The benchmark wars just found a more useful battlefield: agents that keep working after the first model call.
AgentPerf is a benchmark for concurrent AI agents, and its first published result says NVIDIA’s GB300 NVL72 can run up to 20x more agents per megawatt than Hopper. That is the sort of number that should make you pause before buying capacity based on single prompt throughput alone.
On June 12, 2026, Artificial Analysis launched AA-AgentPerf, a hardware benchmark that replays real coding agent trajectories instead of synthetic one shot prompts. NVIDIA then published its Blackwell result: GB300 NVL72 led the first round on DeepSeek V4 Pro, with up to 20x higher concurrent agent throughput per megawatt than an H200 system.
That claim does not mean every agent app just became 20x cheaper. It means the industry finally has a test that makes the serving problem look closer to what you are actually shipping: long context, repeated tool calls, KV cache reuse, disaggregated prefill and decode, and users who still get annoyed when the cursor blinks for too long.
If you are budgeting for coding agents, support agents, internal workflow bots, or anything that chains model calls across minutes instead of seconds, AgentPerf is a better starting point than the usual tokens per second brag sheet.
What did AgentPerf actually measure on Blackwell?
AgentPerf asks a simple buying question: how many simultaneous agents can this system keep alive while still hitting a usable service level?
The benchmark uses real coding agent trajectories. Artificial Analysis says those sessions run up to 200 turns, pass 100K tokens of sequence length, span 12 plus programming languages, and have input lengths from roughly 5K to 131K tokens with a mean around 27K tokens. That shape matters. A coding agent does not just answer. It reads files, edits code, calls tools, receives tool output, reasons again, and carries the growing context forward.
The lead metric is agents per megawatt. Artificial Analysis defines it as the maximum number of simultaneous agents served per megawatt of measured accelerator power while meeting output speed and time-to-first-token targets. The power normalization is GPU only, covering the GPU die plus HBM and excluding CPU, networking, and cooling overhead. That exclusion matters for facilities math, but it is still a cleaner comparison than “one rack was fast in a demo.”
NVIDIA’s strongest published result used GB300 NVL72 with TensorRT-LLM 1.3.0 release candidate infrastructure. Artificial Analysis’ public configuration page says the top GB300 run used 40 of 72 GPUs in a disaggregated layout: six context workers, one generation worker, NVFP4 precision, and expert parallelism of 16 for generation. The Hopper comparison used 8 H200 SXM GPUs with SGLang and tensor parallelism of 8.
The model is also a real stress test. DeepSeek’s own DeepSeek V4 Pro model card describes it as a mixture of experts model with 1.6 trillion total parameters, 49 billion activated parameters, and a 1 million token context length. DeepSeek also says the V4 series was pretrained on more than 32 trillion tokens. That is not a toy chat model pretending to be an infrastructure benchmark.
The chart below puts NVIDIA’s agent result next to two familiar MLPerf era comparisons. The point is not that these are identical tests. They are not. The point is that the agent serving benchmark shows a much larger gap than conventional single request inference comparisons, because it rewards rack scale scheduling, cache behavior, and the split between context processing and generation.
