The EU did not just publish a nice badge for AI slop. It published a product deadline.
AI content labelling is the requirement to tell people, and sometimes machines, when AI generated or altered the thing they are seeing, reading, hearing, or chatting with. On June 10, 2026, the European Commission published its final voluntary Code of Practice for marking and labelling AI generated content, and the legal obligations underneath it start applying on August 2, 2026. That leaves 47 days from today, June 16, 2026, for teams serving European users to decide what gets labelled, where that label appears, and how the audit trail survives a regulator asking awkward questions.
The mistake is to treat this as a marketing disclosure. It is closer to a logging and provenance feature with a legal UI attached. If your product generates public facing text, image, audio, or video, or if it puts an assistant in front of a user, the label is now part of the system design. The code is voluntary. The underlying Article 50 duties are not, as the Commission says in its Code of Practice policy page.
If you already care about agent safety, this belongs in the same mental bucket as prompt logging, tool permissioning, and data lineage. The visible label is the easy part. The hard part is proving which model, workflow, human review step, and publishing path produced the output. That is the same operational muscle behind AI trust boundaries in products, just pointed at disclosure instead of data leakage.
What did the Commission actually publish, and why is the clock so tight?
The Commission published the final Code of Practice on June 10, 2026, as a voluntary route for providers and deployers of generative AI systems to demonstrate compliance with Article 50 of the AI Act. The code has 2 sections: one for providers that build or supply generative AI systems, and one for deployers that put those systems into products, workflows, publications, or user interfaces.
That split matters. The model provider is expected to handle machine-readable marking for AI generated or manipulated outputs. The deployer is expected to handle visible labelling in the places Article 50 covers. If your SaaS uses a model API to generate a customer support answer, a political explainer, a synthetic spokesperson video, or a report summary, you do not get to outsource every disclosure problem to the model vendor.
Article 50 itself is broader than the lazy summary, which is usually “label AI content.” The official AI Act Service Desk says providers of AI systems intended to interact directly with people must inform users they are interacting with AI unless that is obvious, and providers of systems generating synthetic audio, image, video, or text must ensure outputs are marked in a machine-readable format and detectable as artificial where technically feasible. Deployers must disclose deepfakes and AI generated or manipulated public interest text, with carveouts for human review, editorial responsibility, law enforcement, and certain creative contexts. The statutory wording is laid out in the Service Desk’s Article 50 text.
The compressed timeline is the uncomfortable part. The Commission’s own process shows a long runway for policy work and a short runway for product work: a kickoff plenary on November 5, 2025, a first draft on December 17, 2025, a second draft on March 3, 2026, draft Article 50 guidelines on May 8, 2026, and the final code on June 10, 2026. The obligations apply on August 2, 2026, according to Article 113 of the AI Act.
As the chart below shows, the final code arrived 53 days before the Article 50 date. That is enough time to add a banner. It is not generous time to redesign a content pipeline.
