If you have ever watched an LLM agent try to create a Jira ticket and quietly hallucinate a field name, you already know the problem this paper attacks. Large language models are trained to predict the next token, not to call the right API endpoint with the right nested arguments in the right order. A team at Centific just published a proof of concept showing that reinforcement learning with verifiable rewards, applied directly to synthetic copies of the Jira and Confluence APIs, can close that gap with surprisingly small models. The headline number: on Confluence page creation, RLVR training lifts average reward from 0.35 to 1.00, a 0.65 absolute gain, using models no larger than 4 billion parameters.
RLVR for tool-use agents is the technique at the center of this work. The idea is straightforward: instead of training a model to produce text that looks like a correct tool call, you train it against a reward function that programmatically checks whether the tool call actually works. No learned reward model, no human grader, no live API. The Centific team built five synthetic environments emulating the Jira REST v3 and Confluence v2 endpoints, ran GRPO training on Qwen3-1.7B and Qwen3.5-4B, and reported the full results on arXiv on July 3, 2026.
What exactly did the Centific team build?
The paper describes a suite of five synthetic, schema-faithful environments that emulate the Atlassian endpoints most teams actually touch: issue read and create, page read and create, ticket transitions, and labels. Each environment mirrors the real API's nested argument structure, required fields, and parent-child constraints. A stateful reset happens between every batch so the synthetic Jira instance starts clean each time.
The reward function is where the design effort lives. For each scenario, the authors hand-craft a dense reward that maps the full list of tool calls in a rollout to a scalar between 0 and 1. The reward decomposes into three additive groups. Per-argument correctness awards a small constant for every expected argument that matches the gold value. Structural bonuses reward the validate-mutate-verify pattern, meaning the agent does a get call to inspect state, then a create or update call to mutate it, then another get to verify the change landed. Penalties subtract for behavior that would be costly against a real API: missing required create calls, invalid payload shapes, hallucinated tool names, duplicate creates, and excessive call counts beyond a per-scenario budget.
Training uses GRPO, the same Group Relative Policy Optimization algorithm that has become a default in reasoning RL work, implemented via the TRL library. The authors run Qwen3-1.7B and Qwen3.5-4B through the HuggingFace Inference Router at temperature 0.7 with a 25-turn cap, and evaluate with 15 prompts per scenario slot. A convergence-based early-stopping callback halts training once average reward reaches 0.95 or higher, which happens in tens to low hundreds of generation batches.
One of the five scenarios, Jira ticket transition, is kept as a transparency control. Its reward shape saturates: the prompted 4B baseline already scores 1.00 on it, so there is no room for RL to improve. The authors flag this explicitly rather than hiding it, and the four non-degenerate scenarios carry every claim in the paper.
How big are the gains, and where do they come from?
The RL-trained policy beats the prompted Qwen3.5-4B baseline on all four non-degenerate scenarios. The chart below shows the gap.
