Subquadratic attention has the rarest thing in AI right now: a claim big enough to matter and third-party numbers good enough that you should pause before dismissing it.
If the benchmark survives real users, the product question shifts from “how do we chunk this?” to “what happens when the whole codebase fits?”
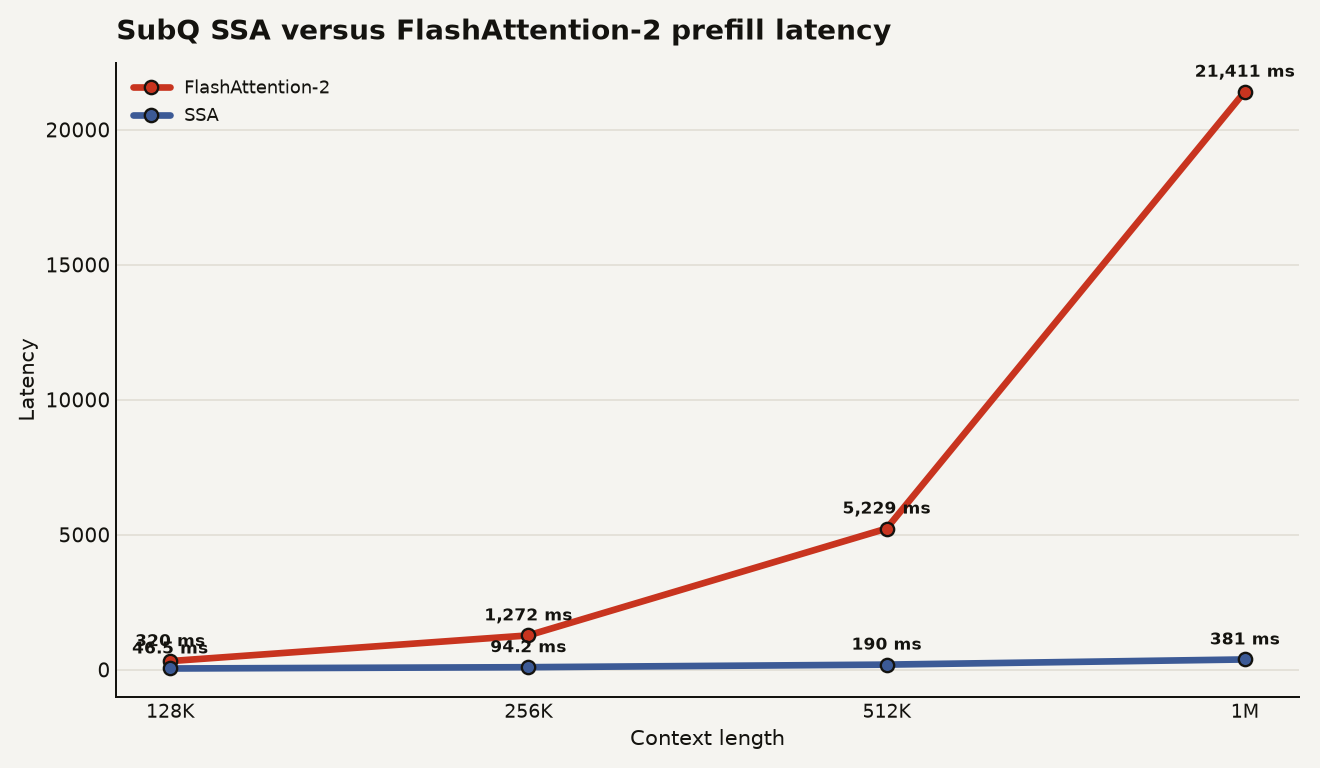
Subquadratic, a Miami AI startup, says its SubQ model replaces dense transformer attention with a sparse mechanism that scales closer to linearly as context grows. That matters because standard attention compares each token with every other token, so the expensive part of the model grows roughly with the square of the input length. The key number is 56.2x: Appen says Subquadratic's Sparse Self-Attention, or SSA, processed a 1M-token input in 380.96 ms while FlashAttention-2 took 21,410.51 ms in its benchmark setup, according to Appen's May 11, 2026 evaluation.
New readers need the short version. Transformers became the default LLM architecture after Google's 2017 paper “Attention Is All You Need” showed that attention-heavy networks could beat older sequence models on translation. FlashAttention and similar kernels made attention much more efficient, but FlashAttention-2 still optimizes the computation rather than removing the all-pairs shape of it. Subquadratic says SSA changes the shape.
