The next frontier model launch now has a new dependency: Washington.
The GPT-5.6 delay reported on June 25, 2026 is small on the calendar and large in the operating model. OpenAI is expected to release GPT-5.6 first as a limited preview for a small group of enterprise customers, while the Trump administration approves access customer by customer during that preview period, according to Reuters' account of The Information's report. Axios separately reported that the request came from the White House Office of the National Cyber Director and the Office of Science and Technology Policy, and that it was tied to security concerns around frontier AI model testing.
The important number is not a benchmark score. It is one government approval queue.
For builders, this matters because GPT-5.6 is not just another model version with better coding, reasoning, or cyber capability. It is a test of whether access to the best U.S. models is becoming conditional infrastructure. If your product roadmap assumes that the next OpenAI, Anthropic, Google, or xAI model lands in your account on launch day, that assumption now needs a risk register.
This follows a rough June for frontier AI governance. On June 2, President Donald Trump signed Executive Order 14409, which created a voluntary framework for giving the federal government up to 30 days of pre-release access to certain covered frontier models. Ten days later, Anthropic said the U.S. government ordered it to suspend access to Claude Fable 5 and Claude Mythos 5 for foreign nationals, including foreign-national employees inside the United States, and Anthropic disabled both models for all customers after receiving the directive at 5:21 p.m. ET on June 12.
That sequence turns a policy phrase, voluntary review, into a production concern.
What did OpenAI agree to change about GPT-5.6?
OpenAI appears to be changing the launch shape, not cancelling the model. The reported plan is a limited preview for a small number of enterprise customers, with the government approving customer access during the preview window, and Sam Altman reportedly told staff he hoped for a broader release a “couple of weeks later” in Reuters' summary of The Information's reporting.
Axios framed the move as the first time the U.S. government has preemptively asked an American AI company to restrict a model launch before release, citing a source familiar with the request. That distinction matters. Previous government testing arrangements gave officials a look before release. This reported request gives officials influence over who gets the model first.
There is a practical difference between “the government can test this” and “the government can decide which customers touch this.” The first affects lab calendars. The second affects your sales pipeline, your pilot schedule, and your dependency graph.
The June 2 executive order tried to keep the program inside a pro-innovation lane by saying the framework should not create a mandatory government licensing or preclearance requirement for model publication, release, or distribution, according to the official order. Three weeks later, the GPT-5.6 rollout shows why voluntary frameworks can still become coercive in practice. If a regulator asks and your biggest future customers are regulated enterprises or government contractors, “optional” starts wearing a suit.
The case-by-case access model also creates a quiet competitive problem. A preview cohort is no longer just a product beta. It can become a government-filtered market advantage. If one bank, defense contractor, or cloud security vendor gets GPT-5.6 two weeks before a rival, that timing can shape demos, procurement memos, and integration work.
Why did Washington move now?
The immediate backdrop is cybersecurity. OpenAI said on June 22 that an updated GPT-5.5-Cyber reached 85.6 percent on CyberGym, compared with 81.8 percent for GPT-5.5, in its Daybreak cybersecurity announcement. That is a narrow benchmark claim, but it points at the same policy fear: frontier models are getting better at the work security teams and attackers both care about.
Anthropic made the risk vivid in April with Project Glasswing, an effort to give selected defenders access to Claude Mythos Preview. Anthropic said the launch group included AWS, Apple, Broadcom, Cisco, CrowdStrike, Google, JPMorganChase, the Linux Foundation, Microsoft, Nvidia, and Palo Alto Networks, and priced Mythos Preview at $25 per million input tokens and $125 per million output tokens through the Claude API, Bedrock, Vertex AI, and Microsoft Foundry in its Project Glasswing announcement.
