Dataset: the per-model energy figures here are measured and published openly on the University of Michigan ML.Energy leaderboard, which anyone can download and re-run.
Run a small open model on a laptop, generate a full email, and the battery barely moves. So when a headline says that same email "drinks a bottle of water," the skepticism is earned. The measured numbers mostly back it up.
The distinction the scary headlines usually blur is the one that matters. Training is the one-time, brutally expensive process of building a model. Inference is what happens every time someone uses it: a prompt goes in, the model answers. The two have completely different cost profiles, and almost every viral "AI is boiling the oceans" statistic quietly mixes them up. The number worth remembering is that a median Gemini text prompt now uses about 0.24 watt-hours of electricity and 0.26 milliliters of water, roughly five drops.
How much does one text prompt actually cost?
Three independent sources now put a single text prompt in the same small range.
Google published a measurement methodology in August 2025 and put the median Gemini text prompt at 0.24 watt-hours of energy, 0.03 grams of CO2 equivalent, and 0.26 milliliters of water. That figure is the comprehensive one: it includes idle backup machines, host CPUs and RAM, and data center cooling overhead, not just the chip doing the math. Stripped down to active-chip-only, the way many alarming estimates are calculated, Google's number falls to 0.10 watt-hours. The company framed the full figure as the energy of watching television for under nine seconds.
OpenAI's Sam Altman, writing in mid-2025, said the average ChatGPT query uses about 0.34 watt-hours and roughly 0.000085 gallons of water, which is about 0.32 milliliters, or one fifteenth of a teaspoon. The research group Epoch AI, working bottom-up from chip specifications, landed at about 0.3 watt-hours for a typical GPT-4o query, explicitly ten times lower than the widely repeated 3 watt-hour estimate first floated by Alex de Vries in 2023.
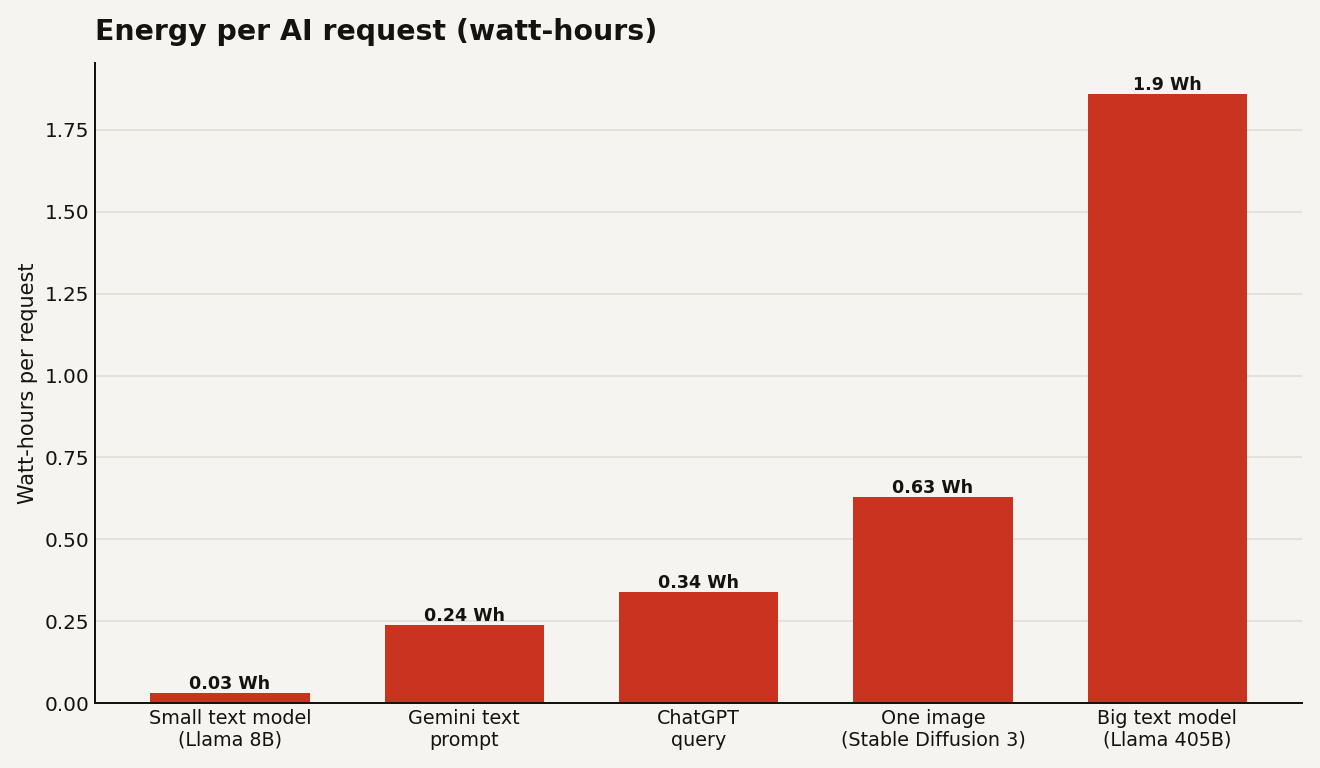
Model size drives most of the spread. Working with the University of Michigan's ML.Energy team, MIT Technology Review measured Meta's open Llama models on a range of prompts. The small Llama 3.1 8B needed about 114 joules per answer, the energy of running a microwave for a tenth of a second. The fifty-times-larger Llama 3.1 405B needed about 6,706 joules, or roughly eight seconds of microwave time. Same task, very different bill, depending on which model serves it.
