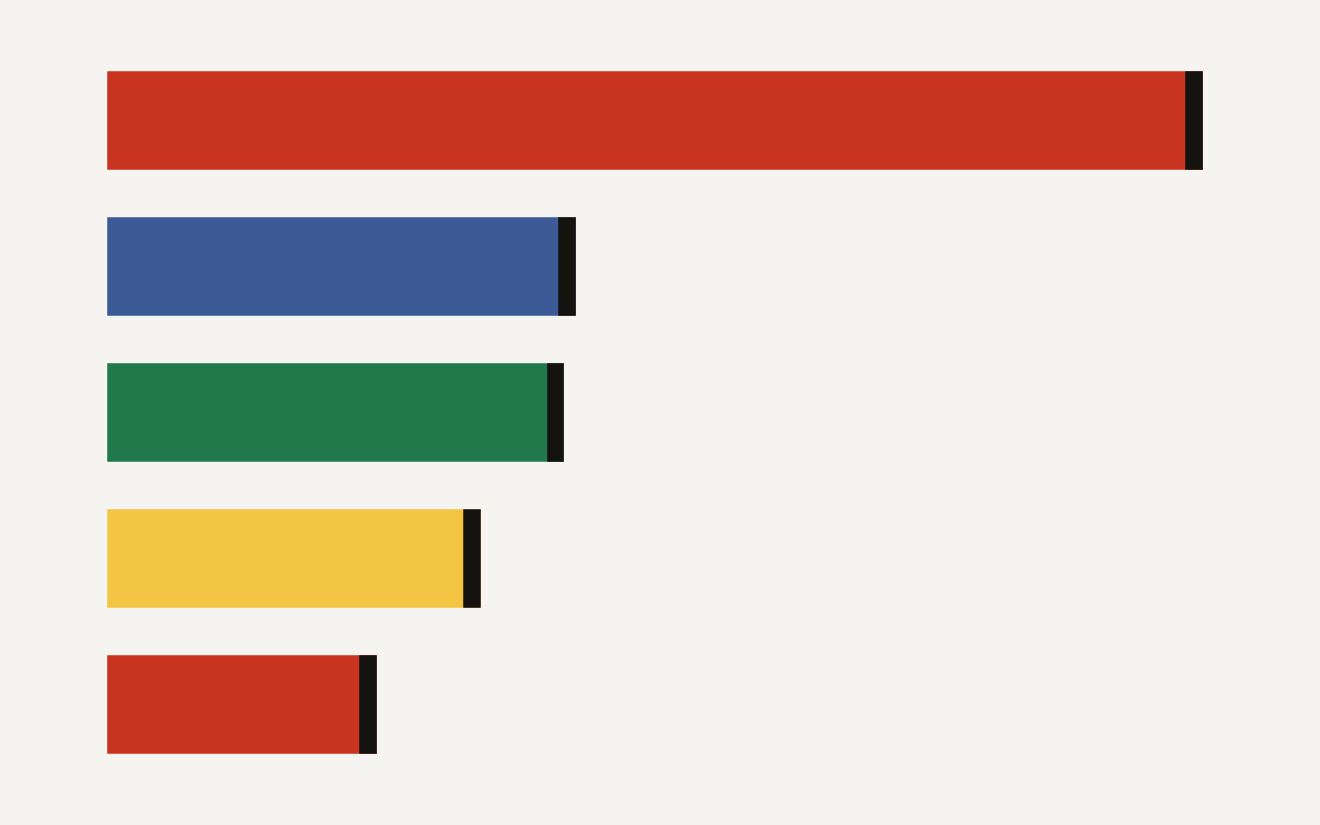
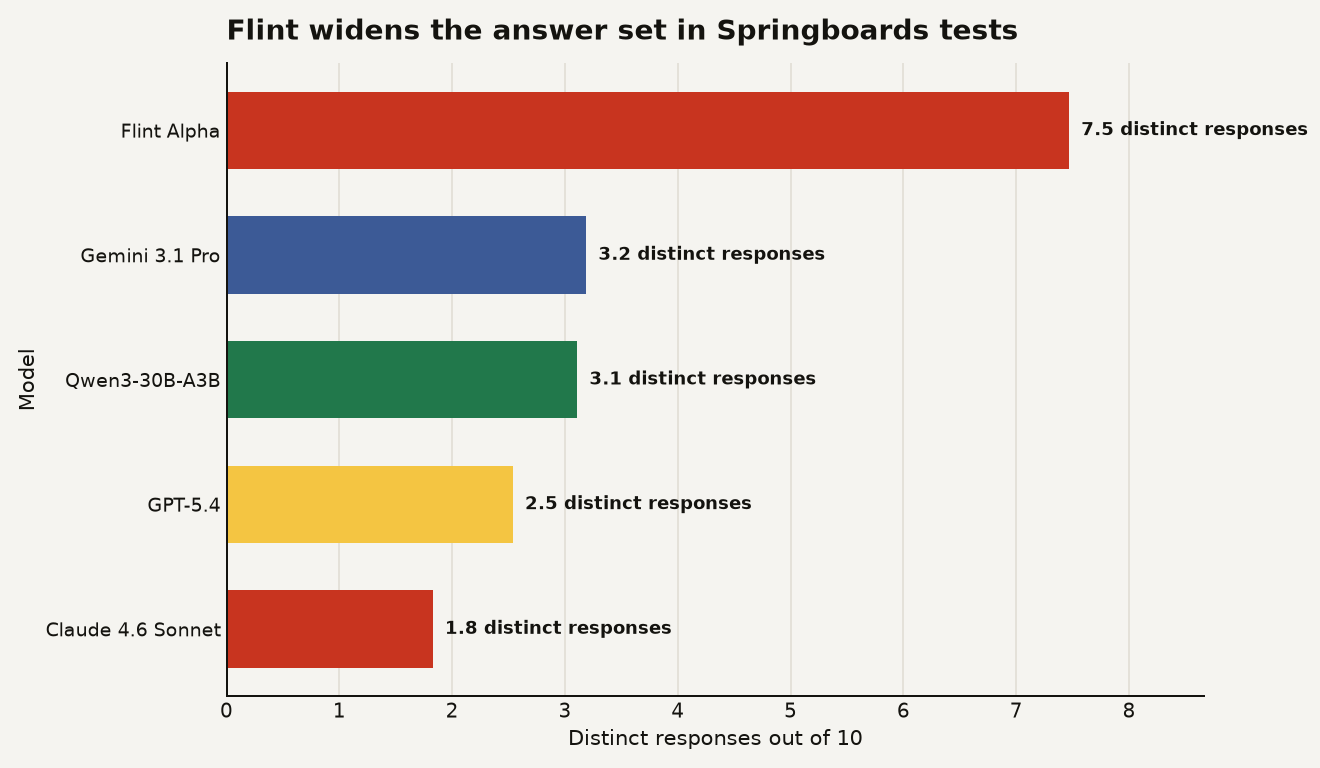
Ask three chatbots for a “random” number from 1 to 10 and you may get the most boring magic trick in software: 7, 7, 7. That little stunt is now a serious product argument. LLM groupthink describes the tendency of different language models to converge on the same safe answers, and Springboards says its new Flint model scores 7.47 distinct responses out of 10 on its NoveltyBench test, far above the 1.83 to 3.19 range it reports for several mainstream models in the same setup on its Flint Alpha results page.
The pitch is simple enough for a creative director and useful enough for a platform engineer: route accuracy work to models optimized for correctness, then route ideation work to a model trained to widen the search space. Springboards calls Flint a “divergence model,” and the MIT Technology Review story that surfaced it to a wider audience framed the product around a familiar complaint: models can feel personal while handing everyone the same starter pack of answers in Will Douglas Heaven’s July 1, 2026 report.
That matters beyond ad taglines. If your app uses an LLM to recommend names, plans, candidates, vendors, destinations, onboarding flows, product ideas, or research directions, sameness becomes a product property. Users may think they are exploring. Your system may be quietly steering them toward the modal answer.
What did Springboards actually build with Flint?
Springboards built Flint for the early part of creative work, where the job is to generate usable range before a human applies taste. The company says Flint Alpha is available through the Springboards app and is trained to raise entropy at “key moments” in a generation where multiple valid paths exist in its model note. That wording matters. The company is trying to avoid the obvious failure mode: turning the whole model temperature knob until the answer becomes noisy soup.