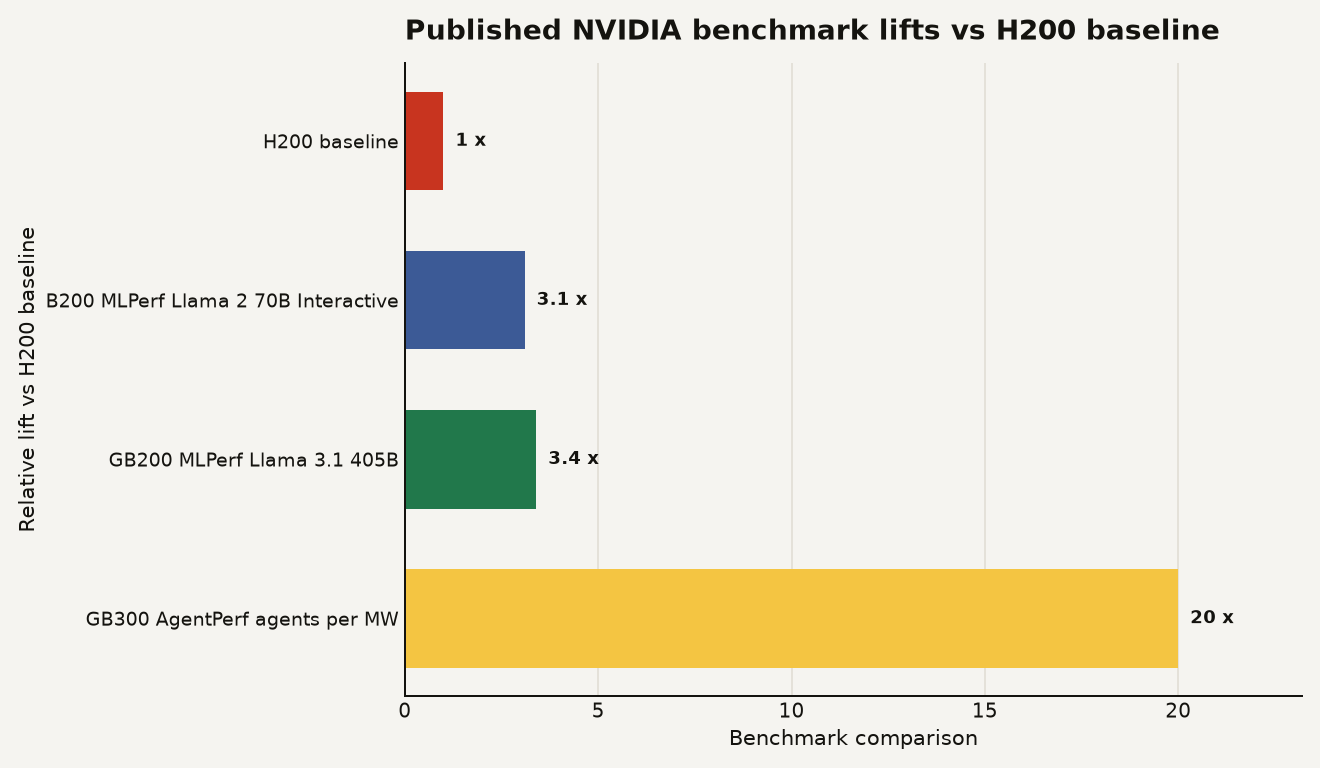
MLPerf is still useful. MLCommons said Inference v5.0 added Llama 3.1 405B and Llama 2 70B Interactive, with the 405B test supporting input and output lengths up to 128,000 tokens. NVIDIA reported GB200 NVL72 at 3.4x higher per GPU performance than H200 on Llama 3.1 405B server mode, and B200 at 3.1x higher throughput than H200 on Llama 2 70B Interactive. AgentPerf simply moves the target from “how fast can you serve requests?” to “how many working agents can you keep productive?”
That shift is overdue.
Why is the 20x number bigger than normal inference gains?
The easy answer is “Blackwell is faster.” The useful answer is that agents expose different bottlenecks.
A single chat completion mostly taxes prefill, decode, batching, and latency. An agent adds churn. It creates many short turns. It revisits old context. It waits on tools. It changes output length unpredictably. It benefits when the serving stack can reuse KV cache, route conversations with affinity, split context and generation work, and keep expert parallelism from turning into a coordination tax.
NVIDIA’s GB300 NVL72 is built for that style of work. The GB300 NVL72 platform spec lists 72 Blackwell Ultra GPUs, 36 Grace CPUs, 37 TB of fast memory, 130 TB per second of NVLink bandwidth, and 2,592 Arm Neoverse V2 CPU cores in one liquid cooled rack scale system. The same page says GB300 delivers 1.5x more dense FP4 Tensor Core FLOPS and 2x higher attention performance than Blackwell GPUs.
That is hardware. The benchmark result is also software.
The AgentPerf configuration tells the story. GB300 separated context workers from generation workers. It used NVFP4. It used speculative decoding with 3 next token prediction layers. It used FP8 KV cache settings. It used conversation affinity routing and disaggregated serving. Those are the knobs production inference teams already care about, which is why this benchmark is more interesting than another sterile throughput chart.
For builders, the practical consequences are blunt:
- If your app runs agents for 50 to 200 turns, you should capacity plan around sessions, not requests.
- If your main cost driver is tool heavy coding or analysis, tokens per second will understate the value of cache reuse and scheduler quality.
- If your inference vendor cannot explain its prefill and decode split, you are buying a black box with a nice logo.
- If you self host, the model serving framework is now part of your moat or your outage budget.
There is also a less cheerful implication. The gap between “we have GPUs” and “we can run agents well” is widening. A small team can rent H200s and serve a model. Running high concurrency agents with long contexts and steady responsiveness is a systems engineering problem. That problem includes GPUs, networking, memory, scheduling, model quantization, observability, and enough patience to debug tail latency at 2 a.m. without blaming the model.
That is why this result connects directly to the infrastructure pressure we have been tracking in AI’s energy and water accounting. Power is no longer a vague sustainability footnote. It is a product constraint. Agents make it worse because one user task can trigger dozens or hundreds of model calls.
