The benchmark result that should make builders sit up is not the victory lap. It is the shape of the workload. MLPerf Training 6.0 added mixture of experts pretraining to the official suite, then NVIDIA used Blackwell to sweep the board at 8,192 GPU scale.
That matters because training infrastructure is becoming less like buying a faster box and more like operating a distributed system under stress. The model architecture routes tokens. The network has to keep up. The software stack has to hide communication. The cloud provider has to keep thousands of accelerators useful at once. If your AI roadmap assumes you can rent your way out of training complexity, this round is a polite shove in the ribs.
The headline number is 8,192 GPUs. NVIDIA said Blackwell produced the fastest time to train on all seven MLPerf Training 6.0 benchmarks, and its technical writeup lists DeepSeek-V3 671B reaching the target in 2.02 minutes on GB300 NVL72 at 8,192 GPUs in the MLPerf Training 6.0 table. MLCommons describes the benchmark as a measure of wall clock time needed to train a model to a target quality metric, which is the right lens for builders who care about iteration speed rather than peak theoretical FLOPS on its training benchmark page.
What did MLPerf Training 6.0 actually test?
MLPerf Training is the closest thing AI infrastructure has to a neutral stopwatch, although every stopwatch has rules. MLCommons says the suite measures how fast systems train models to a target quality metric, and it normalizes results after multiple runs by discarding the highest and lowest runs in the benchmark methodology. That matters because a single glorious run is easy to market and hard to reproduce.
Version 6.0 made the suite more relevant to 2026 model work by adding two mixture of experts workloads. MLCommons lists DeepSeek V3 with a 3.6 log perplexity target on C4, and GPT-OSS 20B with a 3.34 log perplexity target on C4 in the benchmark table. Those two tests are the reason this round is more interesting than another GPU drag race.
MoE training stresses a different part of the system. A dense transformer mostly asks whether you can multiply matrices quickly and feed them data. A mixture of experts model adds routing, load balancing and all to all communication, because tokens get sent to specialized expert subnetworks. NVIDIA’s developer blog says DeepSeek-V3 671B and GPT-OSS 20B were the new MoE tests, and says Blackwell was the only platform to submit results on both new workloads in its technical analysis.
