Every few months a frontier model ships, and within hours a familiar take trends: AI has hit a wall. The graphs are flattening, the scaling era is over, the magic is spent. That take has been the losing trade for three years straight, and it is worth pulling apart, because the AI plateau so many people feel is real in one narrow way and an illusion in every way that matters.
The story did not come from nowhere. Through 2023 and 2024 the simplest recipe in the field, take last year's model and make it bigger on more data, started returning less per dollar. OpenAI's rumoured next base model, "Orion", reportedly underwhelmed its own team, and labs quietly stopped boasting about parameter counts. That part is true. The single lever that carried GPT-2 to GPT-4, raw pretraining scale, did flatten, and it is the exact lever the scaling-curve piece warned nobody should extrapolate forever.
Then look at what shipped on June 9, 2026. Claude Fable 5, Anthropic's new flagship, ran a codebase-wide migration across a 50-million-line Ruby codebase in a single day, work a human team would have measured in months. That is not the output of a field that stalled in 2024. The gap between the vibe and the benchmark is the whole story.
So has AI plateaued, or just the benchmarks?
The honest answer starts with a measurement problem. The benchmarks that built the plateau narrative are the ones everyone has watched for years: MMLU for broad knowledge, GSM8K for grade-school math, HumanEval for code. All three now sit jammed against their own ceiling. Top models score about 92 percent on MMLU, 97 percent on GSM8K, and 94 percent on HumanEval, and human experts manage only around 90 percent on MMLU. A line that climbs from 60 to 92 and then inches to 94 looks exactly like a plateau. It is a test running out of questions a frontier model gets wrong.
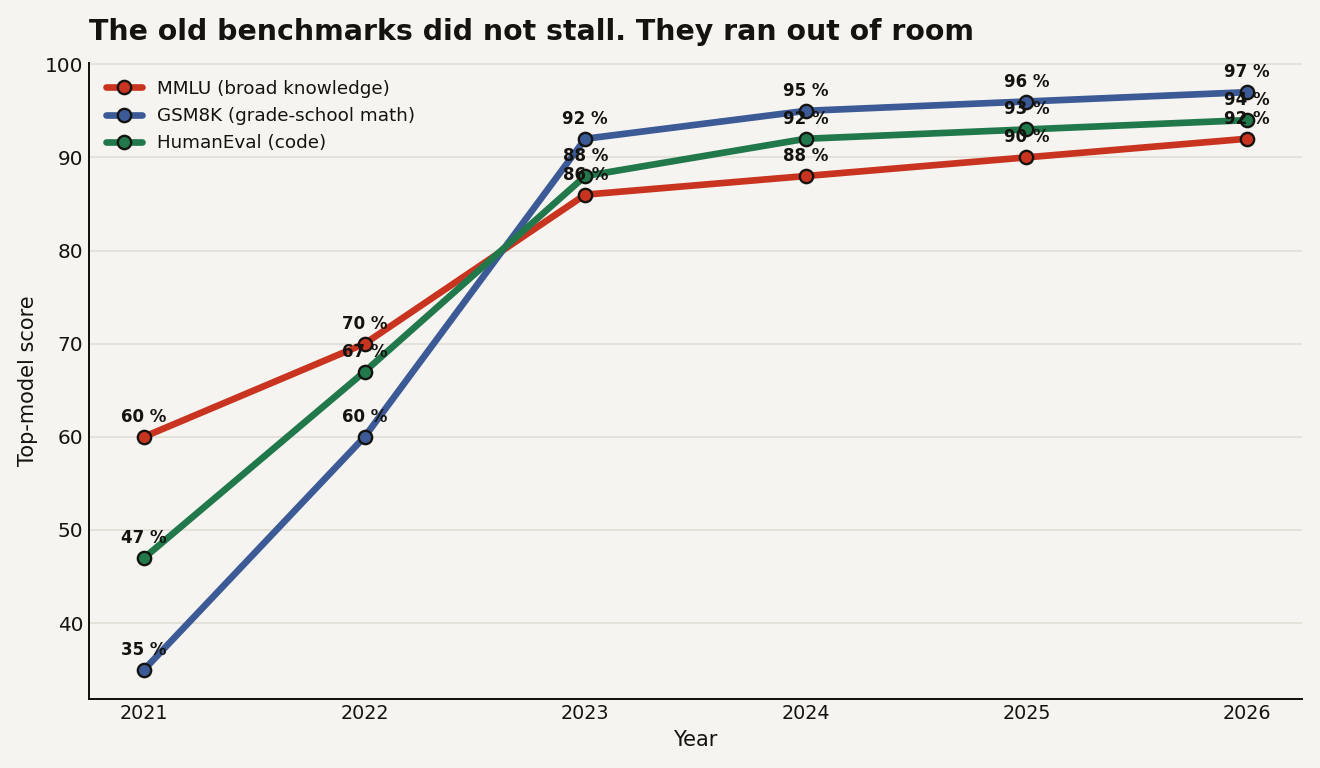
A score cannot exceed 100, so every benchmark flattens eventually no matter how fast the model behind it improves. Reading "the curve is bending" off a saturated test measures the ruler, not the thing being measured. This is the same compression described in the tightening-leaderboard piece: once every model clusters near the top of a test, the test has stopped discriminating. The plateau lives in the benchmark's headroom, not in the model.