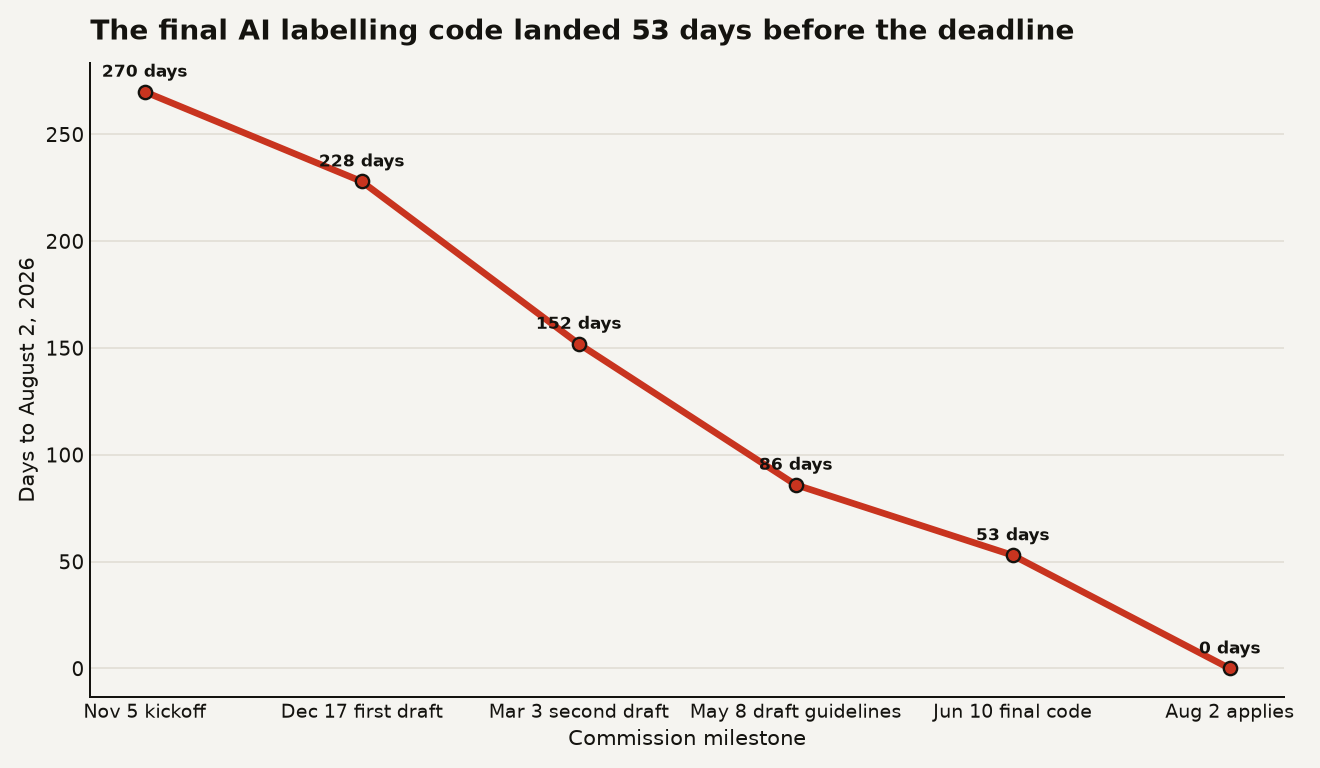
The code’s FAQ says the drafting process involved over 187 participants from industry, academia, civil society, rightsholders, EU Member States and observers, led by 6 independent experts through 3 rounds of stakeholder consultation. That is useful context for one reason: this is not a stray blog post from Brussels. It is the document regulators will expect compliance teams to know, even while the Commission and AI Board still assess its adequacy.
The remaining ambiguity is not small. The Commission says Article 50 guidelines will be published ahead of August 2, 2026, and those guidelines will clarify scope, exemptions, practical application, and how compliance can be demonstrated. In builder language: some acceptance tests are still missing, but the deploy date is not moving.
Which product surfaces are most likely to be in scope?
Start with 4 surfaces, not with your org chart.
First, any interactive AI system that talks directly to a person needs a disclosure unless the AI nature is obvious. A chatbot named “Support assistant” may feel obvious to you. It may not be obvious in a white label banking flow, a health benefits portal, or an enterprise procurement assistant wearing a human team’s name.
Second, generative systems that output synthetic audio, image, video, or text need machine-readable marking at the provider layer. Article 50 uses the phrase “effective, interoperable, robust and reliable as far as this is technically feasible,” which is lawyer language for “do not ship a brittle label that disappears on first export.” The C2PA specification is one relevant provenance standard here because it defines signed content credentials for media provenance, and C2PA’s current technical specification describes manifests that attach asset metadata and provenance information to files.
Third, deployers must disclose deepfakes: AI generated or manipulated image, audio, or video that resembles existing people, objects, places, entities, or events and would falsely appear authentic. The EU’s icon guidance gives concrete examples, including a politician face swap and a fully AI generated deepfake video of a politician. That is the obvious risk category, but not the only one.