What does this change for your roadmap and budget?
The first change is measurement. If you are building an agent product in 2026, “cost per million tokens” is no longer enough.
You need at least four numbers in every vendor conversation:
- Concurrent agent sessions at your target output speed.
- Time to first token at the 95th percentile, not the happy path.
- Agent task completion cost, including repeated turns and tool output.
- Power normalized throughput, especially if you are reserving dedicated capacity.
Artificial Analysis built AgentPerf around service level objectives derived from observed serverless API performance. The benchmark reports capacity at several output speed targets, including DeepSeek V4 Pro tiers such as 300 tokens per second, 100 tokens per second, and 30 tokens per second. That matters because most agent products do not need every turn to stream at maximum speed. A background refactor agent can tolerate a slower tier. A pair programmer cannot.
This is where product design meets infrastructure cost. If your agent UX blocks the user on every step, you need the expensive low latency tier. If your workflow can batch analysis, hide intermediate tool calls, and notify the user only when intervention is needed, you can buy capacity differently.
For a developer tools company, that might mean splitting plans by agent behavior instead of raw token allotments. A cheap tier gets slower background agents and smaller context windows. A pro tier gets interactive coding agents with higher output speed and longer preserved context. An enterprise tier gets reserved capacity and audit logs. Pricing follows the workload, not the marketing page.
For an internal enterprise deployment, the lesson is even more boring and more valuable: benchmark your own trajectories. A legal review agent, a data cleaning agent, and a code migration agent have different context growth, tool latency, and output length. AgentPerf gives you a public reference point, but your own logs decide whether GB300 class capacity pays back.
The second change is procurement. The 20x figure is a warning against comparing accelerators by sticker specs. GB300’s advantage in this test comes from a full stack: hardware, NVLink domain, memory, TensorRT-LLM, quantization, and serving topology. If a cloud provider offers “Blackwell” but not the topology or serving stack behind the benchmark, you should not assume the same economics.
Ask for the configuration. Ask whether disaggregated serving is available. Ask how KV cache is handled across turns. Ask whether the quoted GPU hour includes the parts AgentPerf excluded, such as CPUs, networking, and cooling. A megawatt in a benchmark is not the same as a megawatt on your utility bill.
What should you watch before betting on AgentPerf results?
Treat the first AgentPerf release as important, not final.
The benchmark is young. Artificial Analysis says results are live, open for submissions, and will expand beyond DeepSeek V4 Pro to gpt-oss-120b and additional models. It also says planned upgrades include trajectories up to 1 million tokens, broader hardware coverage, and tool execution performance. Today, tool calls are represented through simulated CPU processing time. That keeps the accelerator comparison cleaner, but it also leaves out a nasty part of real agent systems: sandboxes, package installs, test runs, database calls, browser automation, and flaky external APIs.
That caveat is not a dismissal. It is a roadmap for what to measure next.
Three checks should come before any large buying decision:
- Model match: DeepSeek V4 Pro is a strong open weight MoE model, but your production model may have different attention, context, and expert behavior.
- Trace match: Coding trajectories are valuable, especially for builders, but sales, support, finance, and research agents may stress the stack differently.
- Facility match: AgentPerf’s per megawatt metric uses accelerator power, while your data center bill includes CPUs, networking, cooling, power conversion, and idle overhead.
The next wave will be more telling if AMD, cloud providers, and inference startups submit optimized configurations. Artificial Analysis already lists MI355X configurations alongside H200, B300, and GB300 entries. A single vendor victory lap is less useful than a messy leaderboard where software stacks improve every month.
For now, the actionable read is this: use AgentPerf to reset your mental model. Agent infrastructure is not chat infrastructure with a bigger context window. It is a long running systems workload where scheduling, memory, and power decide margins.
If your roadmap assumes “agents get cheaper because models get cheaper,” update the spreadsheet. The model price is only one line item. The agent tax lives in concurrency, context, tool loops, and the infrastructure that keeps all of it responsive.
The benchmark finally follows the workload
The industry spent two years measuring AI like users ask one question and go home. Agents do not go home. They keep opening files.
Sources
- Artificial Analysis: First results from AA-AgentPerf
- Artificial Analysis: AI hardware benchmarking and performance analysis
- Artificial Analysis: Inference serving configurations
- NVIDIA Developer Blog: NVIDIA achieves leading agentic coding performance on first agentic AI benchmark
- NVIDIA: GB300 NVL72 platform specifications
- DeepSeek: DeepSeek V4 Pro model card on Hugging Face
- MLCommons: MLPerf Inference v5.0 results announcement
- NVIDIA Developer Blog: Blackwell MLPerf Inference v5.0 results