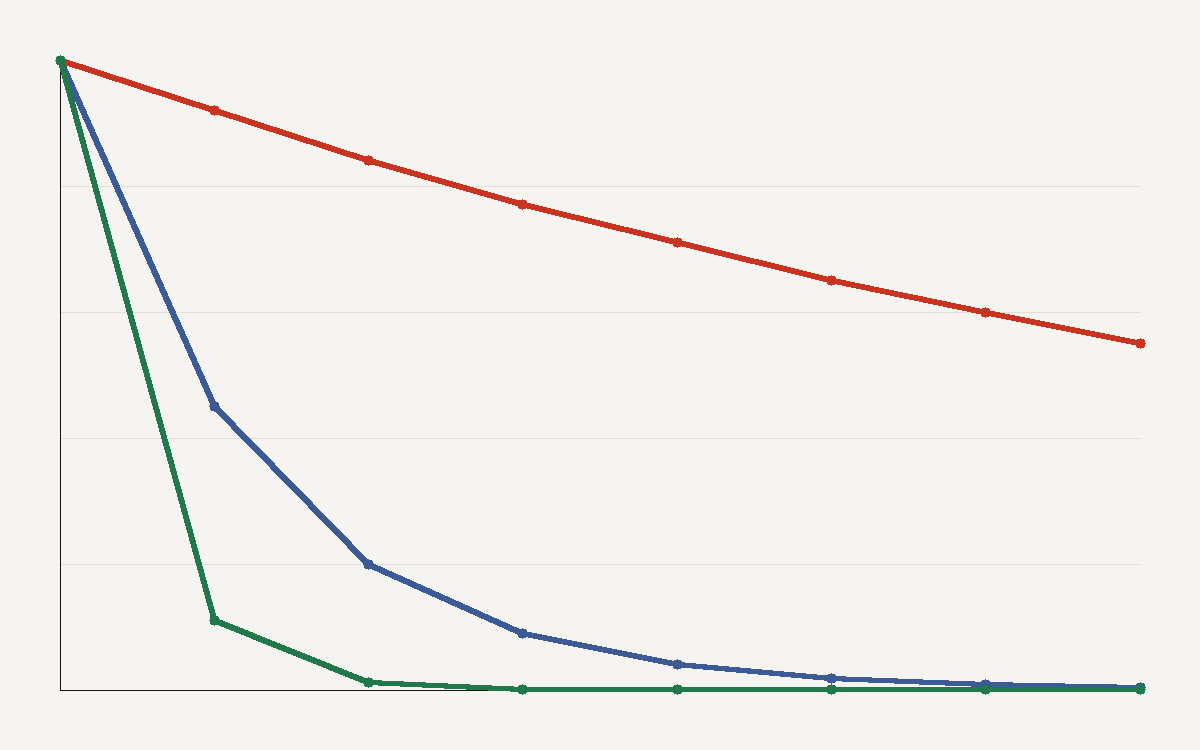
The headline number is real and it is huge: the price to run a language model at a fixed level of performance has fallen about 40 times per year. The number that matters for your budget is the spread behind it. Epoch AI puts the decline between 9 and 900 times per year depending on which capability milestone you measure. The cheap collapse and the expensive plateau are the same trend seen from two ends.
Easy work fell off a cliff. Reaching GPT-3.5 quality on general knowledge went from a premium product to a rounding error, dropping by hundreds of times a year as small open models caught the old frontier. Hard work moved slowly. Holding PhD-level science accuracy steady has only become cheaper at roughly 9 times a year, because staying at that bar still needs a large, current model.
Read the gap, not the average
import numpy as np
# Annual price-decline factors at three capability milestones (Epoch AI)
milestones = {"easy_general": 900, "mid_range": 40, "frontier_reasoning": 9}
# Cost after t years, relative to today, for a fixed quality bar
for name, factor in milestones.items():
cost_in_2_years = 1 / factor**2
print(f"{name:18s}: {cost_in_2_years:.6f} of today's price")The output tells the planning story. Anything sitting on the 900x line is nearly free to serve next year, so do not architect around its cost. Anything on the 9x line stays expensive, so that is where caching, routing, and smaller fallback models earn their keep.
What it changes for buyers
| Task class | Annual price drop | Planning move |
|---|---|---|
| Classification, extraction, summaries | up to 900x | Assume near-zero cost soon |
| General chat, drafting, retrieval | about 40x | Route to mid-size models |
| Multi-step reasoning, hard science | about 9x | Budget for it, cache aggressively |
The lesson connects to the broader collapse in token prices: falling averages hide where money still goes. Spend your optimisation effort on the flat line, not the steep one. The milestone-by-milestone data is published by Epoch AI.
Task routing is the new cost discipline
When price declines vary by task, the cheapest architecture is rarely one model for everything. A good system routes easy work to small models, sends ambiguous or high-value work to stronger models, and escalates only when the expected gain justifies the cost. The routing layer becomes as important as the model choice.
This is a practical change for product teams. Classification, extraction, formatting, and first-pass summarization can often run on cheaper models with strict validation. Multi-step reasoning, high-stakes advice, and scientific or legal analysis may need a frontier model plus human review. Treating both groups as the same AI workload wastes money and hides risk.
The routing policy should be measurable. Track cost per accepted answer, error rate by task class, fallback frequency, and human-review minutes. If a smaller model produces answers that reviewers reject, its apparent savings are false. If it clears routine work reliably, it protects the budget for harder calls.
Falling costs can increase total spend
Cheaper inference does not guarantee a smaller bill. Lower prices often increase usage. Teams add AI to more screens, run more background analysis, and ask for more drafts because each one feels inexpensive. The unit cost falls while total volume rises. That is how a budget can grow during a price collapse.
The effect is strongest for work that was previously skipped. A company that used to summarize only high-value documents may start summarizing everything. A support team may generate suggested replies for every message rather than only complex cases. A data team may run nightly interpretations across dashboards that no analyst had time to inspect before.
That expansion can be valuable, but it needs a budget owner. The right question is not whether each call is cheap. It is whether the new volume changes a decision, reduces labor, improves quality, or creates a product feature users will pay for. Without that discipline, the cost decline becomes a demand engine with no governor.
What to put in the dashboard
An inference dashboard should separate price from mix. Show total tokens, cost per task class, model used, cache hit rate, retry rate, latency, and accepted outputs. Then split the view by easy, medium, and frontier workloads. The blend is what matters because the average can improve while the expensive class grows quietly.
Caching deserves its own line. Many high-cost calls repeat stable context, system instructions, or reference material. Prompt caching, retrieval caching, and answer reuse can lower cost without changing model quality. For hard tasks on the 9x line, those operational savings may matter more than waiting for the next price cut.
The durable lesson is that inference is no longer one market. Commodity language work is racing toward near-zero marginal cost. Frontier reasoning remains a premium input. The companies that understand the split will make AI feel cheap to users without letting the hardest tasks quietly consume the margin.
The procurement question
Buyers should ask vendors to price the actual workload mix, not an average token bundle. A support assistant heavy on classification and retrieval should be priced differently from a scientific reasoning tool. A drafting product with high cache reuse should not carry the same cost model as a long-context analyst. The benchmark is cost per accepted answer.
That metric forces hidden costs into the open. It includes retries, review, latency, caching, and model escalation. It also rewards systems that use cheaper models well. The next phase of inference competition will be less about a single headline token price and more about routing the right task to the right level of capability.