Fourth, deployers must disclose AI generated or manipulated text published to inform the public on matters of public interest, unless it has undergone human review or editorial control and a person or legal entity holds editorial responsibility. This is where many content teams will get caught. A model drafted newsletter about tax rules, energy prices, elections, public health, or consumer safety can look like normal content automation until someone asks whether it informed the public on a matter of public interest.
The EU icons are optional, but they are not decorative. The Commission says the icon set has 4 variations: black, white, black with 50 percent transparency, and white with 50 percent transparency. It also says user testing showed performance improved when the basic icon was accompanied by a text label, such as “modified,” in the Commission’s EU icon guidance. That is a product design hint hiding inside a compliance page: icon only is probably weaker than icon plus plain text.
The useful working checklist is boring, which is usually a sign it will save you money:
| Surface | Who owns the first fix? | What to capture before August 2 |
|---|---|---|
| Customer support bot | Product and frontend | First interaction disclosure, UI copy, locale handling, chat transcript metadata |
| AI generated image or video | Media pipeline | Provenance metadata, export behaviour, visible label placement, re-share behaviour |
| Public interest text | Content system owner | Human review flag, editorial owner, model ID, publication workflow |
| Embedded third party assistant | Vendor owner and legal | Vendor terms, disclosure API, fallback label, audit evidence |
The table has 4 rows because most teams can find their risk by walking the product, not by reading the whole regulation in one sitting.
Why does this matter for your roadmap, not just your legal folder?
Because labels are cheap when they are designed into the flow and expensive when stapled on at the end.
A proper AI content labelling implementation touches at least 5 parts of a modern AI product: prompt orchestration, model routing, output storage, frontend rendering, and analytics or audit logs. If you use multiple models, fine tuned variants, RAG pipelines, or human review queues, the label decision is not a single boolean. It is a derived state.
For example, an output might be “fully AI generated” at draft time, then human reviewed, shortened, translated, and published through a CMS. The legal meaning may change after the human review step. The technical metadata may be stripped by export. The visible label may disappear when the content is embedded in a partner site. The regulator will not care that your React component looked clean in staging.