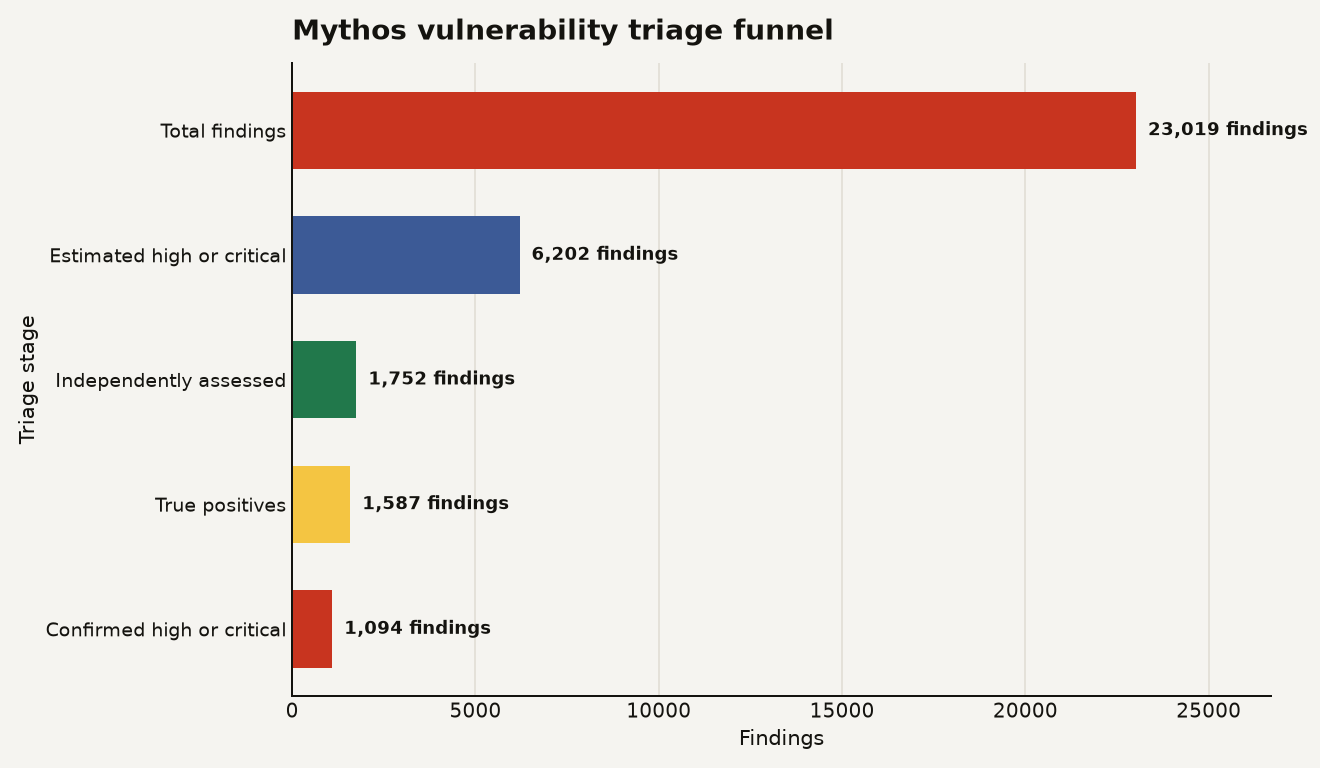
Then the numbers got bigger. Anthropic reported on May 22 that Mythos Preview had scanned more than 1,000 open-source projects and estimated 23,019 vulnerabilities, including 6,202 high or critical findings, in its initial Glasswing update. After independent review of 1,752 of those high or critical findings, Anthropic said 1,587 were true positives and 1,094 were confirmed high or critical.
The chart below shows the operational bottleneck behind the policy panic: AI can generate findings faster than humans can verify, disclose, and patch them. Anthropic's funnel falls from 23,019 total findings to 1,094 independently confirmed high or critical vulnerabilities, which is still a serious pile of work.
This is the piece many hot takes miss. The government is not reacting only to a chatbot being clever. It is reacting to models that can compress vulnerability discovery timelines. If a model can help a defender find a bug, it can help an attacker aim at a similar class of bug once the capability spreads.
Anthropic says the government moved too aggressively. In its June 12 statement, Anthropic said it received the directive at 5:21 p.m. ET, that the government had not provided specific details of the national security concern, and that the suspected jailbreak was narrow rather than universal, according to Anthropic's public statement. The company also argued that applying the same standard across the industry would essentially halt all new frontier model deployments.
You do not need to pick a hero in that dispute to see the new rule of the road. Frontier model access is now entangled with national security review, cyber benchmarks, nationality controls, and political discretion.
What does this do to your model roadmap?
If you build with frontier models, the GPT-5.6 delay turns model availability into a supply-chain variable. That sounds boring. It is expensive.
A team that planned to ship a GPT-5.6-powered coding agent in July 2026 may now need to answer three questions before it writes a single migration ticket: whether it will qualify for preview access, whether its customers will allow unreviewed model substitution, and whether a fallback model changes the product promise. That is the same grim lesson behind harder agent verification work: capability only counts when you can prove it survives the production path.
The biggest hit lands on companies that sell “best model available” as a feature. If your moat is instant access to the newest model, a government-approved preview queue can turn that moat into a waiting room. The better strategy is to own the workflow around the model: evaluation harnesses, routing, monitoring, domain data, customer permissions, and fallback behavior.
Here is what this means for you:
- Roadmaps need model-delay branches. Treat GPT-5.6 access like a vendor launch with regulatory risk, not like a normal API version bump.
- Procurement will ask sharper questions. Enterprise buyers may want to know whether your AI feature depends on a preview model that only certain customers can access.
- Identity and eligibility become product requirements. Export-control language around foreign nationals can force customer, employee, and contractor access checks that most AI apps were never designed to perform.
- Benchmark claims need local proof. OpenAI's 85.6 percent CyberGym result tells you the model can perform on one cyber evaluation, but your own repo, ticket backlog, and incident-response workflow need separate testing.