That is a serious claim. It also sits behind a gate. Subquadratic's public product flow still asks users to request early access to SubQ's API and SubQ Code for 12M-token reasoning. Builders should read the Appen report as evidence of a promising systems result, not as permission to rebuild a roadmap around a model they cannot fully test yet.
What did Appen actually measure in SubQ?
Appen measured a kernel and a model, which are related but separate. The cleaner evidence is the kernel result: SSA input processing versus FlashAttention-2 across 128K, 256K, 512K, and 1M tokens. Appen says the latency tests used NVIDIA B200 hardware with CUDA 13.0, PyTorch 2.11.0, bfloat16, 5 timed runs, and 3 warmup iterations in the benchmark methodology.
The chart below shows why the claim has teeth. FlashAttention-2 took 319.88 ms at 128K tokens and 21,410.51 ms at 1M tokens. SSA took 46.5 ms at 128K tokens and 380.96 ms at 1M tokens. In the Appen setup, the gap widened as context length grew, which is the behavior you would expect if one path keeps paying an all-pairs tax and the other routes less work.
Appen also reports FLOP reductions, which matter because wall-clock latency can be distorted by implementation details. At 1M tokens, Appen says SSA used 144.9 TFLOP against 9,095.2 TFLOP for the dense FlashAttention-2 comparison, a 62.8x reduction in input-processing FLOPs in the same evaluation. That is the number to watch if you care about cloud bills, because FLOPs map more directly to capacity planning than a single latency run.
Then Appen moves from kernel speed to model quality. On RULER at 128K tokens, SubQ scored 95.6 percent overall, while Appen's landing page says the run covered 13 task types with 100 samples each in its long-context benchmark. On MRCR's 8-needle tier at 1,048,576 tokens, Appen reports an 86.2 percent score across 100 samples in the same published summary. On SWE-bench Verified, Appen reports SubQ resolved 81.8 percent of tasks with extended thinking enabled.
That last number needs context. SWE-bench Verified was introduced by OpenAI in 2024 as a curated benchmark of real GitHub issues, and OpenAI reported GPT-4o resolving 33.2 percent of its samples at launch in its SWE-bench Verified announcement. A reported 81.8 percent is strong, but coding benchmarks in 2026 are crowded, leaky, and increasingly scaffold-dependent. Treat the result as a signal that the architecture may preserve code capability, not as a universal ranking.
Is this really a breakthrough in long context?
The honest answer is: the kernel evidence is more convincing than the product evidence.
Dense attention has a brutal scaling problem because every new token can interact with every prior token. Subquadratic's own explanation says SSA uses content-dependent selection so the model attends to positions that matter rather than every pair, and the company says the mechanism is designed for long-context retrieval, reasoning, and software engineering workloads in its SSA technical overview. That is exactly where today's retrieval-augmented generation systems get complicated.
The difference between a nominal context window and a useful context window matters. NVIDIA's RULER paper created 13 tasks and evaluated 17 long-context models because the basic needle-in-a-haystack test showed only a superficial form of long-context understanding, according to the 2024 RULER paper. In plain English: accepting a huge prompt and using it correctly are different product behaviors.
SubQ's reported 12M-token ceiling sounds dramatic because it would cover many codebases, document rooms, or long agent sessions in one pass. Subquadratic's early access page explicitly markets 12M-token reasoning across large codebases, long-running agents, and complex software workflows. The Appen report, however, gives its strongest quality numbers at 128K and 1M tokens, while the source story reports Appen needle-in-a-haystack testing at 6M and 12M tokens with 98 percent retrieval in MIT Technology Review's June 19, 2026 story.
That distinction is the whole ballgame. A 12M-token input budget helps only if the model can retrieve, combine, and act on the right evidence across that window. For code, that means finding an interface in one package, a failing behavior in another, and a test assumption in a third. For legal or compliance work, it means resolving definitions, exceptions, and obligations that live hundreds of pages apart. A giant prompt can still produce a tiny hallucination with expensive confidence.
The skepticism is healthy for one more reason: Subquadratic has not fully opened the system for broad public testing. MIT Technology Review reported that SubQ was not widely available and that Subquadratic had given very few people access as of June 19, 2026 in its report on the company. Builders should respect Appen's work while refusing to confuse a paid evaluation, a startup technical overview, and public reproducibility.
What changes for your codebase if the numbers hold?
If the SSA curve holds under production traffic, the first casualty is elaborate context plumbing. Many teams now spend weeks building chunkers, retrievers, summarizers, rerankers, context compressors, and agent memories because the model cannot afford to see the whole artifact. That scaffolding is useful, but it becomes a tax when the problem is really “read the repo and patch the bug.”