The chart below shows the scale signal. NVIDIA’s fastest time table lists Blackwell at 8,192 GPUs for DeepSeek-V3 and 8,192 GPUs for Llama 3.1 405B, with smaller but still serious runs at 1,024 GPUs for Llama 3.1 8B and 512 GPUs for GPT-OSS 20B in the published NVIDIA result summary. AMD said Oracle Cloud Infrastructure scaled FLUX.1 to 512 AMD Instinct GPUs, which is the most useful counterpoint because it shows AMD moving into multi-node training rather than only single node comparisons in AMD’s MLPerf Training 6.0 post.
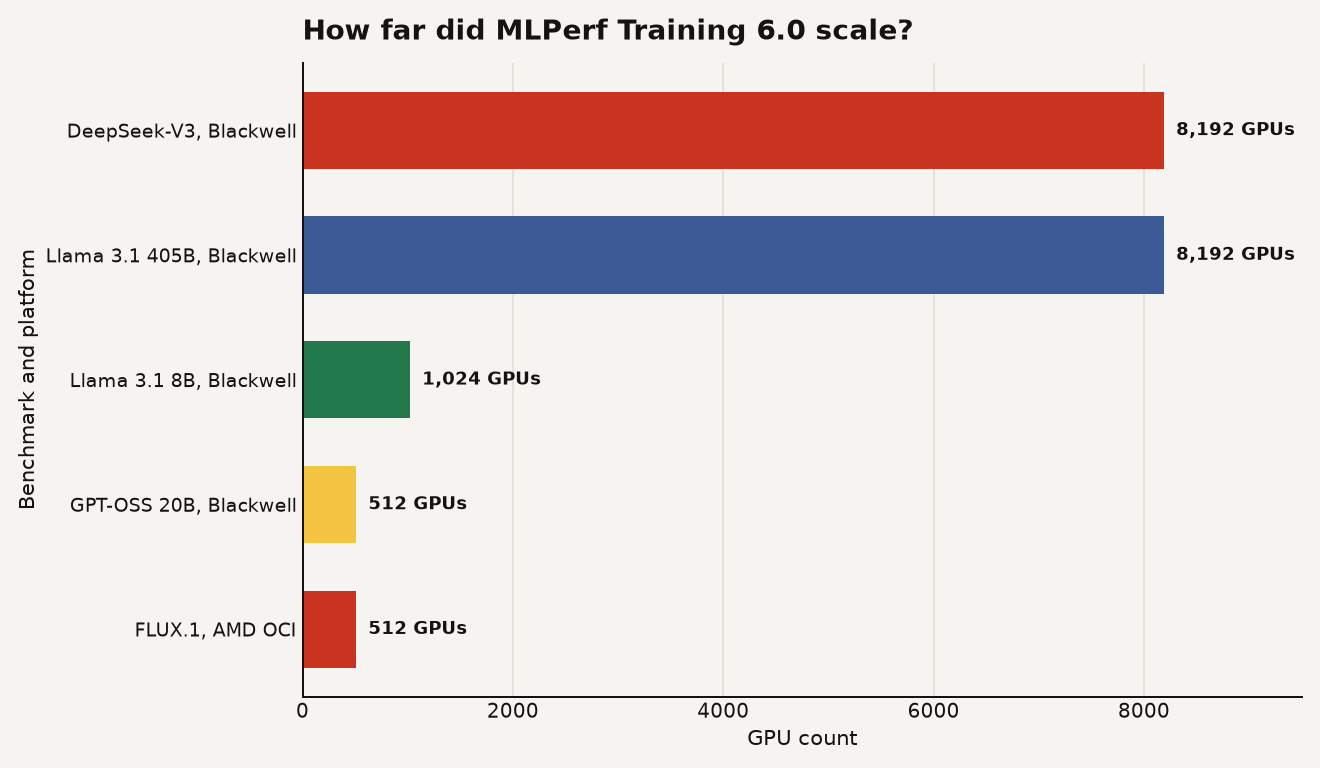
The point is not that every builder needs 8,192 GPUs. Almost nobody does. The point is that the frontier benchmark now rewards rack scale design, network behavior and software orchestration as much as chip arithmetic.
Why is Blackwell’s clean sweep more than vendor theater?
Vendor benchmark posts always arrive wearing a marching band uniform. Read past the brass.
NVIDIA said Blackwell delivered the fastest time to train on every MLPerf Training 6.0 benchmark and was the only platform with submissions across all seven benchmarks in its June 16 announcement. That breadth matters more than a single best score because platform choice is a portfolio decision. You may fine tune a 70B model this quarter, pretrain an 8B internal model next quarter, then test image generation or recommendation workloads after that.
The most concrete result is the MoE scale win. NVIDIA’s table reports DeepSeek-V3 671B on GB300 NVL72 at 8,192 GPUs with a 2.02 minute time to train, and Llama 3.1 405B on GB200 NVL72 at 8,192 GPUs with a 7.07 minute time to train in the same result table. Those are benchmark target runs, not full commercial frontier model training runs, but they still expose whether the system can keep a large cluster coordinated.
The underrated detail is software progress. NVIDIA says DeepSeek-V3 throughput on GB300 improved from 1,298 TFLOPS per GPU in April 2026 to 1,648 TFLOPS per GPU in June 2026 using the NeMo 26.06 container in its throughput discussion. That 27 percent jump without a new chip is the kind of gain that changes procurement math, because leased hardware gets better when the stack matures.
There is a caveat. MLCommons says non imaging benchmark results are very roughly plus or minus 5 percent, and imaging results are very roughly plus or minus 2.5 percent in its scenarios and metrics notes. A 3 percent lead may be a rounding argument. An 8,192 GPU sweep across MoE and dense workloads is harder to wave away.
What does this change for your roadmap and costs?
