A conference review used to mean a few overworked humans, a PDF, and a calendar invite with moral injury attached. Now it also means an agentic reviewer with a search tool, a segmentation pipeline, and enough inference budget to stare at a proof until something cracks.
AI peer review crossed a useful line this week because Google put formal numbers behind Paper Assistant Tool, or PAT: the system reached 89.7% detection accuracy on a filtered math and computer science error benchmark, compared with 55.2% for a zero-shot Gemini 3.1 Pro baseline, according to Google's PAT paper submitted on June 26, 2026. The bigger story is less glamorous than the Reddit framing. The formal record says PAT reviewed over 4,700 submissions across STOC and ICML, while the ICML pilot alone handled about 4,500 papers with roughly 30-minute average turnaround.
That is still a large operational test. It also changes the question for builders. The question used to be whether an LLM could write a plausible review. The better question now is whether agentic AI peer review can become a reliable verification layer before humans spend scarce judgment on novelty, taste, and significance.
What did Google actually deploy at ICML and STOC?
PAT was deployed as a pre-submission author tool, meaning authors could request private AI feedback before their papers entered formal review. The ICML retrospective says the program ran from January 14 to January 26, 2026 and produced feedback for approximately 4,500 papers.
The distinction matters. PAT was not the program committee. It did not make acceptance calls. It did not hand reviewers a secret score. The ICML launch post said the feedback was optional, visible only to authors, and separated from the official peer review process.
Under the hood, PAT looks much more like an agentic workflow than a single prompt pasted into a chatbot. The formal paper describes a four-stage pipeline: document segmentation, adaptive compute budgeting, deep review agents, and global synthesis with search grounding for hallucination checks.