Then why does every release cycle feel like a letdown?
Because the target keeps moving, and almost nobody clocks it moving. "Artificial general intelligence" has never had a fixed definition, so in practice it gets pinned to whatever the best model still cannot do. Each time a model clears that bar, the bar relocates to the next unsolved task, and yesterday's milestone gets downgraded to "narrow" or "just pattern matching".
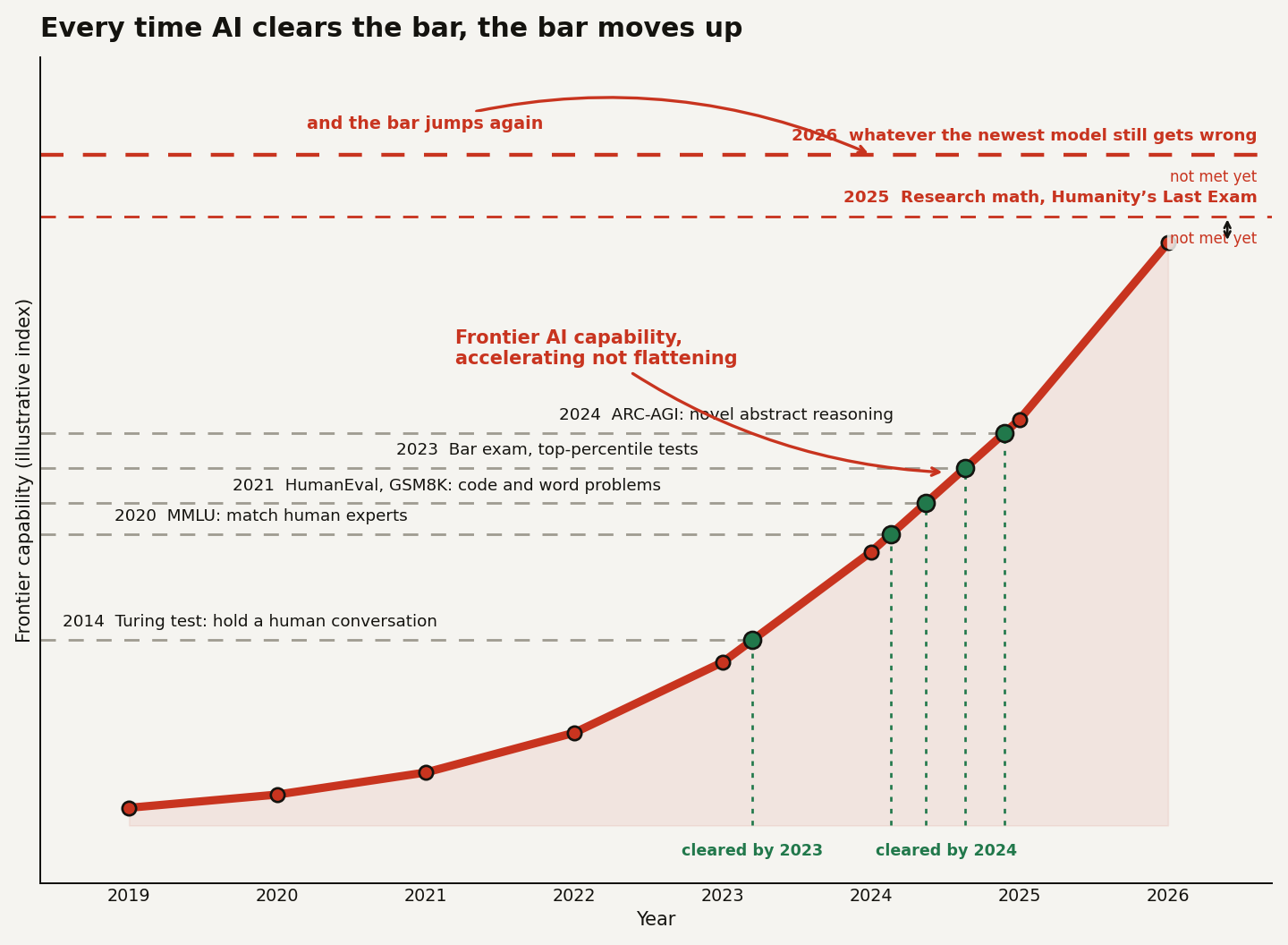
Laid out in order, the history is almost comic.