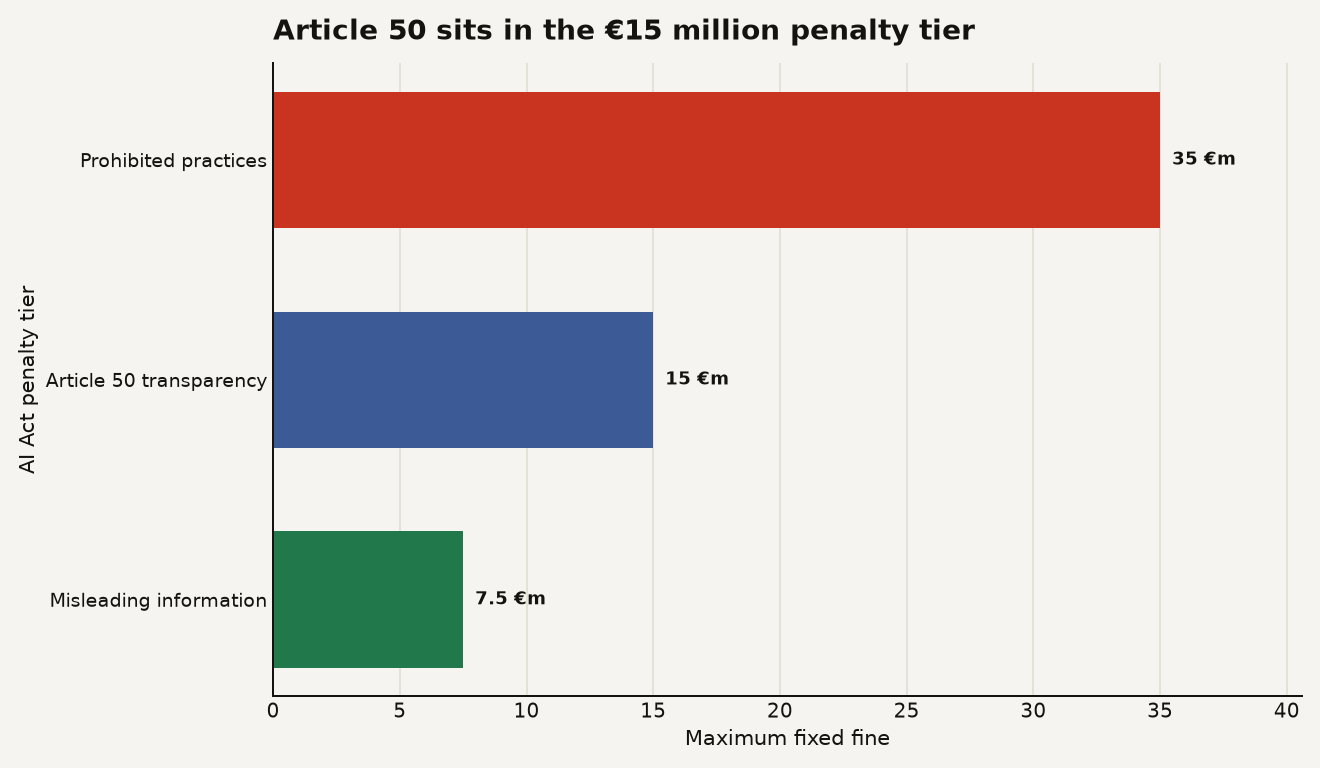
The financial exposure is also not theoretical. Article 99 lists transparency obligations under Article 50 among the provisions where non-compliance can trigger administrative fines of up to €15 million or 3 percent of worldwide annual turnover, whichever is higher for non-SME undertakings. For SMEs and startups, Article 99 says the cap is the lower of the percentage or fixed amount, which is a meaningful break, but not a reason to ignore the work.
The chart below puts Article 50’s penalty tier in context. Prohibited AI practices sit at €35 million. Transparency failures, including Article 50, sit at €15 million. Misleading information to authorities sits at €7.5 million. That middle tier is where sloppy disclosure can become a board discussion.
For builders, the operational consequence is clearer than the legal prose:
- Your content schema needs provenance fields, not just body text and author name. Add model, generation time, workflow, review state, reviewer, and publication channel.
- Your design system needs disclosure components, not one-off banners. Labels need to work in mobile, embeds, downloads, dark mode, screen readers, and translated UI.
- Your vendor contracts need disclosure hooks, especially if a model provider marks outputs in a way your app cannot read or preserve.
- Your analytics should measure label survival, because the EU icon guidance says labels should be visible at first exposure and, in summary form, visible when content is reshared or downloaded.
- Your release process needs a compliance test, the same way payment, privacy, and security sensitive flows get pre-launch checks.
The underrated business issue is trust. If every competitor slaps “AI generated” at the bottom of a page, the company that can explain provenance cleanly will look more credible to enterprise buyers. Procurement teams already ask where data goes. They will start asking where synthetic content came from.
What should you build before August 2 if you serve EU users?
Do not start with the icon. Start with an inventory.
List every place your product creates, modifies, or displays AI generated text, image, video, or audio. Include internal tools if they publish externally. Include partner feeds. Include scheduled jobs. Include “temporary” growth experiments, because temporary experiments have a charming habit of becoming load bearing systems with no owner.
Then tag each flow with 3 questions:
- Does a natural person interact directly with an AI system here?
- Does this generate or manipulate synthetic audio, image, video, or text?
- Does this publish deepfake content or public interest text without human review and editorial responsibility?
