The most interesting thing about the new fastest supercomputer is what it leaves out. The LineShine supercomputer in Shenzhen reached 2.198 exaflops on the High Performance Linpack benchmark in June 2026, and TOP500 says it did it with CPUs only. For builders, that makes this more than a trophy update. It is a reminder that compute strategy is now a supply chain decision, a power decision, and a software portability decision at the same time.
LineShine matters because the usual story says serious frontier compute needs the newest accelerator stack. China just published a counterexample at the top of the most watched supercomputing list. The catch is just as important: the machine beats El Capitan on sustained double precision, but it burns far more power and trails the best US systems on mixed precision work that looks closer to modern AI. If your roadmap depends on GPU availability, this is the week to ask how much of your stack can survive a different architecture.
What did LineShine actually beat?
TOP500’s June 2026 highlights put LineShine at rank 1 with 2.198 exaflops of HPL performance, ahead of Lawrence Livermore National Laboratory’s El Capitan at 1.809 exaflops. That gap is 21.5 percent on the benchmark that decides the list, which is large enough to be a clean win rather than a rounding error.
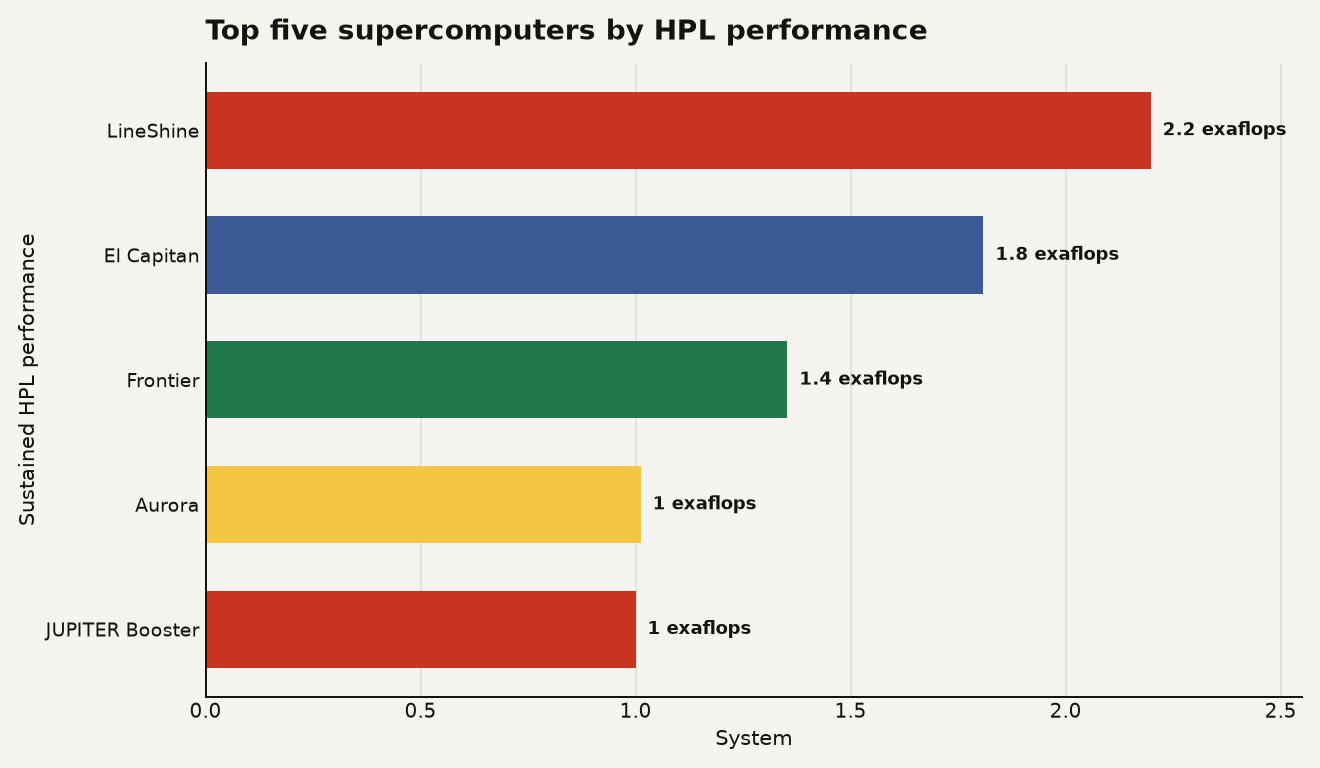
The chart below shows the top five systems by sustained HPL performance. LineShine leads at 2.198 exaflops, El Capitan follows at 1.809, Frontier is at 1.353, Aurora is at 1.012, and Europe’s JUPITER Booster is listed at 1.000.
