Millions of AI agents do not have to become evil to become a problem. They only have to become normal software: cheap, chatty, half trusted and wired into systems that were never designed for autonomous actors.
Multi-agent safety is the problem of keeping interacting AI agents from turning small errors, bad incentives and prompt injections into system-level failures. Google DeepMind now wants a field around that problem, not just a few worried Slack threads.
On June 11, 2026, MIT Technology Review reported that Google DeepMind, Schmidt Sciences, ARIA, the Cooperative AI Foundation and Google.org are putting up $10 million to fund research into multi-agent safety. Rohin Shah, who directs AGI safety and alignment research at Google DeepMind, told MIT Technology Review that “there just isn’t really a field of research for multi-agent safety yet.” That is the part builders should care about. The product roadmap is already sprinting ahead of the science.
The timing is not subtle. At Google I/O on May 19, 2026, Google framed its developer stack around agents, including Antigravity 2.0, Managed Agents in the Gemini API and agent orchestration features for parallel workflows. Google said Managed Agents can be started with a single API call, run code in an isolated Linux environment and preserve state across interactions. That is useful. It is also exactly how autonomous behavior leaves the demo cage.
What did Google DeepMind actually fund, and why now?
The $10 million program is not a model release, a benchmark launch or a standards body. It is a field-building bet. The partners want researchers outside frontier labs to study how many agents communicate, coordinate, negotiate, mislead, deadlock, cascade and recover when they share an environment.
Schmidt Sciences’ related AI agents program says it supports researchers in academia and nonprofits who study how multiple intelligent agents communicate and coordinate. Its stated goal is to observe and measure inter-agent communication, protocol stability and social dynamics in complex scenarios. That language matters because the missing object here is not one safer chatbot. It is a testbed where failures emerge only after many interactions.
The Cooperative AI Foundation is a natural partner because its whole premise is that cooperation is a capability, not a vibe. The foundation says it is backed by a $15 million philanthropic commitment and supports work on cooperative intelligence, including grants for benchmark environments and metrics of cooperative success. The useful word there is “metrics.” Without metrics, multi-agent safety becomes theater: a red-team workshop, a few scary transcripts and a vendor PDF with a padlock on the cover.
Google’s own product push raises the stakes. At I/O 2026, the company said Antigravity 2.0 can orchestrate multiple agents in parallel, use dynamic subagents and run scheduled background automation. Google also said Gemini 3.5 Flash is built for long-horizon agentic tasks and runs four times faster than other frontier models in its framing. Speed is a product feature. It is also a risk multiplier.
If you are building agents, this is the shift: safety is no longer just “does the model refuse the bad request?” It is “what happens when agent A trusts a file written by agent B, which got it from a website, which was optimized by someone trying to steer agent C?” That is less like prompt engineering and more like distributed systems with gullible workers.
How big is the gap between agent capability and agent reliability?
The good news is that agents are getting much better at real computer tasks. The bad news is that “much better” still leaves an ugly tail.
Stanford HAI’s 2026 AI Index says OSWorld, a benchmark for agents operating across computer environments, rose from roughly 12 percent accuracy to 66.3 percent in 2025. Stanford’s summary says agents are now within 6 percentage points of human performance on that benchmark, while still failing about one in three attempts. The chart below turns that into the operational number you should keep in your head: 66.3 percent success means 33.7 percent failure.