The business consequence is concrete: long-context cost moves from a hard blocker to a design variable. Appen's measured 1M-token latency split, 21,410.51 ms for FlashAttention-2 versus 380.96 ms for SSA, implies a product experience closer to interactive review than batch processing in the published benchmark. If you run coding agents, compliance review, e-discovery triage, or customer-support audit workflows, that difference affects timeout budgets, worker queues, and whether users stay in the loop.
For builders, the practical read looks like this:
- Roadmap: keep RAG and indexing work alive, but avoid hard-coding your product around 8K or 32K assumptions if your workflows naturally span 100K to 1M tokens.
- Architecture: separate retrieval, context assembly, and model execution behind interfaces so a long-context model can replace parts of the stack without a rewrite.
- Cost: model your worst cases at 128K, 512K, and 1M tokens, because Appen's benchmark shows the biggest SSA advantage at the largest tested context length.
- Moat: proprietary evaluation sets become more valuable than prompt tricks, because anyone can claim a 12M window and very few teams can test whether it works on their messiest documents.
This is where the Data Today angle connects to earlier coverage of infrastructure measurement. In our Blackwell scaling coverage, the useful lesson was that performance claims matter only when the workload shape matches your real bottleneck. SubQ's workload shape is not generic chat. It is prefill-heavy, long-context work where reading the input dominates the bill.
The underrated risk is vendor lock-in at the architecture level. If your product assumes one model can swallow a million-token working set, your fallback plan gets harder. You may need a degraded path that returns to RAG, a smaller model, or a staged agent workflow when SubQ is unavailable, too expensive, or wrong. A good abstraction here is boring. Boring is good when a startup controls the only API that makes the magic trick work.
What should you test before trusting a 12M-token model?
Start with a private eval that mirrors your failure modes. Public RULER and SWE-bench numbers are helpful, but your product probably fails in uglier ways: stale policy documents, duplicated code paths, contradictory tickets, generated files, dead tests, or customer data with messy formatting.
A useful first test has 3 layers. First, run exact retrieval across documents at 128K, 512K, and 1M tokens. Second, add multi-hop tasks where the answer requires 2 to 5 pieces of evidence. Third, ask the model to act, such as producing a patch or a structured decision, and verify the result with tests or deterministic checks. NVIDIA's RULER paper is useful here because it explicitly expands beyond vanilla needle retrieval into multi-hop tracing and aggregation in its benchmark design.
Do not outsource judgment to the context window size. A model that can read 1M tokens may still prefer nearby evidence, compress away an old constraint, or retrieve the right fact without applying it. Subquadratic says SSA's training includes reinforcement learning for long-context retrieval and coding behavior in its technical writeup, which is the right target. Your eval should still punish plausible answers that ignore far-away constraints.
The buying checklist is short:
- Ask for latency and cost at your real prompt sizes, especially 128K, 512K, and 1M tokens.
- Ask whether the served model is the same model behind the benchmark numbers.
- Ask for deterministic replay of failed cases, because long-context bugs are otherwise miserable to debug.
- Ask how the model handles retrieval citations, file offsets, and evidence spans.
- Ask for a fallback path if the 12M-token endpoint is gated, rate-limited, or materially different from the preview.
The hard “no” is also simple. Do not delete your retrieval stack because a startup posted a 56.2x kernel result. Wrap it. Measure it. Put your own evals in CI. If SubQ is real for your workload, your system will get simpler over time. If it fails, your users should never learn that your architecture was balanced on a demo.
The moat moves from prompt glue to proof
Subquadratic has shown enough to earn attention. Appen's 1M-token latency result is too large to wave away as normal benchmark noise, and the reported RULER, MRCR, and SWE-bench numbers suggest the model did not buy speed by wrecking capability in the tested slices.
The next proof will not come from a prettier chart. It will come from boring customer traces: 400 documents loaded, 30 files patched, 6 hidden constraints satisfied, 0 silent misses. If subquadratic attention makes that boring, the long-context era finally becomes a product surface instead of a prompt-length flex.
Sources
- Appen: Benchmarking Subquadratic's latest model and SSA Kernel
- Subquadratic: How SSA Makes Long Context Practical
- Subquadratic: Request early access to SubQ's API and SubQ Code
- MIT Technology Review: A startup claims it broke through a bottleneck that's holding back LLMs
- arXiv: Attention Is All You Need
- arXiv: FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
- arXiv: RULER: What's the Real Context Size of Your Long-Context Language Models?
- OpenAI: Introducing SWE-bench Verified