A work assistant that can search your inbox is useful right up to the moment a link tells it to search your inbox for an attacker.
SearchLeak is a one-click Microsoft 365 Copilot exploit chain disclosed on June 15, 2026 by Varonis Threat Labs. The key number is one click: a victim could click a legitimate Microsoft 365 search URL, and Copilot Enterprise Search could be induced to pull sensitive data from emails, calendar items, SharePoint, and OneDrive, then leak it through a browser request.
The narrow bug is patched. The wider design problem is not patched by a CVE. Enterprise AI assistants collapse three things builders used to keep separate: search, identity, and action. When the same system reads untrusted text, interprets instructions, renders output, and can reach network endpoints, your old web security instincts still matter. They just fire in a stranger order.
What did SearchLeak actually chain together inside Copilot?
Varonis described SearchLeak as a three-stage vulnerability chain in Microsoft 365 Copilot Enterprise Search: Parameter-to-Prompt Injection, an HTML rendering race condition, and a Bing server-side request forgery path that bypassed the page’s content security policy. In plain English: the attacker put instructions in a URL parameter, Copilot treated those instructions as work to do, the browser briefly rendered attacker-shaped HTML before sanitization finished, and Bing became the network hop that made exfiltration possible. Varonis published the technical chain on June 15, 2026.
The entry point was the q parameter in a Microsoft 365 search URL. That parameter should behave like a search box. In Varonis’s proof of concept, it behaved like a prompt. A crafted link could tell Copilot to search the user’s emails, extract a title or other sensitive result, then place that data inside an image URL.
The second link is the one builders should stare at. Microsoft’s mitigation wrapped Copilot output in code blocks so the browser would treat generated HTML as text. Varonis found the wrapping happened after Copilot’s streaming phase. The browser did what browsers do: it saw an image tag and fired a request before the final sanitized response arrived.
The third link used Bing. Copilot’s content security policy allowed requests to Microsoft controlled domains, including Bing. Bing’s image search endpoint accepted a user supplied image URL, then fetched it server side. That meant a request could go from the victim’s browser to Bing, then from Bing to an attacker controlled server, with the stolen value embedded in the path.
That is why this is more than a prompt injection story. It is a browser rendering story, a CSP allowlist story, and a product architecture story. The model was gullible, but the exfiltration happened because normal web primitives were composed around that gullibility.
How severe is this if Microsoft and NVD disagree on the score?
The public severity picture is messy, which is normal for AI bugs and still annoying for teams that have to prioritize work by Tuesday afternoon.
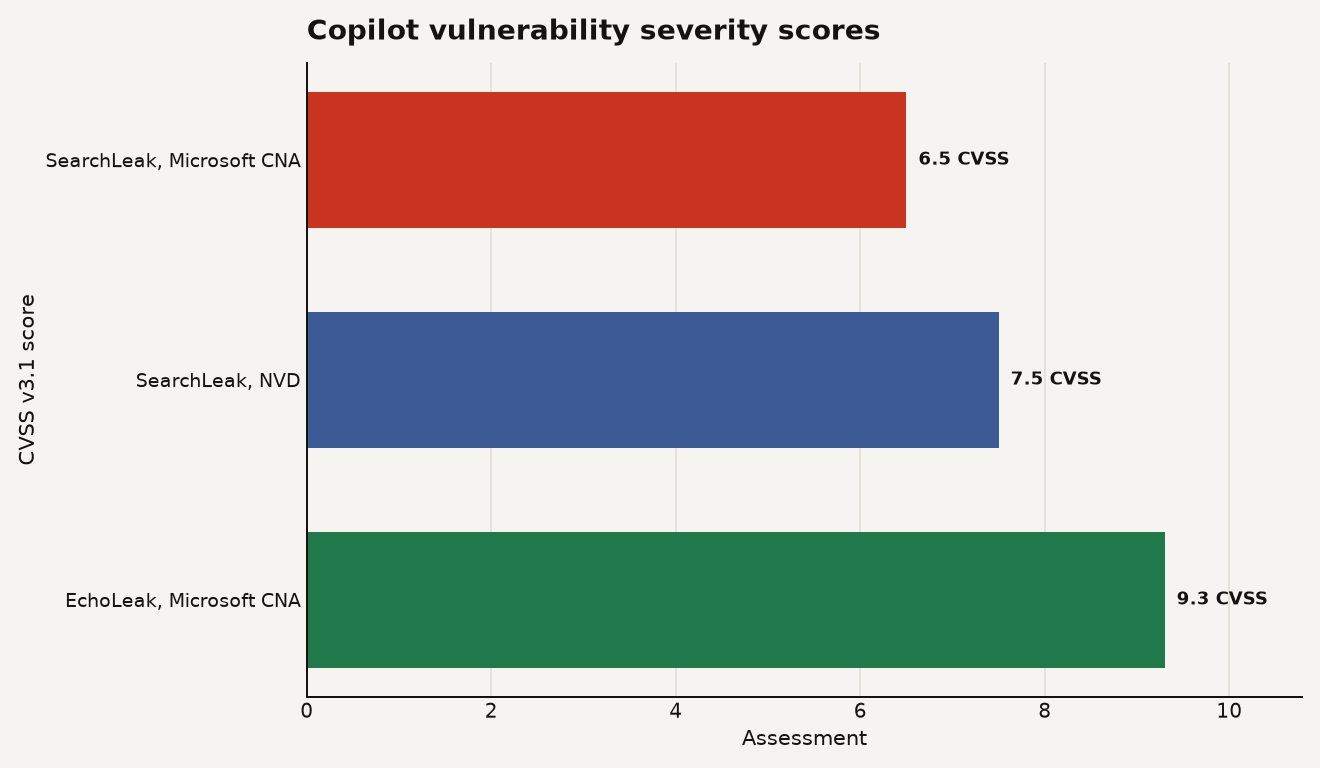