So where did "a bottle of water per email" come from?
That line is not invented, but it is a worst case wearing a headline. It traces to a September 2024 Washington Post collaboration with the University of California, Riverside, which estimated that GPT-4 writing one 100-word email could consume up to 519 milliliters of water, about a 16-ounce bottle, in a hot-climate Texas data center, and as little as 235 milliliters elsewhere.
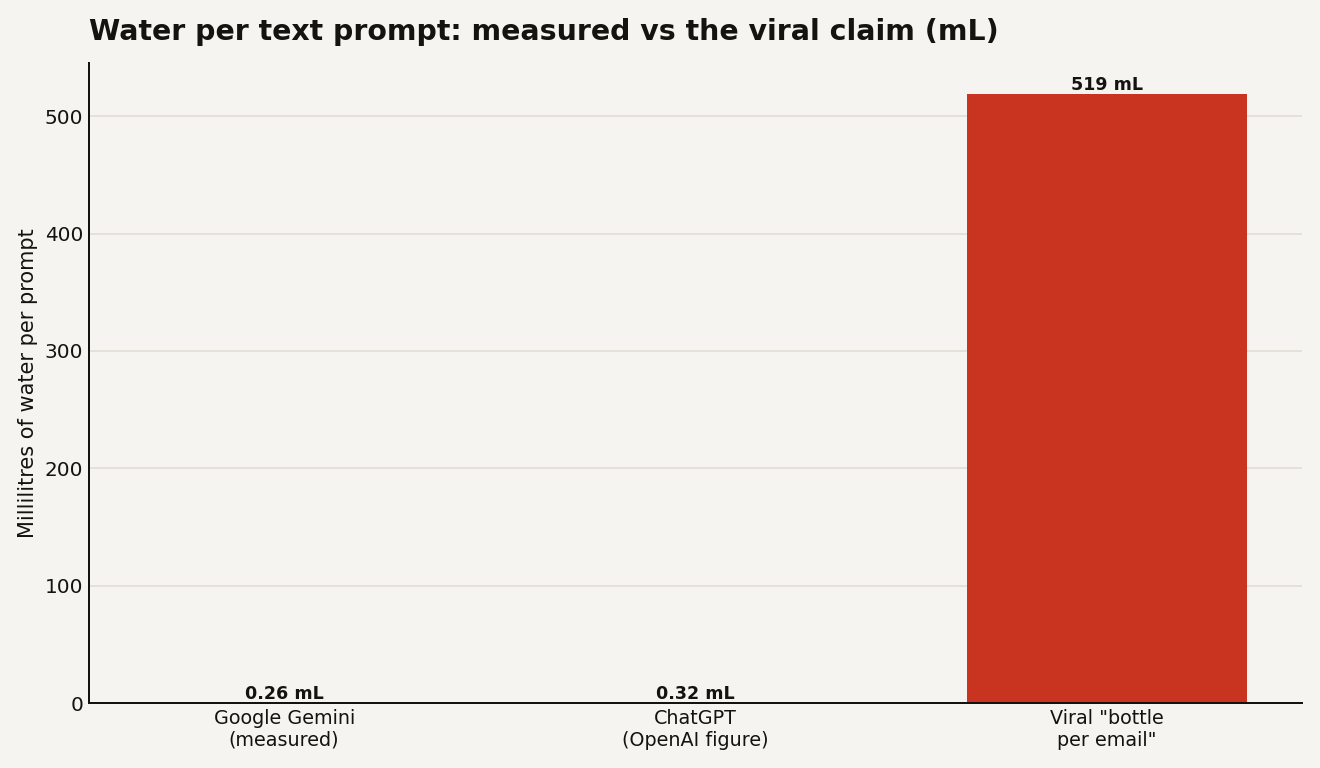
Next to Google's measured 0.26 milliliters, the gap is roughly two thousand times. Both figures can be defended, and the difference is instructive. The bottle figure stacks several pessimistic choices at once: a long answer, an older and larger model, a thirsty region, and, importantly, both kinds of water. Data centers consume water two ways: directly, by evaporating it in cooling towers, and indirectly, because the power plant feeding them also consumes water to make electricity. The team behind the bottle estimate spelled out that off-grid water cost in its paper Making AI Less Thirsty. Add a region where the grid and the cooling are both water-hungry and the worst case balloons. Google's number is a fleet-wide median with best-in-class cooling efficiency behind it. The truth for a normal prompt sits far closer to a few drops than to a bottle.
