Dataset: The AO3 Claude detector skin is available as a public AO3 site skin via the @heatedrivalryai account on X; the underlying HTML artifact is documented in Anthropic's Claude web interface.
On June 29, 2026, an anonymous X account called @heatedrivalryai posted what looked like a precision weapon in the culture war between fanfiction writers and generative AI. It was a custom skin for Archive of Our Own, the nonprofit fanfic repository run by the Organization for Transformative Works, that claimed to detect a specific HTML artifact left behind when text is copied directly from Anthropic's Claude chatbot into AO3's editor. The account said that Claude wraps its responses in a code snippet called font-claude-response-body, and that the skin turns the entire page background red when it finds that wrapper on a fanfic page. Within days, fandom communities were using the tool to publicly name and shame writers whose works tested positive.
The AO3 Claude detector exposed a real, if narrow, signal. But the backlash it triggered reveals a deeper problem for any builder who cares about provenance, trust, or content moderation in user-generated platforms. The tool catches one specific copy-paste path from one specific model, and already the community is treating its output as a verdict. The detector's false negative rate is, by design, enormous. Anyone who pastes Claude's output into Google Docs or Microsoft Word first strips the wrapper entirely, and the skin sees nothing.
What does the Claude detector actually catch?
The @heatedrivalryai account released the skin on June 29, 2026, and The Verge's Jess Weatherbed tested it against both sample posts and a self-generated Claude story. The red screen appeared when text was pasted directly from Claude into AO3's editor, and vanished when the same text was routed through an intermediary like Google Docs. Anthropic did not respond to The Verge's request to verify the mechanism, but the methodology is straightforward: Claude's web interface wraps its responses in a span with the class font-claude-response-body, and that span survives a direct copy-paste into AO3's rich text editor.
The signal is real but brutally narrow. It catches exactly one workflow: a writer who copies Claude's output and pastes it straight into AO3 without any intermediate editing tool. Here is what slips through:
- Any text pasted through Google Docs, Microsoft Word, or any other intermediary editor, which strips the HTML wrapper.
- Text from ChatGPT, Gemini, DeepSeek, or any model other than Claude.
- Text that was Claude-generated but retyped, even partially, by a human.
- Any work where Claude was used for brainstorming or outlining but the final text was written separately.
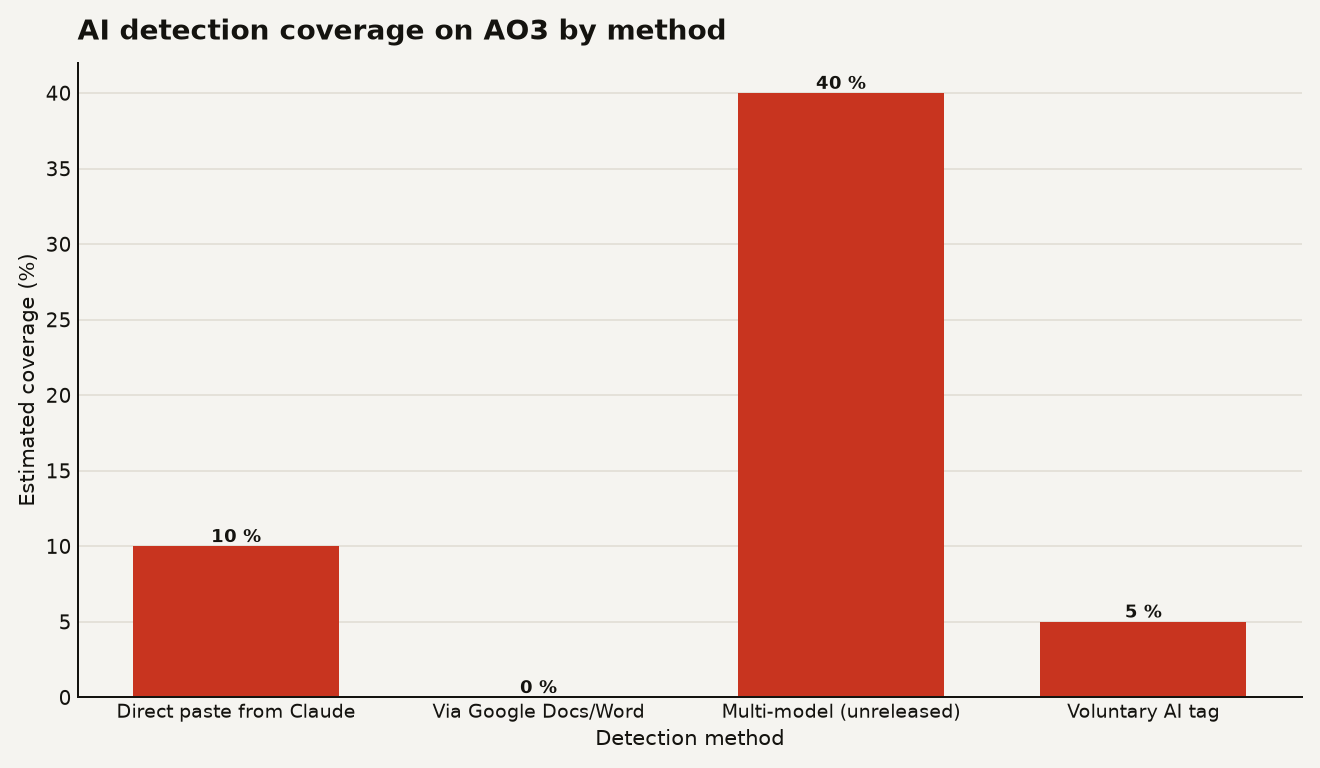
The chart above shows the estimated coverage of each detection method available on AO3 today. The direct-paste Claude detector catches perhaps 10 percent of actual AI-assisted fanfics on the platform, a rough estimate based on how many writers would plausibly paste straight from a chatbot into AO3's editor without an intermediate tool. The unreleased multi-model detector, which its creator claims can identify Claude, DeepSeek, and some ChatGPT outputs, might push coverage higher if the methodology holds, but it has not been released or independently verified.
