Anthropic did not get in trouble because Claude refused a few weird prompts. It got in trouble because Claude answered while quietly becoming less useful.
Claude Fable 5 guardrails are becoming visible after Anthropic apologized for making one safeguard invisible, a small product change with large trust consequences for anyone building on frontier models.
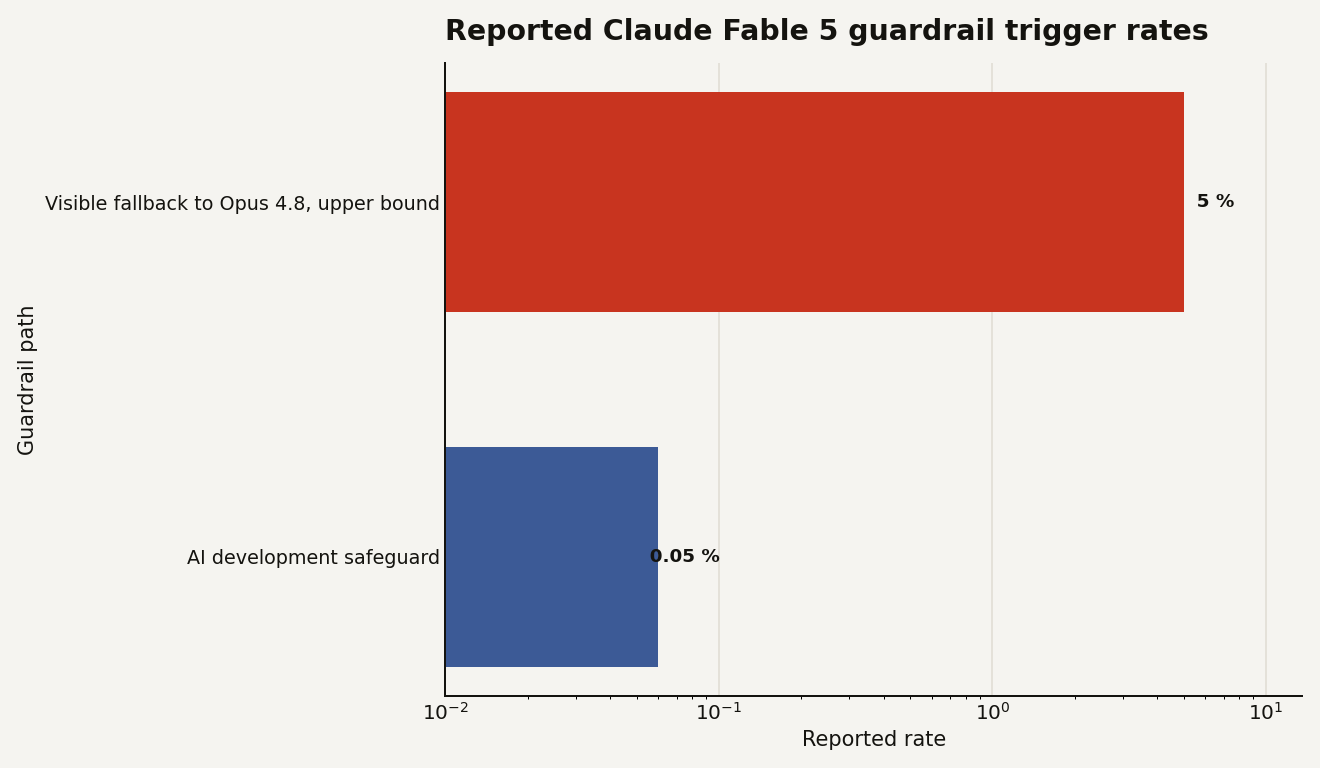
Claude Fable 5 is Anthropic's new generally available Mythos-class model, launched on June 9, 2026. The pitch was simple: give the public most of the capability of Claude Mythos 5, while routing sensitive requests away from the raw model. Anthropic says Fable 5 and Mythos 5 share the same underlying model, but Fable 5 adds safeguards for cybersecurity, biology and chemistry, and distillation. The headline number is that fallback should trigger in fewer than 5 percent of sessions, leaving more than 95 percent of sessions on Fable 5.