The system entry gives the shape of the machine: TOP500 lists 13,789,440 cores, LX2 304C processors running at 1.55 GHz, the LingQi interconnect, Kylin OS, and 42,220 kW of measured power. That is roughly 45,360 LX2 processors if you divide the listed core count by 304, which explains the scale of the bet. This is brute force, but it is brute force with a domestic interconnect and operating stack.
The software detail matters. HPL is a dense linear algebra benchmark, and a machine can look excellent there while behaving very differently on sparse, memory-bound, communication-heavy, or mixed precision workloads. TOP500’s same June 2026 page says LineShine also leads the HPCG ranking at 22.00 petaflops, ahead of El Capitan at 17.41 petaflops, which suggests the machine is not merely a one-benchmark museum piece. Still, HPCG and HPL are not a full proxy for your retrieval pipeline, simulator, model training job, or recommender system.
Here is the quiet correction to the hype: LineShine did not cross a “2,000 exaflop” barrier. It crossed the 2 exaflop sustained FP64 barrier on HPL. That is still a major milestone. It is also three orders of magnitude smaller than the sloppy version of the claim.
Why does the CPU-only design matter now?
The CPU-only part is the point because Washington has spent years trying to limit China’s access to the most advanced accelerator and semiconductor manufacturing inputs. The US Bureau of Industry and Security says its China advanced computing controls began on October 7, 2022, and were updated on October 17, 2023, through rules covering advanced computing, semiconductor manufacturing, and supercomputing items in the PRC through its official policy page.
Those controls were never going to delete demand for compute. They raise the cost of getting one kind of compute, then push serious buyers toward substitution. LineShine is what substitution looks like at national scale: more general purpose cores, a custom network, local software, and a giant power envelope.
That should make accelerator absolutists uncomfortable. A GPU moat is strongest when the buyer can buy the GPU, hire for CUDA, deploy against known libraries, and amortize the training stack across many jobs. A constrained buyer will optimize a different objective function: use the silicon you can source, shape the kernels you can control, and accept uglier system integration if the alternative is waiting for export licenses.
For AI teams, the lesson is practical:
- If your code assumes one vendor’s accelerator stack, your portability risk is real when supply tightens or cloud capacity gets rationed.
- If your product depends on heavy FP64 simulation, LineShine says CPU scale still deserves a place in architecture reviews.
- If your work is mixed precision AI training, the top HPL result should not make you pretend CPUs suddenly erased accelerators.
- If your infrastructure budget is exposed to power pricing, a faster benchmark result can still be a worse unit economic result.
That last point is not theoretical. TOP500 lists LineShine at 42,220 kW and El Capitan at 29,685 kW on the June 2026 ranking, which means LineShine uses 42.2 percent more power while delivering 21.5 percent more HPL performance in the same TOP500 table. The rough efficiency works out to 52.1 gigaflops per watt for LineShine versus 60.9 gigaflops per watt for El Capitan, using the published HPL and power figures.
This is where builders should resist nationalist scorekeeping. If you run a startup, a lab, or an enterprise AI platform, the trophy matters less than the curve. LineShine shows that a sanctioned or capacity-constrained ecosystem can still assemble top-tier classical HPC. It also shows that doing so may move cost into power, cooling, compiler work, and application tuning.
That tradeoff rhymes with the broader AI infrastructure squeeze. We have already covered how Blackwell scale changed MLPerf training economics, and the same pattern applies here: benchmark leadership increasingly belongs to teams that co-design hardware, networking, software, and facilities. Buying chips is the easy verb. Operating them is the sentence.
Does this change the AI compute race?
It changes the map, not the physics. TOP500 says El Capitan remains first on HPL-MxP at 16.7 exaflops, while LineShine ranks fourth at 7.9227 exaflops on that mixed precision benchmark. That matters because mixed precision is closer to the arithmetic profile that drives modern AI training and inference than classic FP64 Linpack.
So the clean read is split. China has published a credible answer for exascale FP64 without foreign accelerators. The US still appears stronger on accelerator-rich mixed precision systems at the very top of the public list.