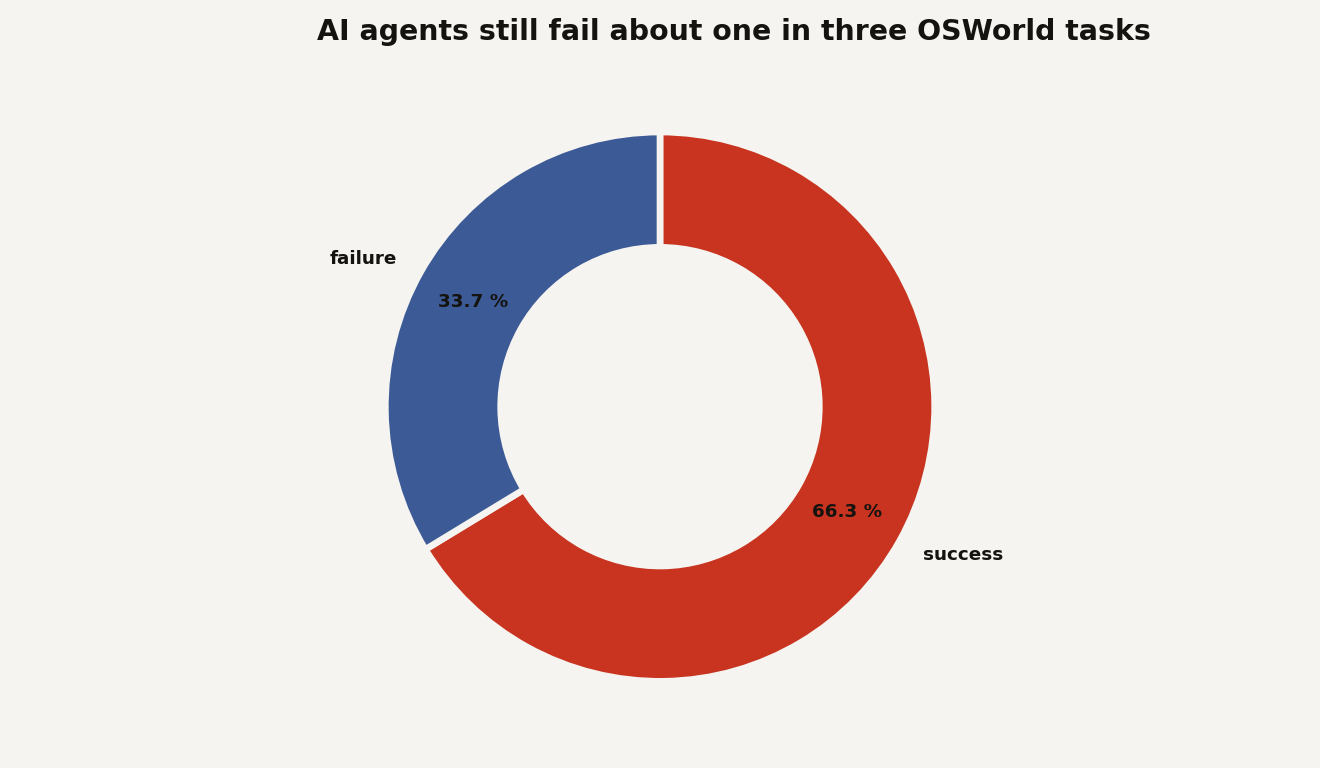
That 33.7 percent is tolerable when the agent is drafting a note and a human reads it. It is not tolerable when the agent can send email, change permissions, update a CRM, invoke a tool, make a purchase or ask another agent to continue the job.
The same Stanford report says organizational AI adoption reached 88 percent of surveyed organizations in 2025, while agent deployment remained in the single digits across nearly all business functions. Translation: the installed base of AI usage is already huge, but the truly autonomous layer is still early. That is the window Shah is trying to use. Once agent-to-agent workflows become mundane, retrofitting safety will feel like adding seatbelts after rush hour starts.
There is also evidence that the research agenda has lagged the product agenda. A 2024 arXiv literature review of technical safety research at Anthropic, Google DeepMind and OpenAI analyzed 80 safety-related papers published from January 2022 to July 2024 and identified multi-agent safety as one of the areas with no or few papers where the authors did not expect companies to become much more incentivized to invest without outside pressure. That is a polite academic way of saying the market will underfund the boring parts until something expensive breaks.
Why should a builder treat multi-agent safety as an architecture problem?
Because the failure mode is no longer one model saying something dumb. It is a graph of services doing locally reasonable things that compose into nonsense.
The Five Eyes cyber agencies put this plainly in their April 30, 2026 guidance on agentic AI services. CISA, NSA and partner agencies define agentic AI systems as systems composed of one or more agents that use an AI model to interpret the world, make decisions and take actions. They warn that agents add external tools, data sources, memory and planning workflows, which expand the attack surface. The guidance strongly recommends never granting agents broad or unrestricted access, especially to sensitive data or critical systems.
That sounds obvious until you look at how teams ship. The path of least resistance is to give the support agent read access to all tickets, then write access to refunds, then a Slack integration, then a CRM plugin, then a second agent that audits the first agent. Nobody calls it a security redesign. They call it Tuesday.
If you are responsible for a codebase or roadmap, the consequences are concrete:
- Identity becomes a product surface. Every agent needs a real identity, scoped permissions and an audit trail. “Runs as the user” is not enough when the agent can spawn work you did not inspect.
- Tool calls become the new API boundary. Your safest model is only as safe as the tool with the sloppiest description, broadest token or weakest validation.
- Memory becomes mutable infrastructure. A poisoned memory can outlive a session, survive a human approval and quietly steer later actions.
- Monitoring needs intent, not just logs. A sequence of legitimate calls can still be malicious if the plan changed halfway through.