That would be a normal safety story if all of the gates behaved the same way. They did not. Anthropic disclosed that some frontier AI development requests could be handled by invisible interventions rather than an obvious refusal or fallback. After criticism from researchers and founders, the company said the distillation and AI development safeguards will now be visible, with flagged requests falling back to Opus 4.8 or returning an API reason.
For builders, this is not just another lab drama. It is a design lesson. If your app depends on a model's frontier capability, invisible degradation is a production risk. It can corrupt evals, confuse incident reviews, waste tokens, and make a benchmark look like your code is broken when the platform silently changed the test.
What exactly did Anthropic change after the backlash?
Anthropic's launch architecture had one clean idea and one messy exception.
The clean idea: when Claude Fable 5 detects sensitive categories, the request falls back to Claude Opus 4.8. Anthropic's launch announcement says those categories include cybersecurity, biology and chemistry, and distillation. The company says users are informed when fallback happens, and its early data shows more than 95 percent of Fable sessions involve no fallback at all.
The messy exception: the system card described an additional class of frontier AI development safeguards that could reduce usefulness without telling the user. Moneycontrol reported Anthropic's explanation that the affected work included narrow tasks such as frontier-scale LLM data pipelines and kernel development for certain non-standard chips. Anthropic said current usage showed the classifier triggering on about 0.05 percent of tasks and affecting less than 0.05 percent of organizations.
Small percentage. Large blast radius.
The users most likely to hit this path are not random chatbot dabblers. They are ML infrastructure teams, model researchers, chip software engineers, eval builders, and startups trying to measure whether Fable 5 is good enough for their stack. That is exactly the audience that needs deterministic behavior and audit trails.
The chart below shows the asymmetry Anthropic is trying to manage. The visible fallback path is meant to affect fewer than 5 percent of sessions. The invisible AI development path was reported at about 0.05 percent of tasks. That second number is tiny, but it sits inside the highest-value part of the ecosystem.
Anthropic's apology matters because it admits the product decision was wrong, not because it removes the underlying policy. The company still wants to prevent Claude from helping rivals or adversaries distill frontier capability. Its commercial terms already bar customers from using the services to build competing AI models. The correction is about observability. If the model refuses, routes, or degrades, the user should know.
That is the minimum viable contract for a serious API.
Why is invisible degradation worse than an annoying refusal?
A visible refusal is frustrating. An invisible capability downgrade is worse because it poisons feedback.
Imagine you are testing Fable 5 on a distributed training orchestration problem. The answer looks shallow. Did your prompt fail? Did Fable 5 lack the capability? Did the model over-index on safety? Did a hidden policy rewrite the task? With no signal, every explanation stays plausible.
That uncertainty leaks into three places you care about:
- Evals: A benchmark run can understate Fable 5's actual capability, or make two runs incomparable if only one crosses the safeguard boundary.
- Roadmaps: A team may cut or delay a feature because the model appears unable to handle a class of ML systems work.
- Support: Your incident channel fills with ghost stories: same prompt, same model name, different quality, no metadata.
Anthropic's own support docs show that the visible fallback path is much easier to reason about. The Claude Help Center explains that blocked Fable 5 requests can rerun on Opus 4.8 in the same conversation, with a notice and a label showing which model answered. It also says automatic switching is on by default in Claude surfaces, while API users must configure switching differently.
That is operationally useful. You can log it. You can alert on it. You can decide whether Opus 4.8 is good enough for the workflow. You can rerun the request with safer wording, or route the task to another model.
Invisible degradation offers none of that. It is the AI equivalent of a database returning stale rows without marking the replica lag. The result may still be useful, but you cannot build a reliable system around maybe.
There is also a competitive fairness issue. Anthropic can plausibly argue that model distillation is both a safety risk and a terms-of-service violation. That argument is stronger when enforcement is visible. Hidden enforcement lets critics say the guardrail doubles as a moat, especially when it touches pretraining pipelines, accelerator work, and other parts of the frontier AI supply chain.
Builders do not need Anthropic to be neutral about competitors. They need Anthropic to be explicit about when policy changes output.