Does generating an image or a video cost more?
Yes, and this is where the laptop intuition starts to bend. Image models use a different, diffusion-based architecture, and the energy does not depend on the prompt's content. A skier on sand dunes and an astronaut farming on Mars cost the same; what matters is resolution and the number of diffusion steps.
MIT Technology Review measured a standard 1024-pixel image from Stable Diffusion 3 Medium at about 2,282 joules, or 0.63 watt-hours, and roughly double that at higher quality. That is more than a small text answer but still less than the largest text model. Hugging Face's wider study, Power Hungry Processing, found image generation averaging 2.9 watt-hours per image across many models, with the most carbon-intensive emitting about 1.6 grams of CO2 each, the equivalent of driving 4.1 miles for every 1,000 images.
Video is the real outlier. A single five-second clip from the open CogVideoX model took about 3.4 million joules, near 944 watt-hours, more than 700 times a high-quality image and enough to run a microwave for over an hour. The cost ladder is consistent: classifying text is nearly free, generating text costs a little, generating pixels costs more, and generating moving pixels costs a lot.
| AI action | Energy | Everyday equivalent |
|---|---|---|
| Small text model answer | ~0.03 Wh | Microwave for 0.1 second |
| Gemini text prompt | 0.24 Wh | Watching TV for under 9 seconds |
| ChatGPT query | 0.34 Wh | An oven running for about 1 second |
| One standard image | ~0.63 Wh | Microwave for about 3 seconds |
| Large text model answer | ~1.86 Wh | Microwave for 8 seconds |
| Five-second AI video | ~944 Wh | Microwave for over an hour |
Is training really the expensive part?
The common intuition is half right. Training is genuinely enormous. Training GPT-3 is estimated to have used about 1,287 megawatt-hours of electricity, emitted roughly 552 tons of CO2, and evaporated around 700,000 liters of freshwater, according to the UC Riverside team that coined the "thirsty AI" framing and the Google and Berkeley analysis behind those energy numbers. GPT-4 reportedly cost over $100 million and burned through about 50 gigawatt-hours, enough to power San Francisco for three days.
But the next step breaks the "so inference must be near zero" logic. That training cost is paid once, then smeared across every prompt the model ever answers. Spread 1,287 megawatt-hours over the billions of queries a popular model serves, and the training share of any single prompt rounds to nothing. Epoch AI notes that a frontier training run draws about 20 to 25 megawatts for three months, comparable to the continuous power that ChatGPT inference already pulls every single day, except inference never stops.
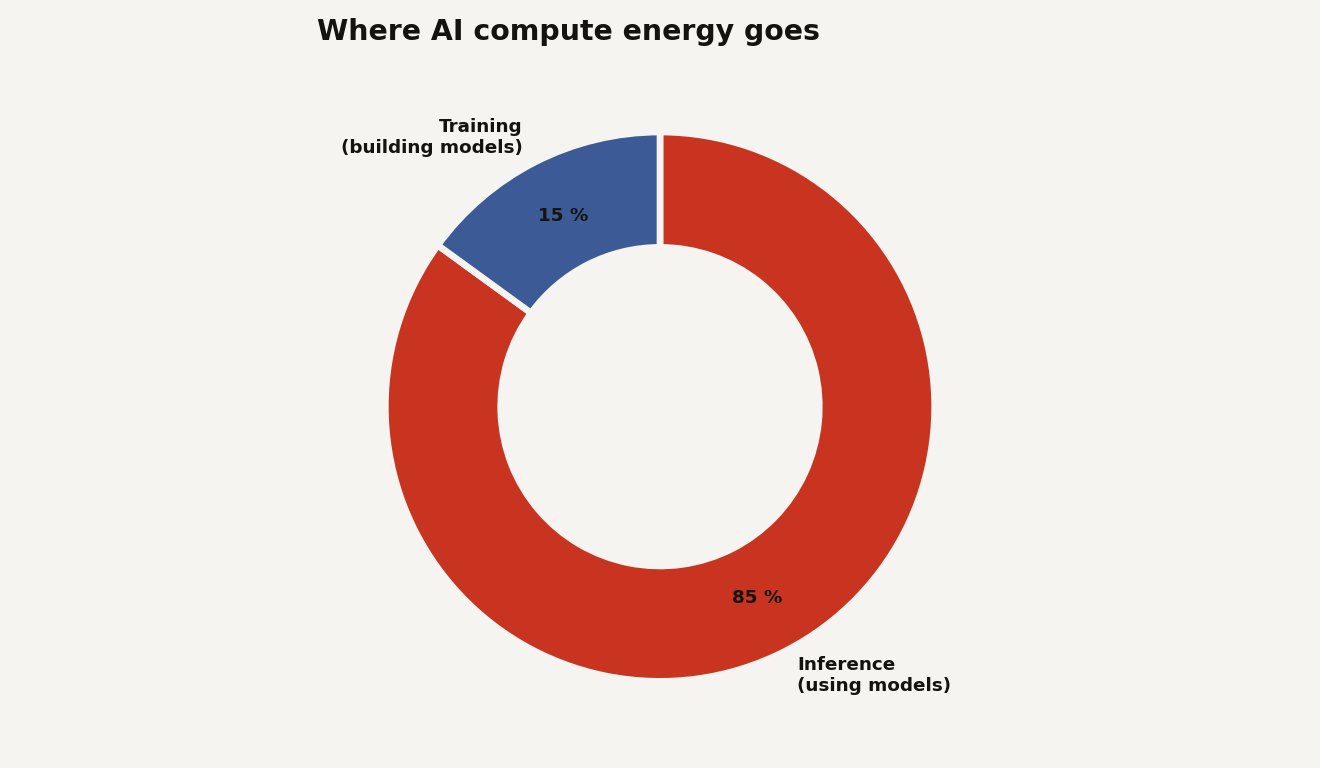
So the real answer is neither. Per use, inference is tiny and training is invisible. In aggregate, inference is the bigger number, somewhere around 80 to 90 percent of AI compute by industry estimates from AWS, precisely because it happens billions of times a day while training happens once. The cost is not hiding in a single expensive step. It is the multiplication. This is the same demand curve driving the gigawatt buildout behind AI infrastructure: not one giant training run, but relentless, always-on serving.
What about running models locally?