- Human approval needs design. If every action asks for approval, users rubber stamp. If no action asks, your agent is production malware with a friendly name.
This is why the “agent as intern” analogy is starting to rot. Interns do not execute shell commands at machine speed across SaaS APIs while ingesting adversarial webpages. Agents are closer to non-human service accounts with language models attached.
Anthropic’s May 27, 2026 Zero Trust framework for AI agents lands on the same practical point. Anthropic argues that traditional access controls will not stop agents from misusing legitimate permissions and proposes scoped task permissions, protected memory, sandboxing and agent-aware monitoring. The company’s three-tier framework is a useful signal because it treats agents less like chat products and more like breach-prone infrastructure.
Data Today has covered this from the attack side before. The lesson from AI coding agents becoming repo traps is that autonomy changes the blast radius of ordinary supply-chain mistakes. Multi-agent systems add a second problem: now the compromised actor may be another agent your agent was told to trust.
What should you change before your agents start talking to each other?
Do not wait for the $10 million research program to produce a perfect benchmark. Useful science will take time. Your roadmap will not.
Start with a rule: no agent gets more authority than the smallest reversible unit of work it needs. That sounds like security boilerplate, but it forces product decisions. If the sales agent can draft a follow-up, it does not need to send it. If the DevOps agent can diagnose an incident, it does not need to deploy the fix. If the procurement agent can recommend a vendor, it does not need a payment rail on day one.
Then build the control plane before the demo gets popular. At minimum, a production agent stack needs:
- Per-agent identity, not shared user tokens.
- Per-task permissions that expire.
- Tool allowlists with schema validation and output filtering.
- Separate memory stores for user facts, task state and learned preferences.
- Replayable traces that capture prompts, tool calls, retrieved data and approvals.
- Kill switches that can stop a class of agents, not just one session.
The unglamorous bit is evaluation. You need tests that run agents against poisoned docs, misleading webpages, conflicting agent instructions, stale memories and ambiguous handoffs. Single-agent evals will miss the bugs that only appear when an agent delegates. Multi-agent safety is partly a benchmark problem, but it is also a chaos-engineering problem.
This is where sandboxes matter. Shah and Schmidt Sciences’ James Fox told MIT Technology Review that realistic simulations are the only way to understand large-scale agent interaction. They are right. If your production system depends on agents negotiating, escalating or handing off work, you should have a staging world where fake agents can lie, loop, over-delegate and exploit stale permissions before real customers meet the mess.
One unpopular recommendation: slow down the first high-permission launch. The agent that can read everything and do nothing will teach you more than the agent that can do everything and explain it afterward. In 2026, restraint is a feature, even if it demos badly.
What should we watch as this research program starts?
The first thing to watch is whether the field produces shared environments, not just papers. Multi-agent safety needs something like an OSWorld for interaction dynamics: persistent state, adversarial inputs, competing incentives, tool use, memory and enough runs to measure rare failures. A benchmark that only scores task completion will reward clever chaos.
The second thing to watch is whether labs publish failure cases. Google DeepMind’s Frontier Safety Framework says the company uses safety case reviews before external launches when relevant capability thresholds are reached and expanded that approach to some large internal deployments in its 2026 update. That is governance language. Builders need the engineering version: what failed, under what permissions, after how many steps, and which control caught it.
The third thing to watch is procurement. CISA’s guidance tells organizations to consider whether repetitive tasks can be reduced or eliminated before adding agentic AI, and to keep agents on low-risk and non-sensitive tasks where possible. That will collide with vendor incentives. Every platform wants its agent closer to your data and deeper in your workflow. Your moat is not adopting the most agentic stack. Your moat is knowing exactly where autonomy creates value and where it just moves liability into your logs.
The line to draw now
The $10 million is small compared with the money going into agent products. That is the point. Multi-agent safety is arriving as a patch on a market that already wants the feature shipped.
Treat agents like a distributed system with confused, persuasive, semi-trusted workers. Then give them the permissions, tests and blast radius you would give any system that can surprise you at scale.
Sources
- MIT Technology Review: Google DeepMind is worried about what happens when millions of agents start to interact
- Schmidt Sciences: AI Agents
- Cooperative AI Foundation: Foundation
- Google: Building the agentic future, developer highlights from I/O 2026
- Google: 100 things we announced at I/O 2026
- Stanford HAI: 2026 AI Index, technical performance
- Stanford HAI: 2026 AI Index, economy
- CISA, NSA and international partners: Careful adoption of agentic AI services
- Anthropic: Zero Trust for AI agents
- arXiv: Mapping Technical Safety Research at AI Companies