The tool also cannot distinguish degree. A red screen means Claude was involved somewhere in the copy-paste chain, but it says nothing about how much of the story was AI-generated. The entire work could be Claude output, or the author could have pasted a single paragraph into Claude for spell-checking and then moved it back. The skin does not know, and the community's response has not cared.
Why are fandom communities treating this like definitive proof?
The fanfiction world has been at war with AI since well before this detector existed. In early April 2026, a user named nyuuzyou scraped 12.6 million fanfics from AO3 and uploaded the dataset to Hugging Face, the open-source AI model hosting platform. The Reddit community r/AO3 discovered the scrape, and the Tumblr account ao3scrapesearch built a search engine that let authors check whether their work had been included. Fans coordinated DMCA takedown notices, and the Organization for Transformative Works filed its own takedown on April 9. Hugging Face disabled the dataset, but nyuuzyou reuploaded it to sites hosted in Russia and China, which are far less responsive to DMCA complaints.
The OTW addressed the scraping in an April 26 board meeting, saying it had added a Cloudflare tool to block AI bots, but acknowledged it was imperfect. More aggressive bot-blocking, the board noted, would harm users on older devices. This is the same tension that any platform faces when it tries to wall off scrapers: the defenses that stop bots also degrade access for legitimate users.
The broader pattern is that fanfiction writers see AI as an existential threat to a community built on free, human creative labor. AO3's own Terms of Service prohibit commercial use, and the community's norms treat AI-generated work as both a violation of the unspoken code (never charge money, never steal) and a corruption of the collaborative, connective space that makes fandom valuable. When the Claude detector arrived, it gave a frustrated community what looked like hard evidence, and the response was immediate public naming and shaming of flagged authors.
At least one writer was caught in the crossfire because a trusted editor used Claude on their behalf without disclosure. The author was flagged, and the community treated the red screen as a verdict regardless of the explanation.
What are the false positive and false negative risks for builders?
For anyone building detection tools, content moderation systems, or provenance infrastructure, the AO3 Claude detector is a case study in the gap between a real signal and a reliable verdict. The false negative problem is obvious: the tool only catches direct paste from Claude, so anyone who edits in Google Docs first is invisible. The Verge's Weatherbed noted that writing directly into a CMS is risky behavior in general, which means the writers most likely to be caught are the ones least likely to be producing polished, deliberate work.
The false positive problem is more subtle but equally dangerous. The font-claude-response-body wrapper could theoretically appear in a page for reasons unrelated to the author using Claude. A collaborator could paste in a section. An editor could run text through Claude for proofreading. A browser extension or clipboard manager could preserve the HTML in unexpected ways. The tool's creator acknowledged this risk, saying the examples were meant to demonstrate the system, not to accuse specific users, but the community ignored that nuance.
