside the same enterprise surface. Azure customers can now compare Claude against OpenAI, Mistral, and other Foundry models without rebuilding the whole app control plane. That makes model choice more operational and less ideological. Your eval harness matters more than your favorite lab.
The third consequence is cost opacity. Anthropic’s May 27, 2026 list price sheet lists Claude Sonnet 4.6 on Microsoft Foundry at $3 per million input tokens and $15 per million output tokens. The same sheet lists Claude Opus 4.8 on Microsoft Foundry at $5 per million input tokens and $25 per million output tokens. Those token prices are visible. The architectural cost of runaway tool loops, duplicate retrieval, oversized context, and failed retries is your problem.
What this means for you:
- Your agent budget needs a token governor, because a 10-step workflow can become 30 model calls once retries, validators, and sub-agents enter the graph.
- Your roadmap should separate latency-sensitive work from batch work, because the hardware is optimized for throughput, but users still judge the product by the slowest visible step.
- Your moat moves toward workflow data and control planes, because Foundry makes frontier models easier to swap, while your permissions, evals, tools, and domain traces stay harder to copy.
- Your hiring bar changes, because a production agent team needs infrastructure judgment, not just prompt taste.
The underrated detail is identity. If Claude agents run under Entra, network policy, and managed Azure services, developers can stop building a parallel authorization universe around every agent. That does not make agents safe by default. It gives your security team a place to enforce policy that already exists.
What should you change in your agent roadmap this quarter?
Start by treating GB300 capacity as a reason to raise your reliability bar, rather than a license to create more flamboyant demos. Microsoft says each ND-GB300-v6 VM exposes 4 Blackwell B300 GPUs and 4 times 1.8 TB per second of NVLink bandwidth. That is plenty of hardware to hide bad orchestration until the monthly bill arrives.
A sensible Azure-native plan has three parts.
First, build an eval harness that prices every step. Measure successful task completion, total tokens, wall-clock latency, tool calls, retry count, and human handoff rate. If your agent cannot beat a human process on at least two of those numbers, faster GPUs only help you lose money with nicer charts.
Second, design for model routing from day one. Use Haiku-class models for classification, formatting, and short tool selection. Use Sonnet-class models for coding, planning, and multi-step office work. Reserve Opus-class models for expensive judgment calls where quality clears the price. Anthropic’s Foundry pricing sheet lists Haiku 4.5 output on Microsoft Foundry at $5 per million tokens, Sonnet 4.6 output at $15, and Opus 4.8 output at $25.
Third, keep your abstraction boring. Wrap Foundry calls behind a small internal service that handles budgets, traces, redaction, routing, and fallbacks. The team that lets every product squad wire agents directly into vendor SDKs will spend 2027 debugging five different cost controls and nine different logging formats.
The near-term bet is simple: put one high-friction workflow on Claude in Foundry, require measurable throughput or quality gains, and refuse to scale it until the eval dashboard survives real users. The boring dashboard is the adult in the room.
What could still break the promise?
Availability is the first caveat. NVIDIA says Claude on GB300 in Azure is generally available, but capacity for frontier inference is still tied to regional rollout, quota, enterprise contracts, and the cloud provider’s own priority queue. General availability means you can start the procurement conversation with more confidence. It does not mean every team gets a rack slice tomorrow.
The second caveat is governance drift. NVIDIA’s post mentions governed agent execution through Secure Agent Workspace, but production safety still depends on how your team scopes credentials, logs tool actions, and handles rollback. A model with better attention acceleration can still delete the wrong record if your agent owns the wrong permission.
The third caveat is concentration risk. Microsoft, NVIDIA and Anthropic’s strategic partnership ties model access, cloud capacity, and GPU architecture into one large commercial loop. That can make deployment easier for Azure customers. It can also make your AI roadmap more sensitive to one cloud’s pricing, quota rules, and preferred hardware path.
This is why the right abstraction is both technical and commercial. Keep your prompts, evals, tool schemas, and audit logs portable even if your first serious deployment lives in Microsoft Foundry. The cloud should win your workload because it performs, not because your codebase cannot leave.
Bigger iron raises the floor
Claude on GB300 gives Azure teams a stronger default path for enterprise agents: serious GPUs, familiar cloud controls, and a model line already popular with developers. That raises the floor for what a responsible agent pilot can look like in 2026.
The ceiling still belongs to teams that measure the work. If your agent saves hours, reduces errors, and respects permissions, GB300 makes that value easier to serve. If your agent is a loop with a badge, the new rack will only make the loop more expensive.
Sources
- NVIDIA Blog: Claude Meets Blackwell Ultra: Anthropic’s Models Now Run on NVIDIA GB300 in Azure
- Microsoft Blog: Microsoft, NVIDIA and Anthropic announce strategic partnerships
- Microsoft Learn: ND GB300 v6 sizes series
- NVIDIA Technical Blog: NVIDIA Blackwell Ultra for the era of AI reasoning
- NVIDIA: GB300 NVL72 product page
- Anthropic: Claude now available in Microsoft Foundry and Microsoft 365 Copilot
- Anthropic: Claude model pricing sheet, May 27, 2026