The standard post about today's launch writes itself: Anthropic shipped its most powerful model ever, here are the benchmarks, it crushes them. All true. Claude Fable 5 is state of the art on nearly everything Anthropic tested, and in one early trial it ran a codebase-wide migration on a 50-million-line Ruby codebase in a day that would have taken a team over two months by hand.
The more interesting fact is sitting in a footnote. Fable 5 and its sibling Claude Mythos 5 are the same underlying model. Same weights, same training, same capabilities. The only thing that separates them is a set of classifiers that sit in front of Fable and yank the steering wheel when you ask the wrong kind of question. Anthropic even says so in the naming: Fable comes from the Latin fabula, "that which is told," and the safeguards are the entire reason the two models have different names.
So the product that launched today is not really a model. It is a model plus a bouncer. And if you build on it, the bouncer is now part of your architecture whether you planned for it or not.
What actually shipped, and why now?
Back up to April 2026. Anthropic introduced its first "Mythos-class" model, Claude Mythos Preview, but it did not put it on the open API. It went out through Project Glasswing, a restricted program for cyber defenders and critical infrastructure providers, run in consultation with the US government. The stated reason was that a model this good at finding and exploiting software vulnerabilities is genuinely dangerous in the wrong hands. We covered the capability gap that started this fight in the Meta support-desk security piece.
Today's news is that Anthropic decided the guardrails are finally good enough to let the public near a Mythos-class model. That public version is Fable 5. The restricted version, with the cyber safeguards lifted, is Mythos 5, and it stays inside Glasswing plus a coming "trusted access" program for vetted security and biology organizations.
The mechanism is the part worth understanding. Fable 5 ships with a layer of classifiers, separate AI systems that watch every request. When a classifier decides your prompt touches cybersecurity, biology and chemistry, or model distillation, Fable does not refuse. It quietly hands the request to Anthropic's next-best model, Claude Opus 4.8, and tells you it did. Opus 4.8 is excellent, so the experience degrades gracefully instead of erroring out. But the frontier model you thought you were paying for just stepped out of the room.
How often does the bouncer actually intervene?
Rarely, if you are a normal user. Anthropic says the classifiers trigger on average in fewer than 5 percent of sessions, and that more than 95 percent of Fable sessions involve no fallback at all. For that 95 percent, the company says Fable 5 performs effectively the same as the unrestricted Mythos 5.
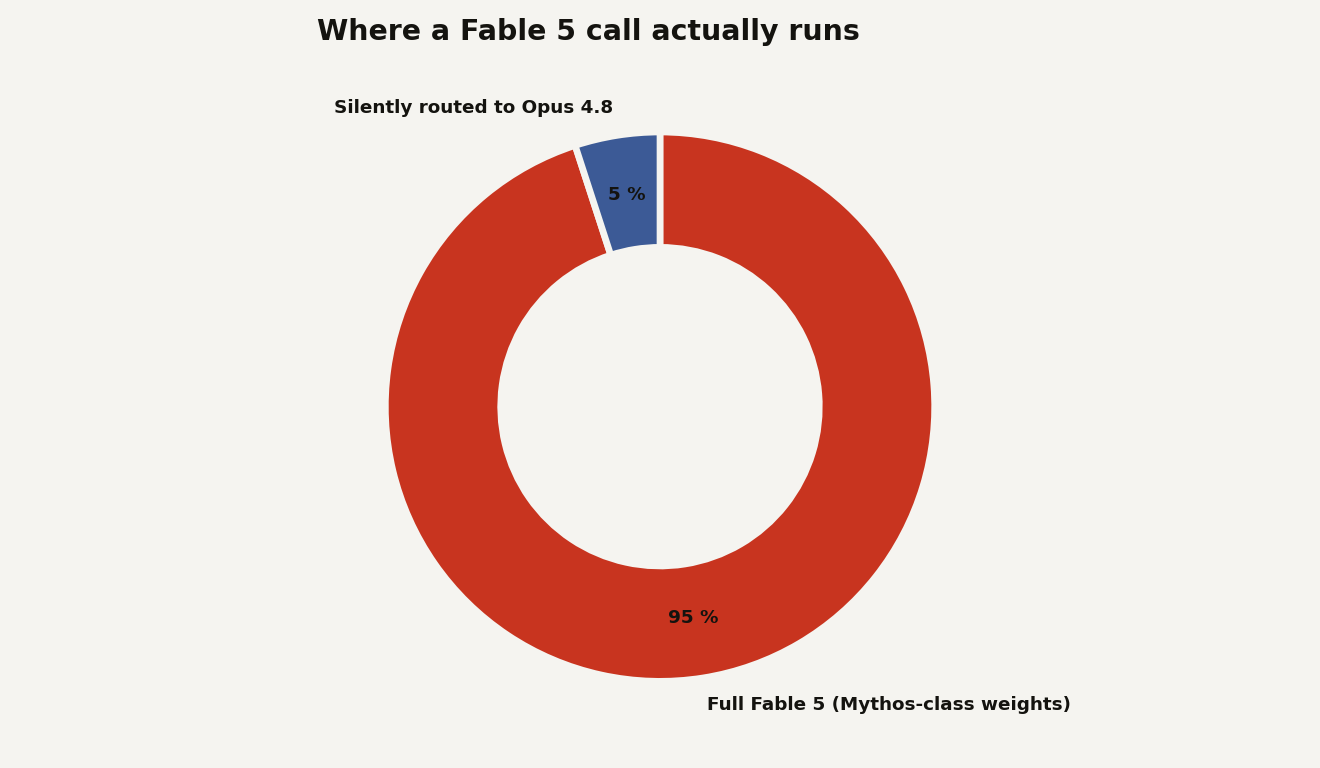
For a chatbot user, a 1-in-20 chance of a slightly weaker answer on a niche topic is nothing. For someone wiring Fable 5 into an automated pipeline, that same number reads very differently. It means the endpoint behind claude-fable-5 is not one model. It is a probabilistic mixture of two, and you do not control the mixing function. Anthropic's classifier does, and it can change after launch, because the company has openly said it tuned the safeguards conservatively and intends to loosen them over time.