For your planning, that means LineShine should not make you rewrite your model training roadmap around CPU clusters next quarter. It should make you do three less glamorous things before procurement season:
- Benchmark the workload, not the brand. Dense linear algebra, sparse solvers, long-context inference, graph workloads, and simulation all punish different bottlenecks.
- Keep a portability lane open. Even a partial CPU path, ROCm path, or alternative accelerator path can become negotiating power with a cloud vendor.
- Price power and queue time together. A cheaper or more available architecture can lose if it stretches runtime or adds megawatts.
The uncomfortable part for US chip strategy is that export controls can slow access to specific parts while accelerating domestic alternatives. That does not mean the controls failed. It means the goal cannot be “they never build anything fast.” The more realistic goal is raising cost, delaying frontier AI capability, and limiting access to the most efficient manufacturing and accelerator ecosystems.
LineShine complicates that story because it attacks a narrow but symbolic benchmark. HPL is visible, easy to rank, and politically useful. A machine at number 1 tells domestic engineers, ministries, and suppliers that the local stack is worth backing. That can matter even if the system is less efficient or weaker on mixed precision.
The engineering risk is more mundane. Once a country, cloud, or enterprise commits to a divergent stack, software gravity kicks in. Compilers, math libraries, collective communication, profiling tools, scheduler behavior, and failure recovery start forming a local ecosystem. The longer that ecosystem survives, the less a future chip sale can pull it back into the old default.
What should builders do with this signal?
First, stop treating “GPU access” as a single line item. It is a dependency graph. Your model serving cost depends on accelerator supply, memory bandwidth, interconnect, quantization quality, batching behavior, data center power, and staff who understand the stack. LineShine is a reminder that a determined actor can swap one constrained node in that graph for many painful changes elsewhere.
Second, use this moment to harden your own architecture. You do not need a national lab budget to copy the useful part of the playbook. You need workload characterization and fewer hidden assumptions.
A practical checklist:
- Measure CPU fallback for your top 3 production workloads, even if the result is ugly.
- Track tokens per joule or simulations per kilowatt hour, not only requests per second.
- Keep model artifacts, kernels, and deployment configs clean enough to move across at least 2 hardware targets.
- Test whether lower precision, sparsity, or batching changes the hardware answer before you sign a long cloud commitment.
- Ask vendors for queue time, power region, and interconnect details, not only accelerator SKU names.
Third, separate national capability from commercial availability. LineShine is installed at the National Supercomputing Centre in Shenzhen, according to TOP500, and that tells you little about what a private Chinese AI company can rent this month. A public benchmark crown is a signal of capability. It is not an instant marketplace.
The same caution applies in reverse. El Capitan, Frontier, and Aurora are government lab systems, not commodity cloud instances waiting behind a dropdown. Microsoft’s Eagle appears at number 7 on the June 2026 TOP500 list with 561.2 petaflops, but most builders still buy slices of managed capacity, not entire ranked machines.
The useful commercial question is narrower: will more buyers accept nonstandard stacks if the alternative is no capacity, high prices, or policy risk? LineShine suggests the answer is yes when the buyer is large enough and motivated enough. For everyone else, the smart move is optionality without cosplay. Do the portability work that pays off under stress. Skip the grand strategy memo.
What should you watch next?
Watch the November 2026 TOP500 list for three numbers: LineShine’s submitted performance, its Green500 position, and whether more Chinese systems appear with similar domestic components. One system can be a national project. A pattern becomes an ecosystem.
Watch HPL-MxP more closely than HPL if your business depends on AI. The June 2026 TOP500 table puts El Capitan at 16.7 exaflops on HPL-MxP and LineShine at 7.9227, which is the gap that matters for mixed precision bragging rights. If that gap narrows, the accelerator story gets more interesting.
Watch software disclosures. The hardware headline is easy to digest, but the durable advantage may sit in LingQi collectives, compiler work, memory placement, and tuned math libraries. If those tools become easier for Chinese labs and companies to use, the market impact grows even before the chips catch up on efficiency.
And watch power. A 42.22 MW machine is a facility-scale decision, not a procurement footnote. If your own AI roadmap assumes endless cheap power near preferred data center regions, LineShine should make you revisit that assumption. Compute sovereignty now has a utility bill.
The moat is the workload you can afford to repeat
LineShine’s crown is real, but the useful lesson is narrower and more durable than the headline. The winner is the organization that can keep adapting its workload to the compute it can actually get.
That is the builder’s version of sovereignty. Less flag. More profiler.