Microsoft’s CNA score for CVE-2026-42824 is 6.5 medium, with user interaction required and high confidentiality impact. NVD lists the same CVE at 7.5 high, with no user interaction in its vector. Varonis, meanwhile, says Microsoft remediated the issue and gave it a maximum critical severity rating. The NVD record describes the flaw as improper neutralization of special elements used in a command in M365 Copilot, allowing information disclosure over a network, and shows both the Microsoft and NVD CVSS views on the same page.
The chart below puts the scoring dispute next to EchoLeak, the 2025 M365 Copilot disclosure that Microsoft’s CNA scored at 9.3 critical. Do not read this as a clean league table. Read it as a warning that agentic vulnerabilities still do not fit neatly inside old scoring boxes.
The practical severity is closer to the data boundary than the number. A 6.5 bug that can retrieve a password reset email in a CFO’s mailbox is not a medium business problem. A 7.5 bug that only reaches a test tenant with no sensitive corpus is less exciting. CVSS is a triage input. It is not a data classification engine.
That matters because Copilot’s product value comes from Microsoft Graph. Microsoft’s architecture docs say Microsoft 365 Copilot uses Graph to access user data in the user’s context and describes the system around permissions, Conditional Access, and MFA. The same grounding that lets a product lead ask for “the latest board deck and the email thread from Sarah” gives an exploit chain a rich retrieval surface if the assistant can be tricked into acting on the user’s behalf.
This is the bargain you accept when you buy an enterprise copilot. Microsoft’s pricing page lists Microsoft 365 Copilot as a paid business product, with the classic enterprise add-on still commonly anchored around $30 per user per month depending on plan and term. At that price, the security question is not “does it hallucinate sometimes?” It is “can it become a search API for whatever the user can touch?” Microsoft’s own Copilot architecture documentation makes the user-context model central to how the product works.
Why should builders care if this was already patched?
Because patches fix instances. Product patterns repeat.
SearchLeak rhymes with earlier Copilot incidents. Varonis disclosed Reprompt in January 2026 as a single-click Microsoft Copilot Personal attack that used a legitimate Microsoft link and a parameter-driven prompt flow. EchoLeak, disclosed in 2025 and tracked as CVE-2025-32711, was documented as a zero-click Microsoft 365 Copilot information disclosure issue. The NVD page for EchoLeak shows Microsoft’s CNA score at 9.3 critical and NVD’s own score at 7.5 high.
The common thread is not that Microsoft is uniquely bad at AI security. The common thread is that LLM products keep trying to use natural language as both data and control plane. That boundary is squishy. Attackers like squishy.
If you build with LLMs, SearchLeak should change four parts of your roadmap:
- Rendering: Treat streamed model output as hostile from token 1, not after the final message is complete. Sanitization that runs after rendering is theater with better lighting.