The base model choice is also practical. Springboards says Flint is built on Qwen3-30B-A3B, while Alibaba’s Qwen team describes Qwen3-30B-A3B as a mixture of experts model with 30 billion total parameters and 3 billion activated parameters in the Qwen3 release post. That is the sort of open-weight base a startup can realistically adapt without pretending it has frontier-lab training capital.
The company’s headline benchmark is NoveltyBench. It measures how many meaningfully distinct responses a model produces across 10 samples of the same open-ended prompt, according to Springboards on the Flint Alpha page. The reported gap is large enough to pay attention to, while still needing independent replication before anyone treats it as settled fact.
The chart below shows the company’s reported NoveltyBench scores: Flint at 7.47, Gemini 3.1 Pro at 3.19, Qwen3-30B-A3B at 3.11, GPT-5.4 at 2.54, and Claude 4.6 Sonnet at 1.83.
That is a product claim, not a public standard. Springboards also reports that Flint’s mean intra-model similarity is 0.721, versus 0.864 for GPT-5.4, 0.871 for Gemini 3.1 Pro, and 0.905 for Claude 4.6 Sonnet, with lower similarity meaning more variation in the same Flint Alpha results. Those numbers point in the same direction: Flint is designed to move sideways more often.
The useful read is narrower than the launch copy. Flint does not prove that “creative AI” is solved. It proves that model behavior can be tuned toward diversity as a first-class product goal, then measured with something more concrete than vibes.
Is LLM groupthink a real research problem or just a clever demo?
The research backdrop is stronger than the random-number parlor trick. A NeurIPS 2025 paper called “Artificial Hivemind” introduced Infinity-Chat, a dataset of 26,000 diverse, real-world, open-ended user queries intended to study prompts with many plausible answers and no single ground truth in the NeurIPS proceedings. The same abstract says Infinity-Chat includes 31,250 human annotations across ratings and pairwise preferences, with 25 independent human annotations per example in the paper abstract.
NeurIPS treated the work as important. The conference listed “Artificial Hivemind” among its 2025 Best Paper Awards and said the study covered “more than 70 models,” finding pronounced intra-model and inter-model homogenization in the official awards announcement. That makes the issue harder to dismiss as one startup’s marketing frame.
The mechanisms are plausible. Similar training data, similar instruction tuning, similar RLHF pipelines, similar benchmark pressure, and similar product incentives all push models toward answers that feel competent to the broadest audience. The strange part is that users often experience the result as individualized. A chat UI says “conversation.” The distribution says “consensus autocomplete.”
This is where the Data Today angle connects to earlier model behavior work. In our piece on LLM recommendation bias and brand advantage, the problem was that famous brands benefited when models defaulted to familiar names. LLM groupthink is the broader version of that same design tax: when a model lacks a strong reason to explore, it often lands on the already well-trodden answer.
OpenAI’s own prompt guidance gives the standard control knob, saying temperature measures how often a model outputs a less likely token and that higher temperature usually makes output more random and creative in its prompt engineering help page. Springboards’ counterargument is that global randomness is too blunt. You do not need every connective word to get weird. You need the destination, metaphor, brand angle, or concept choice to widen.
Why should builders care if models all pick the same idea?
Because sameness leaks into the interface, the roadmap, and the moat.
If your product sells “AI-powered strategy,” “AI-assisted discovery,” or “personalized recommendations,” LLM groupthink can quietly turn differentiation into a skin over the same suggestions everyone else gets. The user may not notice on the first run. They notice when the fifth tool proposes the same company name, the same travel plan, the same customer segment, or the same “Gen Z financial literacy app” dressed in slightly different copy.
The developer consequence is routing. You should stop treating one flagship model as the universal answer generator. A production stack can separate tasks by failure mode:
- Use low-temperature, high-reliability models for extraction, factual QA, code transforms, compliance checks, and structured operations.
- Use diversity-tuned models or multi-sample pipelines for naming, concept generation, research exploration, campaign territories, and product ideation.
- Use a judge, human reviewer, or retrieval-backed verifier after the divergent step, because novelty without selection just creates a bigger pile.
That split also changes cost. Generating 10 candidate responses for every open-ended prompt is expensive if you send all work to a large frontier model. A smaller divergence model can act as the cheap scout, while a stronger model acts as the editor. Qwen3’s own release post frames Qwen3-30B-A3B as a 30 billion parameter MoE model with only 3 billion activated parameters, which is exactly the kind of architecture that invites this scout-and-editor pattern in Alibaba’s Qwen3 documentation.