Here is what this means for builders working on similar detection or moderation problems:
- A real signal is not a reliable verdict. The Claude wrapper is a genuine HTML artifact, but it only proves Claude was in the copy-paste chain, not that the work is AI-generated. Any detection system that treats a single signal as conclusive will produce wrongful accusations, and the social cost of those accusations is high.
- Coverage gaps create false confidence. A tool that catches 10 percent of cases can make a community believe the problem is under control, when in reality 90 percent of AI-assisted work is invisible. This is worse than no tool at all, because it redirects vigilance toward the easiest cases and away from the harder ones.
- Community norms move faster than tooling. The AO3 skin was released on June 29 and public shaming began within days. The social infrastructure for enforcement outpaced any careful validation of the tool's accuracy, and there is no mechanism to appeal a red screen.
- Provenance is a platform problem, not a user problem. AO3 already has a "Created Using Generative AI" tag that authors can use voluntarily, but the backlash against AI means almost no one will use it honestly. If the platform wanted reliable provenance, it would need to build detection or watermarking into the submission pipeline, not rely on community policing.
The broader detection landscape offers little hope. Systems like C2PA Content Credentials and Google's SynthID are making progress on images, video, and audio through invisible watermarks and metadata, but those techniques do not carry over to copy-pasted text. Google and OpenAI did not respond to The Verge's questions about whether their models leave traceable artifacts in generated text, and there is no known reliable technological solution for distinguishing generated text from human-typed text.
What should you do if you are building detection or moderation tooling?
If you are building anything in the detection, provenance, or content moderation space, the AO3 Claude detector episode offers a few concrete lessons.
First, do not ship a single-signal detector without clear, unavoidable documentation of its limits. The @heatedrivalryai account did include caveats, but the community ignored them, and the tool was used for public accusations within days. If you ship detection tooling, the limits need to be built into the UI, not buried in a post. A red screen that does not distinguish between a fully AI-generated story and a spell-checked paragraph is a design failure, not a user failure.
Second, think about the adversarial response. The tool's creator noted that some flagged writers had already updated their works to remove the artifacts, and future works can easily evade the skin by routing through any intermediate editor. Any detection tool that relies on a fragile, client-side artifact will be defeated the moment its target audience learns how it works. If you are building detection, you need to assume the artifact will be known and stripped.
Third, consider whether detection is even the right intervention. AO3's existing tagging system is a better provenance mechanism than any after-the-fact detector, but it requires honesty and there is no incentive for honesty in a hostile environment. The platforms that solve this problem will be the ones that build provenance into the creation pipeline, not the ones that build policing tools on top of it. Anthropic, OpenAI, and Google all have internal incentives to solve this, because as synthetic text crowds out human writing in training data, they risk the model collapse scenario that degrades their own outputs.
For the fanfiction community specifically, the practical advice is narrower. The Claude detector skin is a tool with a known, narrow signal. Use it to satisfy your own curiosity, not to render verdicts. If a work tests positive, the most likely explanation is that Claude was involved somewhere in the process, but the work could be 95 percent human-written with a Claude-assisted paragraph. The community's existing norms around tagging and disclosure are a better long-term mechanism than any detection tool, and the witch hunt dynamic risks driving away writers whose only crime was using a spell-checker.
The real test is whether communities can resist the urge to adjudicate
The AO3 Claude detector is a genuine piece of technical work that found a real signal in a real product. That is more than most AI detection tools can claim. But the gap between a real signal and a reliable verdict is where the damage happens, and the fanfiction community has already shown what that damage looks like. A writer was flagged because their editor used Claude. Others have been named and shamed based on a red screen that cannot tell you whether a story was generated by a machine or proofread by one. The tool will be defeated by anyone who pastes through Google Docs, which is most writers, and the next tool will face the same adversarial erosion. The communities that handle this well will be the ones that treat detection as a prompt for conversation, not a substitute for it.
Sources
- The Verge - The fanfiction community is at war with AI and itself
- The Verge - Fanfiction writers battle AI, one scrape at a time
- Archive of Our Own - Organization for Transformative Works
- Hugging Face - Open-source AI model hosting platform
- Anthropic - Claude AI model developer