A local model is the cleanest case to reason about, because three things are true at once. The per-query energy really is tiny: a small model generating an email sits at the 0.03 watt-hour end of the chart. The direct water use really is near zero, because a laptop has a fan, not an evaporative cooling tower, and consumes no water on site; the only water involved is whatever the local power plant used to make the few watt-hours pulled from the wall. And local is not automatically greener per token: a laptop runs one request at a time on consumer silicon, while a hosted data center batches thousands of requests across purpose-built accelerators at a fleet power-usage efficiency near 1.09, meaning almost all the power reaches the chips.
- Per-query energy is tiny. A small local model answering an email is the cheapest bar on the chart.
- On-site water is effectively zero. No cooling tower means no evaporation; only the grid carries embedded water.
- Hosted is often more efficient per token. Batching and purpose-built accelerators beat a single laptop running unbatched.
The catch is that it is not the same model. A laptop runs an 8-billion-parameter model; ChatGPT may route a query to something a hundred times larger. The honest read: hosted AI is not secretly wasteful per prompt, and local AI is not magically free. Local is cheaper mostly because the model is smaller and the work is simpler, not because the cloud hides a swimming pool behind every answer.
What should builders and operators take from this?
For anyone shipping AI features, the footprint follows the same levers as the bill.
- Right-size the model. A 50x-bigger model can cost 50x the energy for a marginally better answer. Matching model to task cuts cost and carbon together.
- Mind reasoning and long context. Reasoning models can use up to 43 times more energy on a simple problem, and a 100,000-token input can push a single query toward 40 watt-hours. A chain-of-thought model pointed at a task a classifier would finish is pure waste.
- Location decides the carbon, not just the kilowatt-hours. The same 2.9 kilowatt-hours of AI work emits about 650 grams of CO2 on California's grid and over 1,150 grams in coal-heavy West Virginia.
- Watch the aggregate, not the prompt. A single call is harmless. Ten million users calling it hourly inside an always-on agent is a power plant.
The individual-guilt framing was always the wrong lens. One prompt costs a few drops of water and less electricity than a household fridge light burning for a minute. The thing actually reshaping grids is not a single email. It is a billion emails, plus images, plus video, plus agents that never sleep, all multiplied at a scale no one is fully disclosing yet.
Sources
- Measuring the environmental impact of AI inference, Google Cloud
- The Gentle Singularity, Sam Altman
- How much energy does ChatGPT use? Epoch AI
- The growing energy footprint of artificial intelligence, Alex de Vries, Joule
- We did the math on AI's energy footprint, MIT Technology Review
- Power Hungry Processing: Watts Driving the Cost of AI Deployment? Luccioni, Jernite and Strubell
- Making AI Less Thirsty, Li, Yang, Islam and Ren
- Carbon Emissions and Large Neural Network Training, Patterson et al.
- A bottle of water per email, The Washington Post
- ML.Energy leaderboard, University of Michigan