The business consequence is sharper. If your moat is taste, community, proprietary data, or workflow context, you cannot let the base model supply the creative center of gravity. The base model should propose options. Your product should decide what counts as interesting for your market.
A simple product review question helps: when your system generates five ideas, are they five directions or five phrasings? If the answer is mostly phrasings, your “brainstorming” feature is a formatting feature with better lighting.
What should teams do before adding a divergence model?
Start with measurement. You do not need to wait for a perfect benchmark to learn whether your own prompts collapse. Pick 50 representative open-ended prompts from production logs or user research, sample 10 outputs per prompt from your current model, and have domain reviewers label whether the outputs are meaningfully distinct. That gives you a crude NoveltyBench-style number for your own product surface.
Then separate novelty from quality. A response can be different and useless. Springboards says Flint keeps general capability close to its base model, reporting 81.5 percent accuracy for Flint versus 82.0 percent for Qwen3-30B-A3B on its per-subtask accuracy comparison in the Flint Alpha results. Treat that as a vendor claim to test, especially if your domain involves finance, health, law, procurement, or anything where a lively wrong answer creates real damage.
A sane evaluation loop has four gates:
- Diversity: How many outputs are meaningfully different, not paraphrases?
- Relevance: How many stay inside the user’s constraints?
- Usefulness: How many could a human reasonably develop further?
- Risk: How many introduce false claims, brand conflicts, privacy problems, or legal exposure?
For engineering teams, the implementation pattern is straightforward. Add a mode or objective field to your internal generation API: accurate, divergent, exhaustive, brand-safe, or cheap. Then route to different model settings, prompts, and evaluators. Do the boring plumbing now so product managers stop asking one model to be a calculator, strategist, lawyer, poet, and intern in the same call.
For founders, the hiring implication is uncomfortable in a good way. The more AI tools generate average ideas instantly, the more valuable editors, strategists, researchers, and domain experts become. You need people who can recognize the oddball worth keeping. Flint can widen the menu. It cannot taste the dish.
Where does the Flint bet go next?
The next phase should be independent benchmarking. Springboards has published useful numbers, but the field needs repeatable tests across open prompts, private business prompts, and user-specific preference data. The “Artificial Hivemind” paper gives researchers a stronger starting point because it defines open-ended query categories and human preference annotations at scale in the NeurIPS abstract.
Watch three signals over the next 12 months.
First, see whether frontier labs expose better diversity controls than temperature. If the only user-facing control remains a single randomness dial, startups like Springboards have room to build task-specific routing and tuning layers.
Second, watch whether creative software vendors start reporting distinctness metrics beside latency and cost. A brainstorming tool that cannot show range is selling a feeling. The better products will show how often they escape their own defaults.
Third, watch whether enterprise buyers ask for model diversity in procurement. If every department uses the same assistant with the same defaults, the organization may get operational consistency and strategic sameness in one bundled contract. That is efficient in the way beige carpet is efficient.
The caveat is real: many jobs benefit from convergence. If you are generating a refund policy summary, extracting invoice fields, writing migration notes, or checking code style, average is your friend. Maximilian Weigl of Uncommon told MIT Technology Review that “nine times out of 10 the average is fine,” which is probably the most commercially honest line in the whole story in the MIT Technology Review report.
That is the design principle: make average a choice. Do not let it be the hidden default for work that needs range.
The moat is moving from answer quality to answer spread
For the last three years, AI product teams have competed on whether the model can produce a good answer. The next useful fight is whether your system can produce a good spread of answers, then help the user choose.
LLM groupthink is a warning about monoculture in the idea layer. Flint is early, vendor-measured, and aimed first at marketers. Still, the underlying move is bigger than one creative tool. Builders should treat diversity as an observable system behavior, not a personality trait they hope the model has.
The chatbot that always picks 7 is funny once. In a product, it is a roadmap smell.
Sources
- MIT Technology Review: LLMs are stuck in a groupthink groove
- Springboards: Flint Alpha
- NeurIPS Proceedings: Artificial Hivemind
- arXiv: Artificial Hivemind
- NeurIPS Blog: Announcing the NeurIPS 2025 Best Paper Awards
- Qwen: Qwen3, Think Deeper, Act Faster
- OpenAI Help Center: Best practices for prompt engineering with the OpenAI API