That architecture is the story for builders. Google did not win by asking a model to be a reviewer. It gave the model a workflow: split the paper, spend more reasoning on dense sections, gather critiques, deduplicate them, and ground questionable references. If you are building any high-stakes AI reviewer for code, contracts, clinical notes, or financial memos, this is the reusable pattern.
The chart below shows why conference organizers are reaching for machinery. Google’s paper reports combined ICLR, ICML, and NeurIPS submissions rising from 17,051 in 2020 to an estimated 73,883 in 2026. That is a review market with a supply problem.
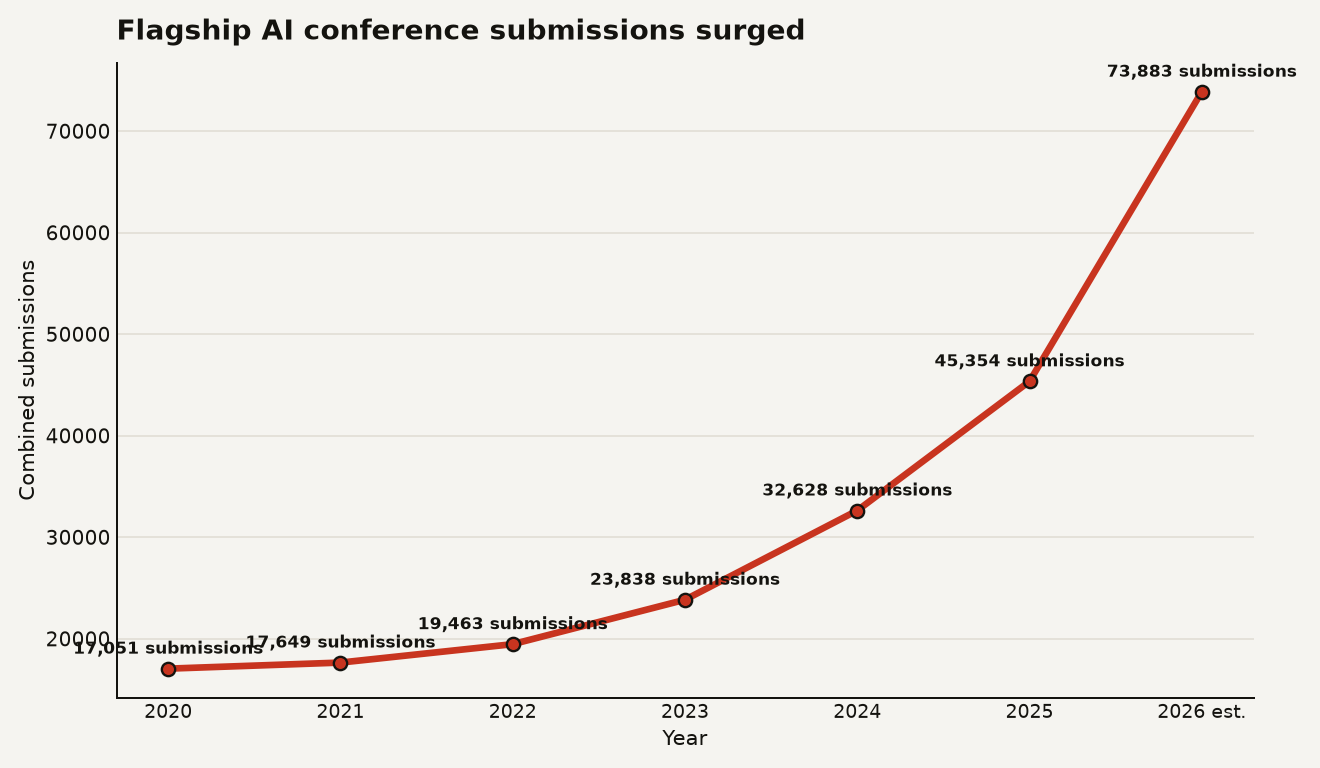
The chart above should make one point painfully clear: review quality is being squeezed by volume before anyone argues about model ideology. Google’s table lists ICML at 24,371 submissions in 2026, and the same paper treats the 2026 NeurIPS number as an estimate derived from the 2024 to 2025 growth rate.
How good was PAT at finding actual errors?
The cleanest benchmark result is narrow and impressive. Google tested PAT on a filtered subset of the SPOT benchmark containing math and computer science papers with equation or proof errors, and the subset contained 26 papers with 29 errors, according to the PAT evaluation section.
That caveat is doing real work. This is not a general measure of review quality across all machine learning papers. It is a test of catching known equation and proof problems in a small, selected slice of retracted or corrected work.
Still, the lift is hard to ignore. The paper reports 21.1% detection accuracy for the original SPOT state of the art, 55.2% for zero-shot Gemini 3.1 Pro, and 89.7% for PAT using Gemini 3.1 Pro.
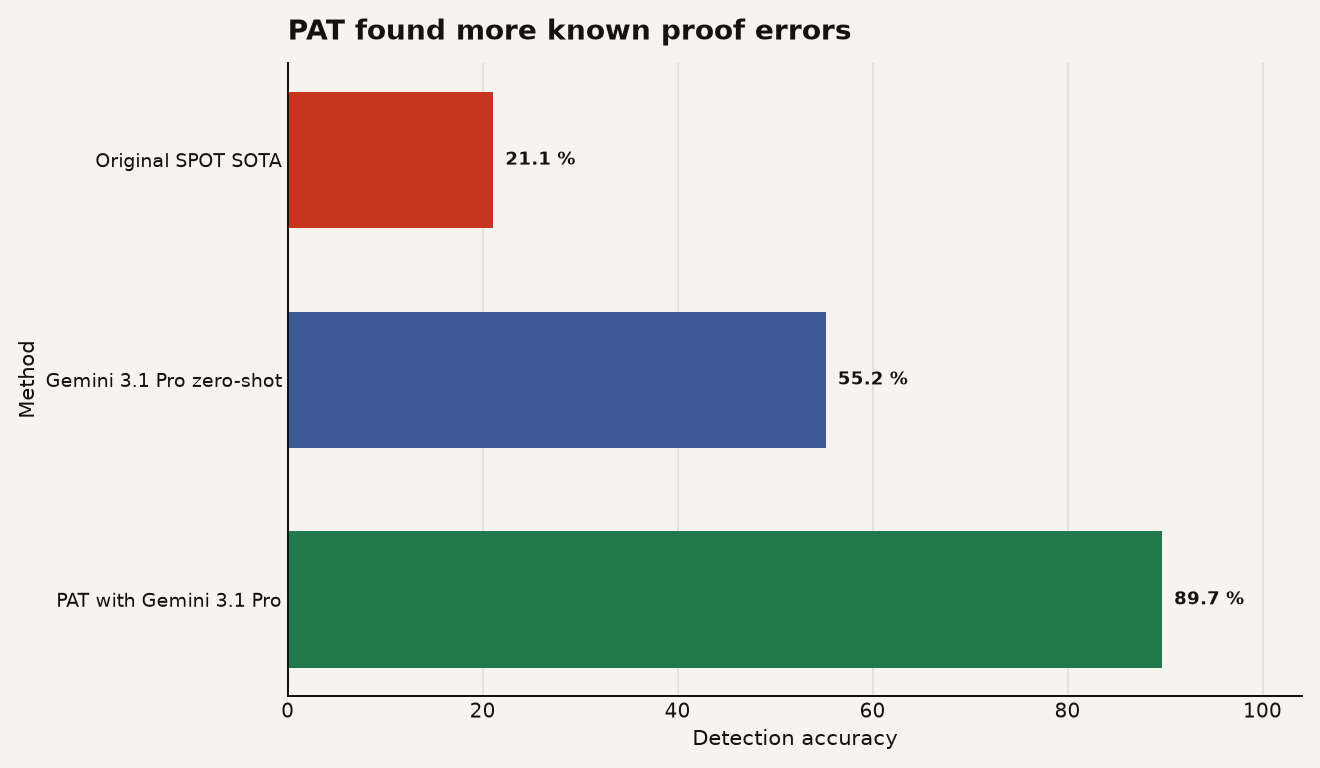
The chart above shows the product lesson: orchestration beat the base call. The jump from 55.2% to 89.7% is a 34.5 percentage point gain, and the practical difference is the difference between catching about half of known proof errors and catching almost nine out of ten in this narrow setup.