- Egress: Do not let assistant surfaces fetch arbitrary URLs through trusted intermediaries. CSP allowlists are not a data loss prevention plan if an allowlisted service can fetch attacker supplied URLs.
- Permissions: Scope retrieval to the task, not to the full user. “The user can access it” is a starting point for authorization, not the final line of defense.
- Telemetry: Log assistant initiated searches, rendered tool outputs, and outbound requests as one trace. If those live in three dashboards, your incident response timeline will look like confetti.
The underrated lesson is the render path. Many AI security reviews focus on the model prompt, system prompt, jailbreak filters, and retrieval chunking. SearchLeak says the browser is still in the room. If your assistant streams Markdown, HTML, citations, cards, images, or tool previews, your frontend is now part of the agent sandbox.
That connects directly to the problem we covered in agent risk in every default: once assistants sit inside normal work tools, unsafe defaults spread faster than security teams can write exceptions. The risk is not a sci-fi agent going rogue. It is a very ordinary request leaving a very ordinary browser before your guardrail runs.
What should you change in your own AI stack this week?
Start with the assumption that prompt injection will happen. OWASP’s 2025 Top 10 for LLM Applications puts prompt injection at LLM01 and sensitive information disclosure at LLM02, which is a useful ordering for builders: first assume the model can be manipulated, then assume the manipulated model will try to reveal something valuable. OWASP’s 2025 LLM Top 10 is blunt about these classes of risk.
Then move controls out of prose and into code.
For a production assistant, that means every tool call should pass through deterministic policy. A model can request “search recent finance emails,” but code should decide whether that request is allowed, whether the current task needs it, whether the output can include one-time passwords, and whether the result can be rendered with network-capable markup.
A useful internal checklist has 7 questions:
- Can a URL parameter, document, email, calendar invite, ticket, or webpage become an instruction without a user explicitly submitting it?
- Does streamed output render before sanitization completes?
- Can generated Markdown or HTML trigger a network request?
- Do allowlisted domains accept attacker controlled fetch targets?
- Are assistant searches visible as first-class security events?
- Can the assistant retrieve more data than the active task requires?
- Can you replay the whole chain from prompt input to network egress in one trace?
If the answer to any of the first 4 is yes, you have a product bug waiting for a name. If the answer to either of the last 2 is no, you have an incident response problem waiting for a Friday.
The hiring implication is also concrete. Do not staff AI security as only model evaluation. You need frontend security, cloud security, identity, and data governance in the same review. SearchLeak used a prompt, a DOM race, CSP behavior, and SSRF. That is not one specialist’s home turf.
The business implication is blunter. Copilots make over-permissioned data useful. That is the sales pitch. They also make over-permissioned data easier to steal when the assistant boundary fails. Before expanding seats from 50 users to 5,000 users, audit the places where “everyone” can read folders that no one remembers creating in 2019.
What should survive the next Copilot patch?
The SearchLeak patch matters. If you run Microsoft 365 Copilot Enterprise, you want Microsoft’s server-side remediation in place, and you want security teams looking for suspicious Copilot Search URLs with encoded prompts, image tags, or instructions to embed data in URLs. Varonis specifically recommends monitoring the q parameter, reviewing CSP allowlists, and treating AI streaming output as untrusted.
But the durable move is architectural humility. Do not make the model the referee for whether text is an instruction or data. It will sometimes guess wrong, and the attacker only needs one useful wrong guess.
The safer pattern is boring and strong: least privilege retrieval, render-time sanitization, deny-by-default egress, and traceable tool execution. That will feel slower than shipping a prompt wrapper. Good. Security that depends on the assistant politely refusing the bad thing is not security. It is a vibes-based firewall.
SearchLeak is patched. The lesson should remain in your backlog until your assistant cannot leak data just because a sentence asked nicely.
Sources
- Varonis Threat Labs: SearchLeak: How We Turned M365 Copilot Into a One-Click Data Exfiltration Weapon
- NVD: CVE-2026-42824 Detail
- Microsoft Learn: How does Microsoft 365 Copilot work?
- Microsoft: Microsoft 365 Copilot Plans and Pricing
- Varonis Threat Labs: Reprompt: The Single-Click Microsoft Copilot Attack that Silently Steals Your Personal Data
- NVD: CVE-2025-32711 Detail
- OWASP: Top 10 for LLM Applications 2025