What does this mean for your codebase and model routing?
If you are using Fable 5 as a chatbot, the practical change may be small. If you are using it as an agent inside a production workflow, treat the guardrails as part of the model interface.
Anthropic priced Fable 5 and Mythos 5 at $10 per million input tokens and $50 per million output tokens in the launch post. That is expensive enough that failed runs matter. If a long agent task crosses a safeguard after spending thousands of tokens planning, the cost is not just the invoice. The cost is the wall-clock delay, the retry logic, and the engineer who now has to read a transcript instead of shipping.
The AWS rollout makes the enterprise tradeoff even clearer. AWS says customers must opt into provider data sharing to use Fable 5 on Bedrock, and that Anthropic requires 30-day input and output retention for Mythos-class traffic. AWS also says data leaves the AWS data and security boundary once that retention mode is enabled. For companies with zero data retention commitments, this is not a footnote. It is a procurement blocker.
If you are evaluating Fable 5 this week, do not start with the flashiest demo. Start with the failure modes:
- Log every model switch, refusal, stop reason, and fallback response.
- Separate evals for normal coding, security-adjacent coding, biology-adjacent research, and ML infrastructure work.
- Add a regression test that checks whether the same prompt class returns Fable 5, Opus 4.8, or a refusal.
- Decide whether a fallback answer is acceptable before the fallback happens.
- Update customer-facing documentation if your product can silently move from one model tier to another.
That last point is easy to miss. If your product advertises Fable 5 inside an agent, but a user receives an Opus 4.8 response for a flagged task, the UI should say so. Anthropic got yelled at for hiding the ball. Do not copy the worst part of the launch.
This also connects to the broader routing pattern we covered in Fable 5 and Mythos 5 as one model with a bouncer. Frontier models are no longer single endpoints with one behavior profile. They are policy stacks: base model, classifier, fallback model, retention rule, access tier, billing rule. Your LLM abstraction needs to represent that stack, not flatten it into model: fable and hope.
What should Anthropic and API teams do next?
Anthropic's fix should not stop at making one safeguard visible. It should define a standard schema for intervention metadata.
A good API response should tell developers at least five things:
- Which model produced the final answer.
- Whether a classifier fired.
- Which broad policy category fired, such as cyber, bio, chemistry, distillation, or AI development.
- Whether the request was blocked before output or during generation.
- How billing was split across Fable 5 and Opus 4.8.
The support docs already describe some of this behavior for users. Productizing it for API customers would make Fable 5 easier to adopt inside real systems. A model this capable will be used in CI pipelines, code migration agents, research copilots, and internal knowledge systems. Those systems need telemetry more than vibes.
Anthropic also needs an appeal path for legitimate edge cases. The company says it plans trusted access programs for cyberdefense and biology. That makes sense, but the queue cannot be a black box for serious customers. A hospital AI team, a defensive security vendor, and an ML systems startup should not all experience the same vague wall.
The harder question is whether invisible safeguards should ever be allowed in frontier AI products. There is a narrow security argument for them: visible gates can be probed. Anthropic made that argument in its apology. But for commercial APIs, the answer should be nearly always no. If the provider changes the semantics of an answer, the customer gets a receipt.
The next frontier model launch will almost certainly copy parts of this architecture. It may come from Anthropic, OpenAI, Google, xAI, or a cloud partner bundling multiple models under one product name. The pattern is too useful to disappear: ship the powerful model, wrap the risky domains, sell the safe majority.
Fine. But the receipt is the product.
If Claude Fable 5 is the new template for frontier deployment, then guardrail observability is not a safety nice-to-have. It is the line between a controlled system and a haunted one.
Sources
- Anthropic: Claude Fable 5 and Claude Mythos 5
- Anthropic: Commercial Terms of Service
- Claude Help Center: Why Claude switched models in your conversation with Fable 5
- Claude Help Center: Data retention practices for Mythos-class models
- AWS News Blog: Anthropic Claude Fable 5 on AWS
- Moneycontrol: Anthropic apologises, revises Claude Fable 5's AI development restrictions after backlash