The author survey results tell a messier but more useful story. The ICML retrospective says 869 authors responded, 92.1% said they would use PAT again, and 73.3% rated the feedback as very or mostly helpful.
The deeper signal was behavioral. In the same ICML survey, 35.4% of authors with theory in their papers said PAT identified significant theory gaps requiring more than an hour to fix, and 31% of authors with experimental results said PAT pushed them to run new experiments.
For STOC, Google reported more than 100 survey respondents, with 97% finding the feedback helpful and 97% saying they would use the tool again in the STOC writeup. That post also said more than 80% of submitted papers at the time the experiment ended had opted into the AI review.
The formal paper also gives the uncomfortable part. PAT’s authors list date hallucinations, PDF parsing issues, and false claims that valid proofs were wrong as recurring limitations. That is exactly where your product design should slow down.
Why should builders care beyond academic publishing?
Because this is the same design problem hiding inside every serious agent product.
A review agent can be useful before it can be trusted with the final decision. That is the underrated lesson. PAT works best, at least in the evidence published so far, as a private pre-submit critic. It expands the author’s review surface without moving formal authority away from humans.
For a builder, that maps cleanly onto several product categories:
- Code review: Run the agent before pull request review, especially on migrations, security-sensitive diffs, and numerical code.
- Research operations: Use agents to check claims, figures, equations, and missing baselines before a technical memo reaches leadership.
- Enterprise compliance: Let agents surface policy conflicts before a human approver signs off.
- Customer-facing analytics: Add an agentic validation pass before a generated dashboard or narrative goes to a client.
The business consequence is simple: the first durable market may be pre-review, not replacement review. Products that reduce embarrassment before handoff have an easier trust path than products that claim to arbitrate truth on day one.