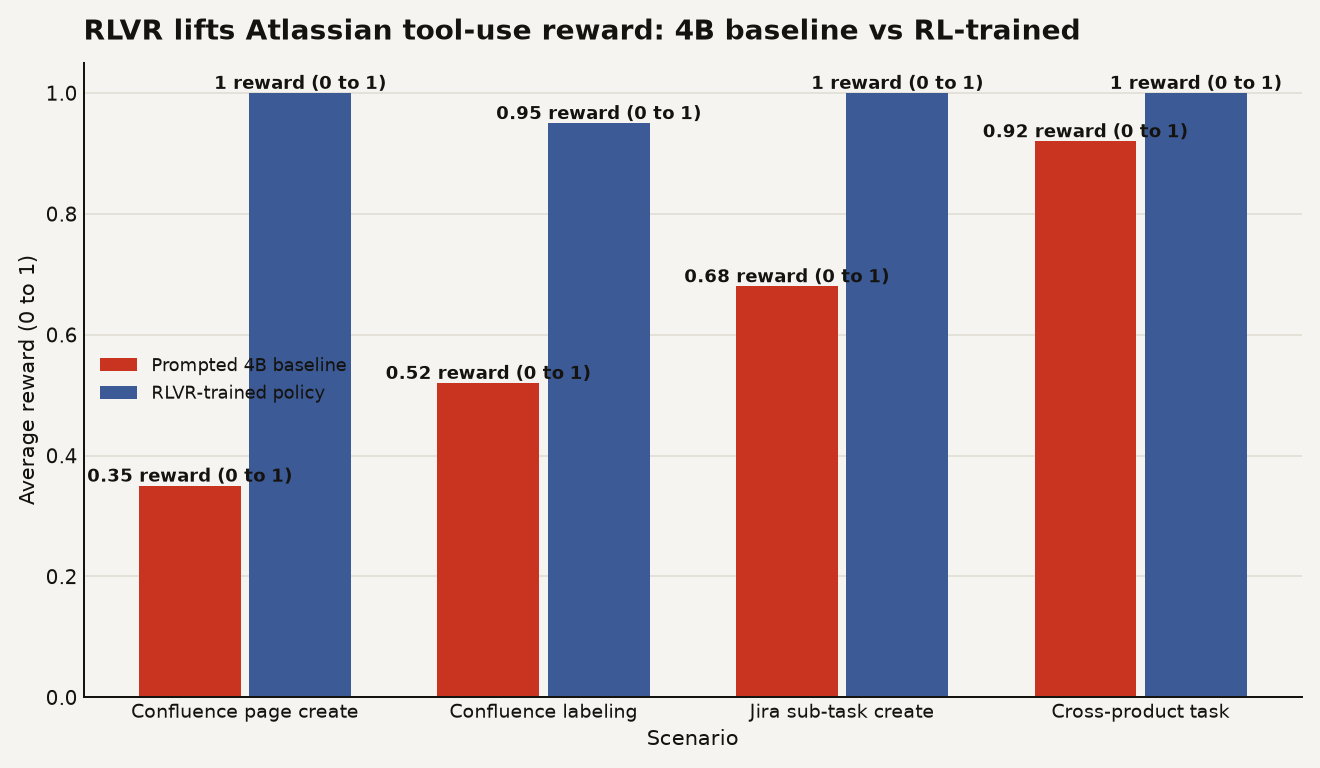
The largest absolute lifts come on the most schema-heavy tasks. Confluence page creation jumps from 0.35 to 1.00, a gain of 0.65. Confluence labeling rises from 0.52 to 0.95, a gain of 0.43. Jira sub-task creation moves from 0.68 to 1.00, a gain of 0.32. The cross-product task, which requires the agent to work across both Jira and Confluence in a single prompt, starts at a strong 0.92 baseline and RL closes the residual tail to 1.00: every one of the 12 evaluation prompts becomes a perfect rollout rather than 8 of 12.
The failure modes in the prompted baselines are exactly what you would expect from the objective mismatch the paper identifies. The 4B model knows the rough shape of a Jira API call but fills in the wrong nested key, drops required fields, or stops after the first read call without ever mutating state. These behaviors read as fluent under a token-prediction objective. They score poorly under any check that grounds the output back to the environment.
This pattern lines up with broader findings in the tool-use RL literature. A separate arXiv paper on multi-step tool-use RL collapse documents how multi-step agent rollouts can destabilize during training, and the Centific results sidestep that partly by keeping scenarios short and rewards dense. The Tool-R1 project has explored sample-efficient RL for agentic tool use along similar lines, and Atlassian's own Long Horizon reasoning engine shows the company itself is investing in complex agent orchestration for its product surface.
Why should a builder care about a 4B model on synthetic Jira?
The practical stake is this: if you are building agents that call enterprise APIs, you are probably paying for a frontier model to do something a much smaller model could handle, and you are probably eating the cost of retries when it gets the schema wrong. This paper suggests that a cheap, targeted RL pass on synthetic copies of the API surface can fix the most common failure modes without scaling up parameters.