If the answer is yes, build from evidence to UI. For each output, store a durable record of how it was made. That record does not need to expose every prompt to users, and it should not leak private data. But internally, you need enough to answer: which system generated it, which version ran, what content type it produced, whether a human reviewed it, who held editorial responsibility, what label was shown, and when the user first saw it.
A lightweight schema could look like this:
{
"content_id": "post_123",
"ai_generated": true,
"ai_modified": false,
"content_type": "public_interest_text",
"model_provider": "example_provider",
"model_version": "2026-06",
"human_reviewed": true,
"editorial_owner": "Example Media Ltd",
"user_label_shown": false,
"label_basis": "human_review_and_editorial_responsibility"
}That snippet is not a legal template. It is a systems point: you cannot make reliable label decisions if the content database forgets the facts behind the decision.
For user facing design, copy should be plain. “AI generated” beats “synthetically mediated informational artifact.” If content is partly modified, say that. If the user is chatting with a bot, say so at the first interaction, not after the user has handed over order numbers, symptoms, or HR details.
For media, assume metadata gets lost unless you test the whole export path. Upload a labelled image, download it, resize it, send it through your CDN, embed it in a social preview, and inspect what survives. If your answer is “the badge disappeared after compression,” that is not a philosophical problem. It is a ticket.
For public interest text, the human review exemption deserves discipline. Do not treat “someone glanced at it in Slack” as editorial control. Create a review state, require a named owner, and log the publication decision. The AI Act’s Article 50 text ties the exemption to both human review or editorial control and editorial responsibility. That sounds like a content governance process because it is one.
What is still unresolved, and where should you avoid overbuilding?
The code is not the final word. The Commission and the AI Board still need to assess adequacy, and the Commission’s Article 50 guidelines are due before August 2, 2026. The FAQ also says systems placed on the market before August 2, 2026, benefit from a transitional period for relevant Article 50(2) and 50(4) compliance until December 2, 2026. That matters for existing products, but do not use it as a hammock.
There are 3 areas where overconfidence would be expensive.
One is detection. Machine-readable marking and provenance metadata help, but they are not magic truth serum. C2PA style credentials can record provenance, but downstream platforms, file conversions, screenshots, copy paste, and malicious edits can break the chain. Build a best effort pipeline and evidence trail. Do not promise perfect detection in sales copy.
The second is “public interest.” The guidelines should clarify scope, but your risk review should start now. A sports meme is different from an AI generated explainer about vaccine eligibility, election procedure, mortgage relief, or tax credits. If your product publishes informational text at scale, create a public interest classifier for workflow routing, but keep humans in the loop for edge cases.
The third is vendor reliance. If your model provider signs the code, that helps. It does not automatically label your user interface, preserve metadata through your CDN, or prove your editorial review process. The Commission’s policy page says signatories may use the code to demonstrate compliance, while non-signatories must show their measures are adequate. Either way, your deployer obligations follow your product.
The practical bet is not to build a giant compliance platform by July 1. Build the smallest system that gives you accurate provenance, consistent disclosure, and reviewable evidence:
- One inventory of AI output surfaces.
- One shared labelling component in the design system.
- One provenance record for every published AI output.
- One review workflow for public interest text.
- One export test for media labels and metadata.
That is not glamorous. Neither is authentication, billing, or backups. The boring layer is where products survive contact with institutions.
The label is the receipt
The EU’s AI content labelling playbook is easy to mock as sticker governance. That misses the shift. The label is only the receipt. The product now has to remember what it sold.
Sources
- European Commission: Commission publishes Code of Practice on marking and labelling AI-generated content
- European Commission: Code of Practice on Transparency of AI-Generated Content
- European Commission: Questions and answers about the Code of Practice on Transparency of AI-Generated Content
- European Commission: EU Icons for labelling AI-generated content
- AI Act Service Desk: Article 50 transparency obligations
- AI Act Service Desk: Article 99 penalties
- AI Act Service Desk: Article 113 entry into force and application
- C2PA: Content Credentials technical specification