- Fallback quality becomes a board-level issue. If a restricted model disappears for two weeks, your product should degrade gracefully rather than produce a support fire drill.
The identity point is especially ugly. The Export Administration Regulations define a deemed export to include releasing controlled technology or source code to a foreign person in the United States, according to 15 CFR 734.13. Whether and how that applies to hosted model access will be argued by lawyers, but Anthropic's June 12 experience shows the product consequence: when compliance cannot be scoped cleanly, the provider may shut off access broadly.
That is a product design problem, not just a legal memo.
How should builders reduce preview risk now?
Start by separating capability planning from vendor planning. Your product spec can say “frontier reasoning model with tool use and strong code understanding.” Your architecture should avoid saying “GPT-5.6 or bust.”
The practical playbook is boring and useful:
- Build a model abstraction layer that records model, version, region, customer eligibility, and safety tier for every request.
- Maintain at least two viable model routes for critical workflows, even if one route costs more or performs worse.
- Run pre-launch evals against your own tasks, not just public benchmarks, and keep the pass-fail threshold stable across model swaps.
- Create a customer-facing incident plan for model withdrawal, including feature degradation, data retention changes, and support language.
- Track government-review status as part of vendor due diligence, the same way you track SOC 2, data residency, and uptime.
The key move is to treat frontier models as regulated dependencies before the law fully says they are regulated. That posture costs some engineering time in June 2026. It costs far less than rewriting your core workflow after a launch gets gated.
Security teams should be even more direct. If you are using cyber-capable models for vulnerability research, require stronger audit trails than you would for a general coding assistant. OpenAI's Trusted Access for Cyber program required individual members accessing its most cyber-capable and permissive models to enable Advanced Account Security beginning June 1, 2026, according to OpenAI's Trusted Access update. That is the shape of the future: better models, narrower doors, more logs.
Business leaders should also stop promising exact model names in customer contracts unless the model provider has committed access terms in writing. Promise outcomes and service levels. Keep the model route as an implementation detail where possible. Your customer cares that the workflow works on Friday afternoon, not that your slide deck said GPT-5.6 in 28-point type.
Will this become normal for frontier models?
Yes, for the models that touch cyber, bio, autonomous agents, critical infrastructure, or national-security customers. The normal version will probably look less dramatic than the Anthropic shutdown and more like the OpenAI preview: selected customers, government testing, trusted-access tiers, and delayed general availability.
The U.S. government has already built the institutional path. In May 2026, NIST's Center for AI Standards and Innovation announced agreements with Google DeepMind, Microsoft, and xAI for frontier AI national-security testing, according to the NIST bulletin. OpenAI and Anthropic already had evaluation relationships, and the June 2 executive order gave agencies a clearer mandate to shape pre-release review.
The uncomfortable part is consistency. OpenAI reportedly gets a limited preview with customer-by-customer approval. Anthropic got a foreign-national access directive that forced a global customer shutdown. If that pattern persists, the market will read policy risk as company-specific risk. Investors, customers, and developers will price models partly on their chance of staying available.
That creates an opening for open-weight and foreign models, including models that U.S. agencies cannot review before release. Axios reported on June 25 that Z.ai's GLM-5.2 had agentic capabilities that rival Claude Opus 4.8 and OpenAI's GPT-5.5 while costing roughly half as much to run, citing its reporting on Chinese open-source model progress. If regulated U.S. frontier access becomes slow and unpredictable, some builders will move work to models with fewer approval gates, even when those models bring weaker support, less monitoring, or different geopolitical risk.
That is the policy trap. Restricting the safest monitored channel can push some usage toward less visible channels. The smartest version of government review would give labs a predictable path to ship and give customers a reliable way to qualify for access. The dumb version turns every frontier launch into an opaque favor economy.
The moat is no longer model access
The GPT-5.6 delay is a warning to stop building as if the next model arrives like a package at the loading dock. The frontier is becoming permissioned, especially where code, agents, and security overlap.
So build the thing that survives the permission layer. Own your evals. Own your routing. Own your customer trust. The model will change. The approval queue will change. Your architecture should not panic every time Washington discovers the release notes.
Sources
- The Verge: OpenAI will delay GPT-5.6 after Trump administration request
- Reuters via Investing.com: Trump administration asks OpenAI to stagger release of new model
- Axios: Trump administration asks OpenAI to limit next model release
- White House: Executive Order 14409
- OpenAI: Daybreak, tools for securing every organization in the world
- OpenAI: Scaling Trusted Access for Cyber with GPT-5.5 and GPT-5.5-Cyber
- Anthropic: Project Glasswing
- Anthropic: Project Glasswing, an initial update
- Anthropic: Statement on the US government directive to suspend access to Fable 5 and Mythos 5
- NIST: CAISI signs agreements regarding frontier AI national security testing
- Electronic Code of Federal Regulations: 15 CFR 734.13
- Axios: China's new open-source model accelerates AI hacking threat