There is also a cost story. The AAAI-26 AI review pilot paper says its separate conference-wide AI review system generated reviews for 22,977 full-review papers in less than a day, at a reported cost of less than $1 per paper through donated OpenAI API credits.
That AAAI result is not PAT, but it confirms the operational direction: once review agents are packaged as pipelines, the bottleneck shifts from raw generation to governance, evaluation, and accountability. Data Today has been tracking that same shift in agent evaluation, especially in benchmark gaps that still expose agents when the task becomes interactive and adversarial.
Here is the blunt product read: if your agent only produces fluent criticism, you have a demo. If it can point to the exact lemma, experiment, assumption, or data dependency that broke, you have a workflow primitive.
What should you do before adding an AI reviewer to your own workflow?
Start with the authority boundary. Decide whether your agent is allowed to suggest, block, route, or approve. PAT’s published ICML role sat in the safest box: suggest. AAAI’s system moved closer to the process by giving clearly labeled AI reviews to authors and committee members, but it still did not include scores or recommendations, according to the AAAI paper.
Then measure the annoying things. A reviewer agent should be judged on recall, precision, time saved, human verification burden, and false escalation rate. If it finds one real bug by dumping 100 speculative complaints into a reviewer’s lap, it has moved the work rather than reducing it.
Use a staged rollout:
- Private shadow mode: Generate reviews that only the author or engineer sees.
- Required acknowledgement: Ask the human to mark each critique as valid, invalid, or unresolved.
- Audited escalation: Let the agent flag high-severity issues, but route them through a named owner.
- Policy integration: Only after calibration, connect the system to gates such as release checks or submission readiness.
The core metric is human correction quality. A good reviewer agent should make the next draft stronger. The ICML number to watch is 31%: nearly one-third of experimental-paper respondents said they ran new experiments after PAT feedback, according to the conference retrospective linked above.
Keep the adversarial angle in view. If AI reviewers become predictable, authors will optimize for them. In software, that means code that satisfies the checker while hiding the bug one layer deeper. In science, it means papers polished for the agent’s rubric while retaining fragile claims.
What comes after author-side AI peer review?
Google’s paper lays out four roles for AI in peer review: author tool, reviewer tool, supporting reviewer, and total automation. The credible near-term path is the middle: AI as a supporting technical reviewer whose findings are visible, contestable, and audited by humans.
The dangerous path is quiet delegation. The same paper cites a 2026 concern that reviewers are already using AI against venue policies, and this is where conferences and companies share the same governance problem. Hidden AI use creates accountability fog.
Transparent AI review is easier to govern. Label the review. Log the model and tools. Preserve the critique trail. Let the affected party challenge the finding. Record whether a human accepted or rejected the point.
That is boring infrastructure. Boring infrastructure is how trust gets built.
The next fight will be access. Google’s PAT used advanced Gemini Deep Think style reasoning and conference partnerships. If only top labs and top venues get strong pre-review agents, the publication funnel could become more unequal while claiming to improve rigor. The same pattern will show up inside companies: teams with better review agents will ship cleaner work, and teams without them will look sloppier even when their ideas are good.
The reviewer became a build target
AI peer review now has enough evidence to deserve engineering attention and enough failure modes to deserve adult supervision. Treat it like a compiler warning for knowledge work: valuable, noisy, sometimes brilliant, and dangerous when promoted to judge without appeal.
The teams that benefit first will avoid the grand claim. They will use the agent before the meeting, before the submission, before the pull request, before the customer sees the chart.
That is where the moat starts: not with an AI that decides what is true, but with a workflow that makes fewer people ship something false.
Sources
- arXiv: Towards Automating Scientific Review with Google's Paper Assistant Tool
- ICML Blog: Retrospective on PAT x ICML 2026 AI Paper Assistant Program
- ICML Blog: ICML Experimental Program using Google's Paper Assistant Tool
- Google Research Blog: Gemini-backed Paper Assistant Tool provides automated feedback for theoretical computer scientists at STOC 2026
- arXiv: AI-Assisted Peer Review at Scale: The AAAI-26 AI Review Pilot