Dataset: the benchmark gap charted here is drawn from Stanford HAI's 2025 AI Index, whose underlying data is free to download and reuse.
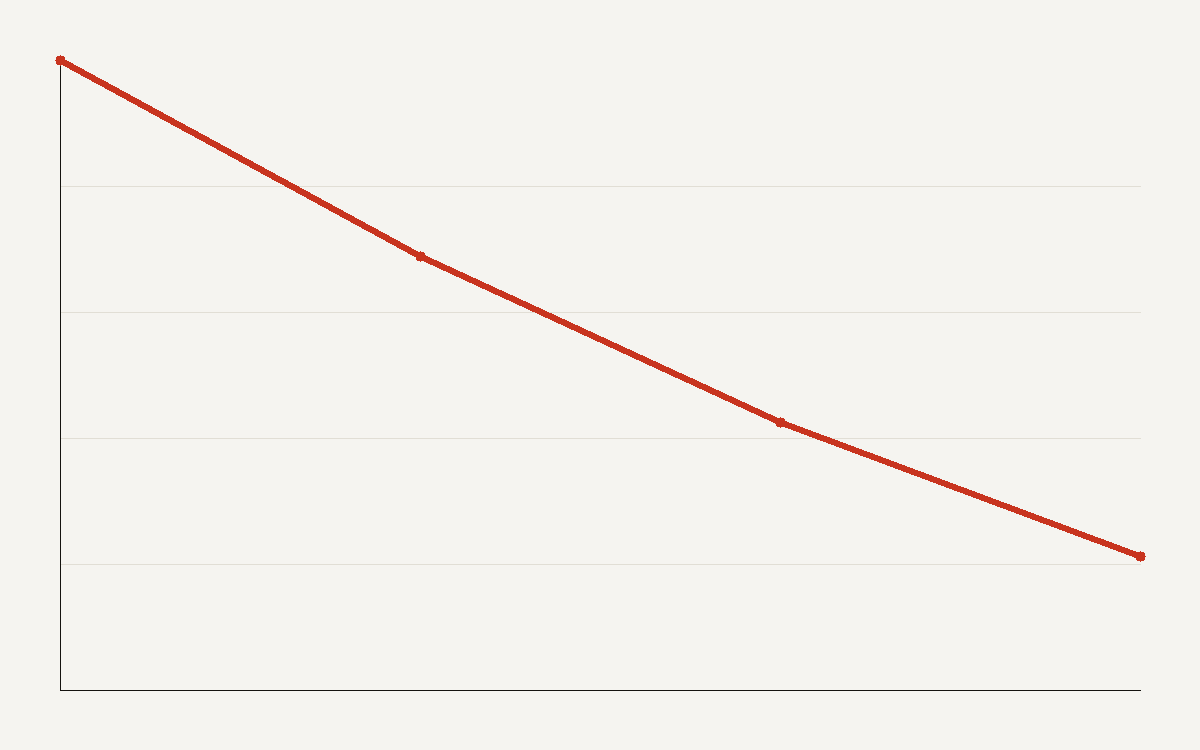
Open-weight models are no longer the cheap compromise. They are a default. On some benchmarks, the performance gap between the best open-weight model and the best closed model fell from 8% to 1.7% in a single year, according to Stanford's 2025 AI Index. The chart above traces that collapse.
Near parity changes the buying decision. When the capability difference is under two points, the reasons to hold the weights yourself become decisive: data residency, predictable cost, and the freedom to fine-tune on proprietary data without sending it to a vendor.
Why teams hold the weights
- Data residency rules rule out some hosted options entirely.
- Cost is predictable when you control the deployment, with no per-token surprise at the end of the month.
- Fine-tuning on private data is simpler when the model is yours.
import pandas as pd
df = pd.read_csv("deployments.csv") # month, license, count
share = (
df.groupby(["month", "license"])["count"].sum()
.groupby(level=0).apply(lambda s: s / s.sum())
)
print(share.unstack().tail())The competitive backdrop
This is the same crowding visible across the tightening leaderboard: when many models cluster near the top, license terms and running cost decide deployments more than raw capability. For organisations weighing the gigawatt-scale cost of frontier compute, an open model that runs on hardware you control is an easier line to defend.
Parity does not mean open models win everywhere. It means the burden of proof has flipped. The benchmark detail is in the 2025 AI Index.
Near parity changes the risk calculation
When open-weight models trailed by eight points, choosing them required a clear reason. The buyer accepted lower performance in exchange for control. At a gap of 1.7 points, the trade-off looks different. The hosted closed model may still win on some tasks, but the open option is close enough that governance, cost, and portability can decide the purchase.
That shift is especially important for regulated organizations. A bank, hospital, public agency, or defense contractor may value data control more than a small benchmark advantage. If the open model performs adequately on the organization's own test set, the ability to host it inside existing controls can outweigh the last point of public leaderboard performance.
Open weights also reduce vendor concentration. A team can fine-tune, evaluate, and serve a model without depending on one provider's roadmap or pricing. That does not make operation easy. It gives the buyer an exit path, which is often enough to improve contract terms with hosted vendors.
The hidden costs of owning the model
Open-weight does not mean free. Someone has to choose the model, provision hardware, monitor quality, apply safety controls, patch serving infrastructure, and manage upgrades. The per-token bill may be predictable, but the operational bill moves onto the buyer's own team.
The cost depends heavily on scale. A high-volume product can justify the fixed work because each additional request is cheaper. A small team with irregular usage may be better served by an API, even if the model itself is open. The right comparison is total cost of ownership, not license type alone.
There is also a quality-maintenance burden. Hosted providers update models, tools, and safety systems continuously. A self-hosted deployment can drift if it is not re-evaluated against new tasks and new competitors. Open weights give control, but control includes responsibility for keeping the system current.
What buyers should test
The practical test is a three-way comparison: best closed model, best open model hosted internally, and best open model through a managed provider. Score each on task quality, latency, cost, data handling, auditability, and upgrade path. The winner may differ by workflow.
Buyers should also test failure behavior. A model that is slightly weaker on an average score may be safer if its errors are easier to detect or if it refuses uncertain requests more predictably. For production systems, the shape of failure often matters more than the average gap.
The open-weight default is not an ideological claim. It is a procurement claim: when capability is close, control becomes valuable enough to lead the decision. The best closed models will still set the frontier, but many everyday deployments no longer need the frontier to create value.
Why the gap may keep tightening
Open models benefit from a broad ecosystem. Researchers publish techniques, developers optimize runtimes, hardware vendors tune kernels, and users report failure cases in public. Each improvement compounds outside one company's API. Closed labs still have advantages in capital, data, and frontier training runs, but the open ecosystem is fast at imitation and deployment.
The remaining gap may also matter less as tasks specialize. A general benchmark can show a closed model ahead overall while an open model wins on a narrow domain after fine-tuning. Companies do not buy general intelligence in the abstract. They buy performance on their own documents, customers, code, and operating constraints.
That is why the 1.7-point number is more than a scoreboard. It signals that the default question has changed from "why use open?" to "why give up control?" In many workflows, that is the question that procurement, security, and finance were already waiting to ask.
The answer will still vary by task. Closed frontier systems remain attractive when the last bit of quality, speed of new features, or managed safety layer is worth the premium. Open-weight systems lead when data control, predictable cost, and deployment flexibility matter more. A mature AI strategy should be able to use both without rebuilding the product around one vendor.
That mixed strategy is the practical meaning of open-weight parity. It gives buyers choice. Choice lowers lock-in, improves negotiation, and lets teams match the model to the risk of the work.