That breaks an assumption a lot of teams quietly rely on: pin a model version and you get reproducible behavior. With Fable 5, the version is pinned but the model that answers is not. Two identical requests can be served by two different models on two different days, and the only signal is a flag in the response that your code has to actually read and handle.
What does this change for the thing you are building?
Treat the fallback as a first-class event, not an edge case. Here is the practical shift in mindset for builders and operators:
- Log which model answered, on every call. If you do not capture the fallback signal, your evals are measuring a blend you cannot reproduce, and a regression could just be Opus 4.8 quietly taking 5 percent of your traffic.
- Decide what a downgrade means for your task. A fallback on a marketing email is fine. A fallback in an agent that writes security-sensitive code, midway through a long-horizon task, is a different risk, and Fable 5's whole pitch is long-horizon autonomy.
- Expect false positives. Anthropic admits the classifiers will sometimes catch benign requests. Anything that smells of pentesting, malware analysis, lab protocols, or "how does this exploit work" is fallback bait, even for a legitimate defender.
- Budget for nondeterministic capability. Your worst-case quality is Opus 4.8, not Fable 5. Design and price the product around the floor, not the ceiling.
The table below is the mental model I would keep on a sticky note.
| Model | What you get | Who can use it | The catch |
|---|---|---|---|
| Fable 5 | Mythos-class weights, classifiers on | Everyone, via API and apps | Cyber, bio, and distillation prompts fall back to Opus 4.8 |
| Mythos 5 | Same weights, cyber safeguards lifted | Glasswing partners, vetted access only | Application and US-government-linked gating |
| Opus 4.8 | The previous flagship | Everyone | What you actually receive when Fable's classifier fires |
Who quietly gets the worse deal?
Here is the uncomfortable read. The people who most want a Mythos-class model are exactly the people whose every prompt trips the classifier. A security engineer doing real vulnerability research, a bioinformatics startup designing proteins, a red team writing exploit proofs: for them, the fallback rate is not 5 percent. It is closer to all of it. Off the shelf, what they can actually buy is Opus 4.8 wearing a Fable badge, unless they are admitted to the trusted access program that Anthropic, in consultation with the US government, controls the door to.
There is a second string attached that enterprise buyers should not skim past. Anthropic now requires 30-day data retention on all Mythos-class traffic, first-party and third-party, to help it catch novel jailbreaks. It promises not to train on that data and to delete it, but "we keep 30 days of your prompts" is a real change for anyone who chose Claude partly for zero-retention guarantees. The capability came with a surveillance term attached, and that term is the price of the safeguards working.
Then there is the money. Both models cost $10 per million input tokens and $50 per million output tokens, less than half what Mythos Preview cost. That looks like a price cut, and per token it is. But price per token is the wrong unit now. Early testers report Fable 5 finishing the same work in fewer turns, one cited a third of the reasoning tokens of a rival on a physics problem, another saw spreadsheet runs finish 25 to 30 percent faster. The number that is collapsing is cost per completed task, not cost per token, and that is the number that decides whether you can hand an agent a two-month job. We have tracked this gap before in the uneven inference-price piece.
One more tell hides in the availability section. Fable 5 is free on paid subscription plans only through June 22, then it gets pulled behind usage credits on June 23, with a vague promise to restore it "when sufficient capacity allows." Anthropic says demand is very high and hard to predict. Translation: the binding constraint on frontier AI right now is not the model, it is the compute to serve it. They built something they cannot yet afford to give everyone.
The kicker
For one launch, Anthropic turned safety into a SKU. Fable and Mythos are not two models, they are one model and a switch, and the switch is now a component in your stack with its own failure modes, its own false-positive rate, and its own data-retention bill. The benchmark numbers are the easy story. The harder and more useful one is that the model you call is no longer a fixed thing you bought. It is a routing decision someone else makes, 5 percent of the time, on your behalf.