| Year set | The bar that meant "real" AI | When it fell |
|---|---|---|
| 2014 | Hold a convincing human conversation (Turing test) | Widely considered passed by 2023 |
| 2020 | Match human experts across MMLU | Cleared 2023 to 2024 |
| 2021 | Write working code, solve word problems (HumanEval, GSM8K) | Cleared by 2024 |
| 2023 | Pass the bar exam, top-percentile standardized tests | GPT-4 era |
| 2024 | Beat people at novel abstract reasoning (ARC-AGI) | Crossed December 2024 |
| 2025 | Solve research-grade math and Humanity's Last Exam | In progress, 2026 |
The Turing test was the gold standard for seventy years. The moment models began passing it convincingly, it was waved away as naive. ARC-AGI was built by François Chollet precisely as a test no language model could brute-force, and when OpenAI's o3 crossed the human-level threshold on it in December 2024, a harder ARC-AGI-2 arrived the next year. Every redefinition is defensible on its own. Stacked together, they trace a goalpost on wheels, which is exactly why the plateau keeps feeling true no matter how far the curve climbs.
Where is the real wall, then?
There is a real wall, and naming it precisely separates analysis from vibes. The wall is narrow: piling more parameters and more text onto a base model, with nothing else changed, stopped paying off around 2024. That one lever flattened, and the plateau crowd mistook one flat lever for the whole machine.
What they missed is that the field switched which lever it pulls. Instead of only scaling training, labs began scaling inference: letting a model think for longer, search, check its own work, and spend compute at the moment of answering. OpenAI's o1 and o3, DeepSeek's R1, and the reasoning modes inside Claude all run on that idea. A second scaling axis opened just as the first one tired, and the second one is nowhere near its ceiling.
The proof sits on the hard exams built with headroom to spare.
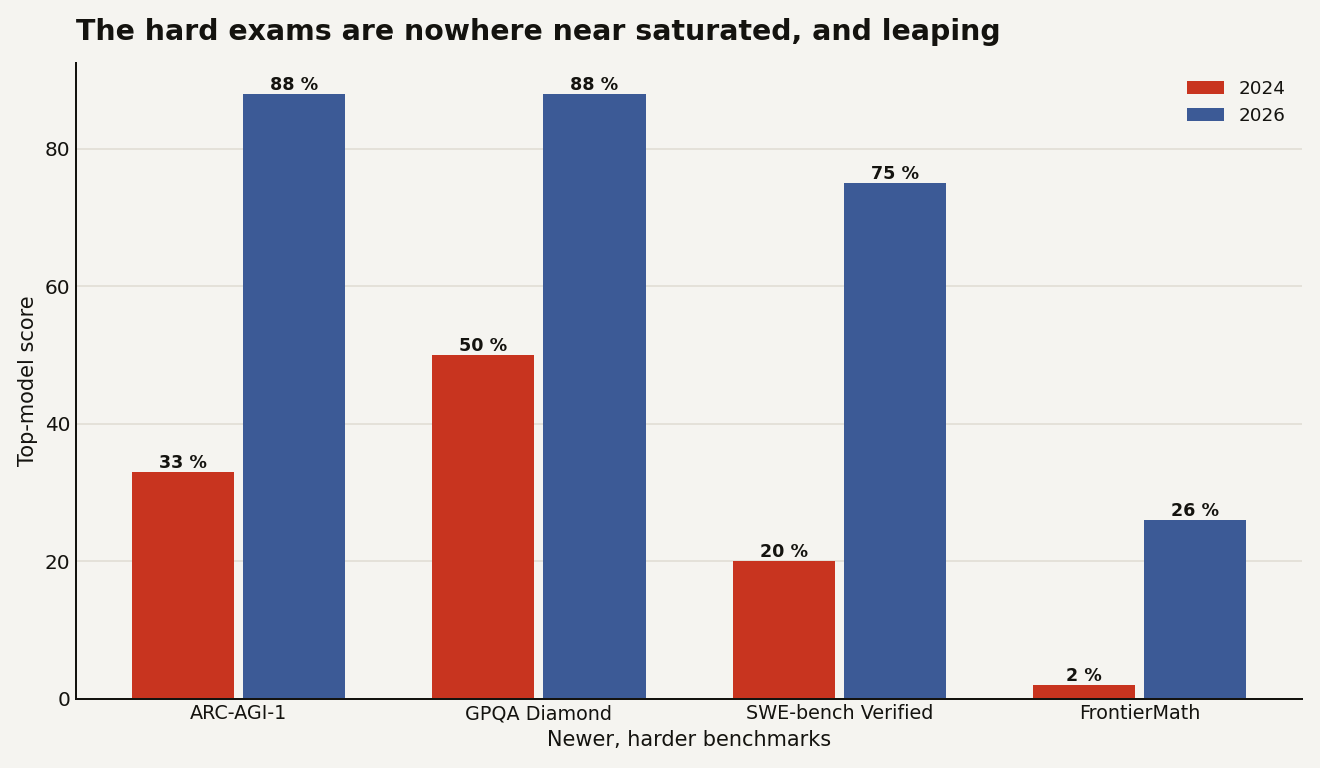