If you build AI products, the practical lesson is that training cost is no longer just dollars per GPU hour. It is dollars per useful iteration.
A model team that can run a target-quality pretraining slice in minutes instead of waiting on a fragile cluster has more chances to test data mixtures, optimizer settings and architecture changes. NVIDIA says GB300 NVL72 was up to 1.6 times faster than GB200 NVL72 at the same scale in the Blackwell MLPerf announcement. If your bottleneck is experimentation speed, that kind of factor can be the difference between one serious run per week and several.
For a founder or product lead, the buying question changes:
- If you mostly fine tune and serve models, AMD’s progress matters because AMD says MI355X came within 5 percent of NVIDIA B200 on Llama 2 70B fine tuning and within 6 percent on Llama 3.1 8B pretraining in its MLPerf Training 6.0 comparison. That can become negotiating leverage with clouds and hardware vendors.
- If you plan to train MoE models, the interconnect and software stack should move to the top of your evaluation checklist. NVIDIA says its Spectrum-X routing and congestion controls are aimed at MoE all to all traffic in the technical blog.
- If your moat is domain data, faster training changes the value of your dataset. A proprietary corpus becomes more useful when you can afford more ablations, not when it sits behind a once per quarter training run.
- If your team is hiring, you need distributed systems judgment, not only model architecture taste. MLPerf Training 6.0 is a reminder that training work now fails in networking, kernels, orchestration and checkpoint recovery.
This also connects to the power side of the AI buildout. The same teams that care about 8,192 GPU training runs should care about flexible load and grid strategy, because training clusters do not live in a vacuum. We covered that infrastructure pressure in the grid case for flexible data centers, and MLPerf 6.0 is another data point in the same story: compute leadership is becoming facility leadership.
What should you do with the benchmark if you are buying or building?
Use MLPerf Training 6.0 as a shortlist filter, not a procurement oracle.
First, map the benchmark to your actual workload. If you are adapting an open model with LoRA, the Llama 2 70B fine tuning result is more relevant than DeepSeek-V3. If you are training sparse models, the MoE results matter. If your roadmap is mostly inference, this benchmark is the wrong scoreboard.
Second, ask vendors for reproducibility, not screenshots. AMD said 10 ecosystem partners submitted AMD Instinct based results and that partner submissions landed within 6 percent of AMD’s official submissions across two major LLM workloads in its ecosystem section. That is the kind of claim buyers should test with their own container, their own data path and a painful amount of logging.
Third, price the stack as software plus hardware. NVIDIA’s reported 1.3 times DeepSeek-V3 throughput improvement over three months on GB300 came from software optimization, not a new silicon generation in the NeMo container comparison. A cheaper accelerator can lose if your engineers spend six months rebuilding the training stack around it.
Fourth, keep an eye on the benchmark’s blind spots. MLPerf measures time to a target quality metric under defined rules. It does not tell you whether your data governance is sane, whether your model is useful, whether your run survives a bad week of cluster maintenance, or whether your CFO enjoys surprise egress bills.
The cluster is the product
The clean read from MLPerf Training 6.0 is that NVIDIA still owns the high end training system story. AMD is making the lower and middle of the stack more contestable, which matters for pricing and procurement. But at the frontier edge, the benchmark is rewarding the company that sells the chip, the rack, the network, the libraries and the story in one bundle.
That is uncomfortable if you prefer modular markets. It is useful if you need to ship.
The next AI training advantage will look less like a spec sheet and more like a cluster that stays boring while thousands of GPUs do unreasonable things.
Sources
- NVIDIA Blog: Fastest, Largest, Strongest: NVIDIA Blackwell Sweeps MLPerf Training 6.0
- NVIDIA Developer: NVIDIA Blackwell Tops MLPerf Training 6.0 with Industry-Leading Scale and Performance
- MLCommons: MLPerf Training benchmark page
- AMD: AMD Instinct GPUs Deliver Breakthrough Performance, Multi-node Scale and Ecosystem Validation in MLPerf Training 6.0