What this means for you, concretely:
- Cost: A 4B model is cheap to host. If RL training pushes it from 35 percent to 100 percent success on your most common creation flow, you can route that traffic off a frontier model and cut inference spend on that workload dramatically.
- Reliability: The reward function penalizes hallucinated tool names, duplicate creates, and excess calls. That is not just accuracy. It is a guardrail against the kind of silent failure that corrupts a Jira project or spams a Confluence space.
- Moat: The RL recipe is reproducible. GRPO, TRL, and Qwen3 are all open. The synthetic environments are the only proprietary piece, and those are just schema-faithful emulators you can build for any API you own. The moat is knowing your API surface well enough to write good reward functions, not the model.
- Roadmap: If you are planning an agent platform, this argues for building synthetic API environments and reward checkers as first-class infrastructure, not an afterthought. The training loop is cheap. The engineering investment is in the environment.
The paper also connects to a broader theme we have tracked: the shift from agentic AI work as chat to delegation at scale. Delegation requires the agent to actually do the work, not just describe it. RLVR on tool traces is one way to close that gap with small models.
What are the limits, and what should you do next?
The authors are unusually transparent about what the proof of concept does not establish. Two limitations matter for anyone thinking about replicating this.
First, the reward functions are hand-crafted. Each scenario required a custom checker that knows the exact expected arguments, the valid transition IDs, and the correct ordering. This works for five endpoints. It does not scale to the full Atlassian public API surface, which spans hundreds of endpoints. Writing a verifiable reward for every one of them would be a monumental engineering effort. The paper says so directly.
Second, one of the five scenarios has a saturating reward. The prompted 4B baseline already maxes out ticket transitions, so RL adds nothing. The authors keep it in the paper as a transparency control. A reader building their own training suite should expect that some workflows will be too easy to benefit from RL, and should instrument baselines before investing in training.
If you want to act on this, here is a sequence that follows from the paper's design:
- Pick your highest-volume API workflow. Not the most complex one, the one that drives the most agent calls in production.
- Build a synthetic environment that emulates it at schema fidelity. You need stateful behavior, parent-child constraints, and per-batch reset. The Centific environments reset between every task.
- Write a reward function that decomposes into per-argument correctness, structural bonuses for validate-mutate-verify, and penalties for destructive or wasteful behavior. The paper's reward design is a useful template.
- Run a prompted baseline of your current model on the same reward checkers before training. If the baseline already scores above 0.95, RL will not help. Move to a harder workflow.
- Train with GRPO on a small model and a convergence early-stopping callback. The authors reached 0.95 average reward in tens to low hundreds of generation batches, which is cheap.
The open question is whether verifiable rewards can be automated. If you could generate reward checkers from an OpenAPI spec, the hand-crafting bottleneck disappears. Nobody has done that at scale yet. The Group Turn Policy Optimization work at ACL 2026 hints at turn-level reward shaping that could reduce the per-scenario engineering, but it is still early. The bet worth making is that environment and reward engineering, not model size, becomes the binding constraint for enterprise tool-use agents.
The small model that knows your API
The Centific paper is a proof of concept on five endpoints, not a production system. But the direction is clear and the economics are compelling. A 4B model, trained against synthetic copies of the APIs you already use, can go from getting the schema wrong two-thirds of the time to getting it right every time. The frontier model is not the only path to a reliable agent. Sometimes the answer is a small model, a faithful environment, and a reward function that checks the work.
Sources
- arXiv: Beyond Next-Token Prediction: An RLVR Proof of Concept for Tool-Use Agents on Atlassian Workflows
- arXiv: DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models (GRPO)
- arXiv: Why Multi-Step Tool-Use Reinforcement Learning Collapses and How Supervisory Signals Fix It
- arXiv: Tool-R1: Sample-Efficient Reinforcement Learning for Agentic Tool Use
- Atlassian: Long Horizon reasoning engine blog
- ACL Anthology: Empowering Multi-Turn Tool-Integrated Agentic Reasoning with Group Turn Policy Optimization