On ARC-AGI-1 the top score jumped from about 33 percent in 2024 to 88 percent in 2026. GPQA Diamond, a set of graduate-level science questions, climbed from roughly 50 to 88 percent. SWE-bench Verified, which checks whether a model can resolve real GitHub issues, went from about 20 to 75 percent. FrontierMath, a set of research-level problems that Fields medallist Terence Tao expected to resist machines for years, moved from about 2 to 26 percent. Not one of those is saturated, and all of them are moving fast, measured on tests chosen specifically because the old ones had gone soft. The acceleration tracked earlier this year shows up here as raw benchmark motion.
Are the open models plateauing too?
No, and this is where the plateau thesis fully gives way. If progress had genuinely stopped, open-weight models would have caught up and bunched against the same ceiling. Instead they are climbing the same hard exams, a step behind the closed frontier, on the same upward track.
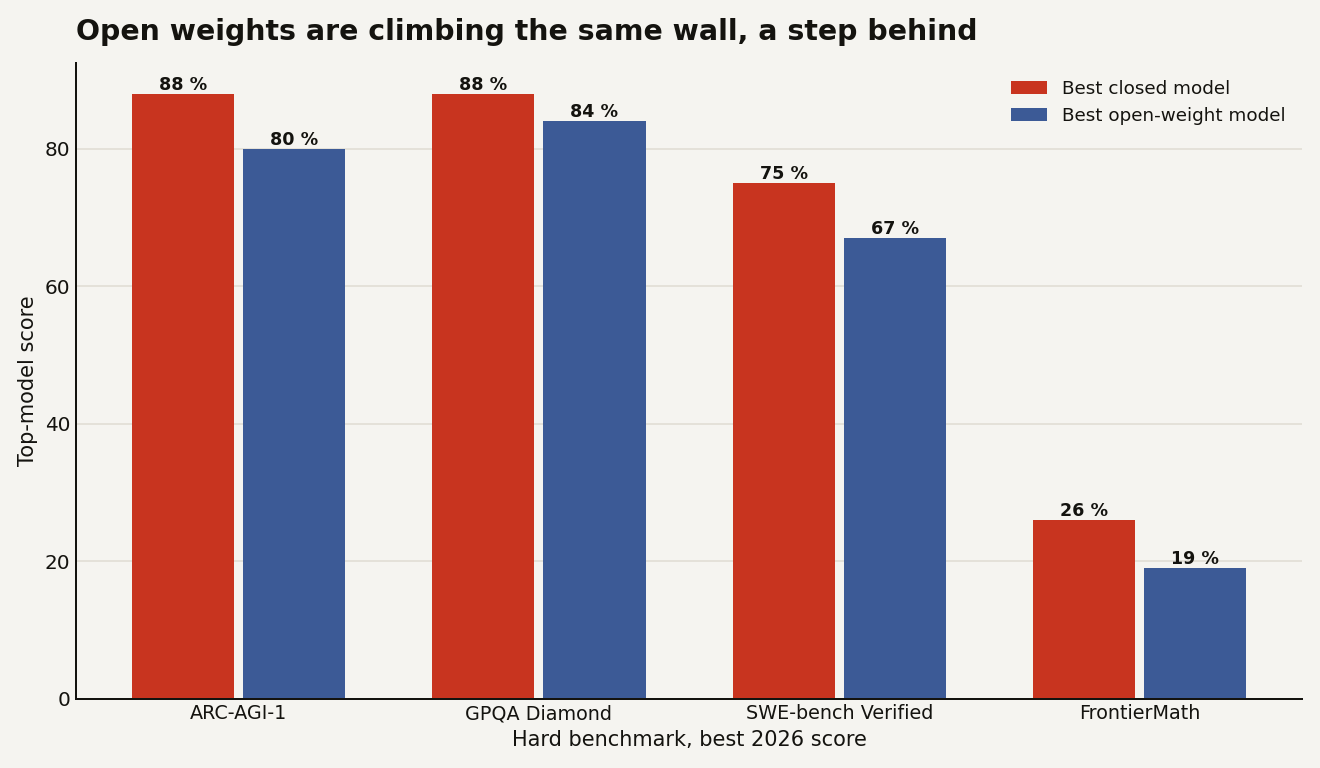
The strongest open-weight families, DeepSeek and Qwen among them, now post about 80 percent on ARC-AGI-1, 84 on GPQA, 67 on SWE-bench Verified, and 19 on FrontierMath, trailing the best closed model by a single-digit to low-double-digit margin. That gap matches what the open-weight parity piece found: under two points on the saturated tests, a handful of points on the hard ones. Two independent ecosystems racing up the same unsaturated curve is not the shape of a plateau. It is the shape of a competitive frontier.
So is anything actually plateauing?
Yes, and an honest read has to say so plainly. Several things really have stalled. None of them is the thing the plateau headline means.
- Embodied tasks. Steve Wozniak's old coffee test, walk into a stranger's kitchen and make a cup of coffee, is still unsolved. Robotics and physical manipulation trail the digital frontier by years.
- Reliability over long horizons. A model that migrates a 50-million-line codebase can still invent a citation or lose the plot on a multi-day job. Capability outran trustworthiness, which is the whole subject of the Fable 5 routing piece: the model that actually answers is now a runtime decision with its own failure modes.
- Cost. Fable 5 runs at $10 per million input tokens and $50 per million output, and Anthropic is rationing it, free on paid plans only through June 22 before usage credits bite. The binding constraint on frontier AI is the compute to serve it, not the supply of ideas.
- Genuine discovery. Acing a hard exam is not the same as proving a new theorem or designing a new drug. That bar is real, and it has not fallen.
Those are the plateaus worth watching, and every one of them is about deployment, trust, and economics rather than whether the models keep getting smarter on measurable work.
What should a builder take from this?
The practical read is that "AI has plateaued" is a planning error wearing the costume of an observation. A few consequences follow for anyone shipping on this stack.
- Saturated benchmarks are noise. A model at 94 on HumanEval is not meaningfully weaker than one at 95; the test cannot tell them apart. Signal now lives on hard, unsaturated benchmarks or on a private workload that mirrors the real job.
- Cost tracks capability now. Gains come from inference-time compute, so a smarter answer can mean a longer, pricier one. The cost curve and the capability curve are bound together in a way they never were in the pretraining years.
- A wall that is not there is a bad foundation. Products built on the premise that models will not get much better than today have lost that bet every year since 2023, and a faster second axis shortens the life of that assumption further.
- The real plateaus are the ones to design around: reliability, latency, cost per completed task, and anything that touches the physical world.
The kicker
The most-quoted chart in AI is a benchmark pinned to its ceiling, read out loud as proof the field is finished. The more honest chart is the other one, where the goalposts slide up the page while the capability curve climbs to meet them, year after year. AI is not plateauing. The word "AGI" is inflating, one cleared benchmark at a time, and on the day a model finally makes that cup of coffee, the bar will already have moved somewhere new.