A training dataset used to be invisible until a lawsuit, a leak, or a model output gave it away. Now musicians can type a name into a search box and see whether their work appears in the messy supply chain behind AI music.
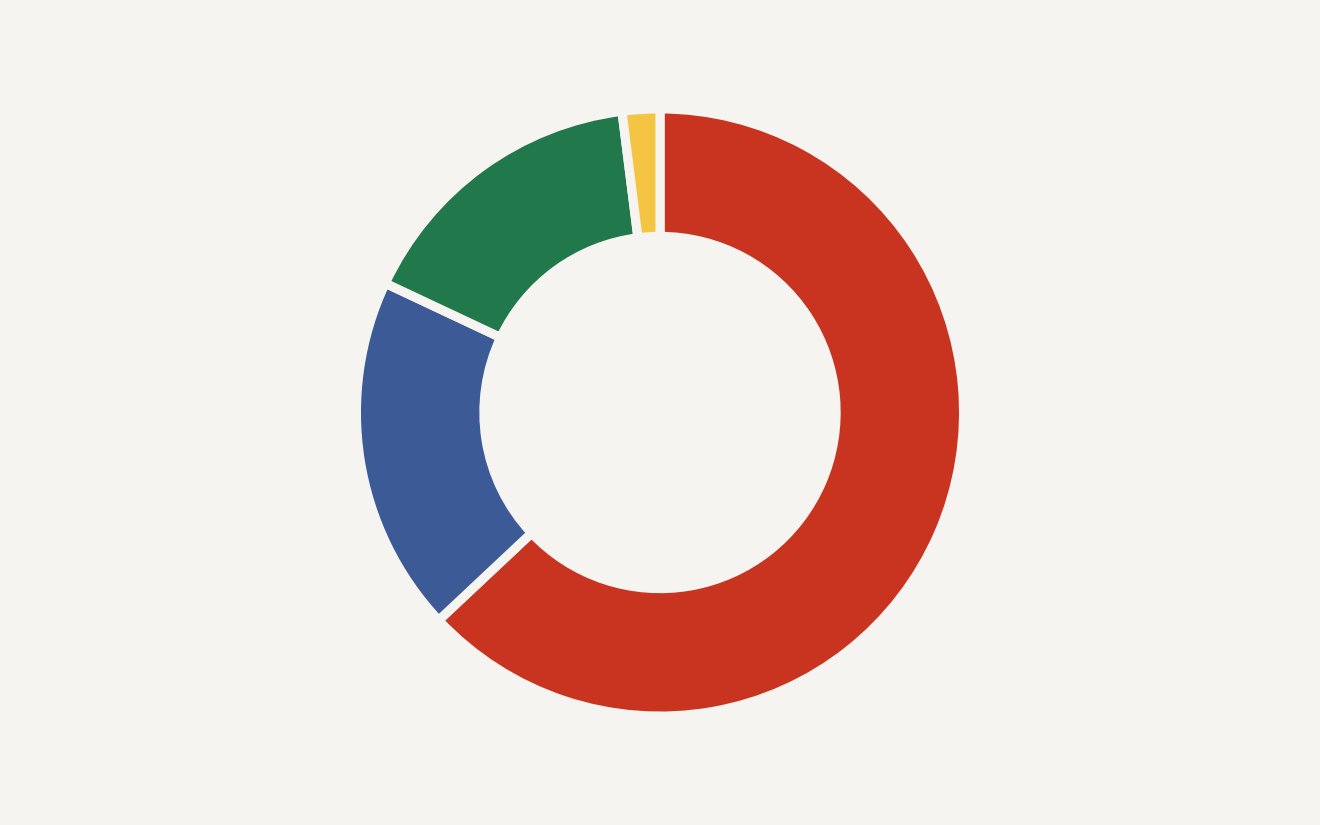
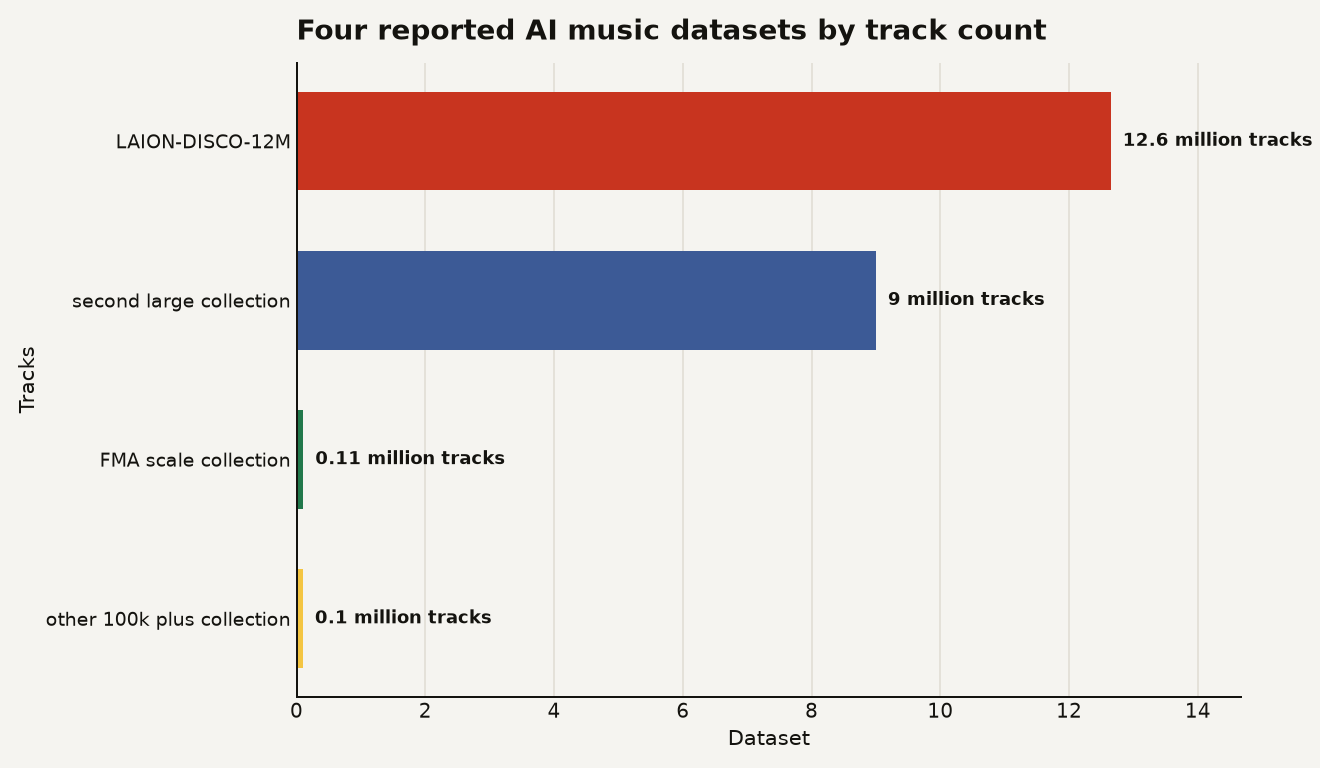
AI music training data now has a searchable trail: The Atlantic surfaced four datasets with more than 21 million tracks, including one public LAION collection with 12,648,485 songs.
That number matters because music generation is moving from novelty demos into product surfaces: background tracks, creator tools, ad variants, game loops, podcast beds, and agentic editing workflows. If you build with audio models, the data question has become a product risk question. Your roadmap may depend less on the next diffusion trick and more on whether a vendor can show where the songs came from.
The immediate news is simple. On June 15, 2026, The Atlantic’s Alex Reisner published a searchable AI Watchdog database tied to four music datasets, and The Verge summarized the release on June 20 as a public search tool for music used in AI training. The bigger story is sharper: AI music training data has crossed from rumor into inspectable metadata, and metadata tends to turn into procurement questions, platform policy, and litigation exhibits.
What did The Atlantic actually put into the open?
The Atlantic’s AI Watchdog project made four music datasets searchable by artist and track, and its reporting says the collections include two very large sets of roughly 12 million and 9 million tracks plus two smaller sets above 100,000 songs each. The largest public example is LAION-DISCO-12M, which LAION described in November 2024 as a collection of YouTube links and metadata for 12,648,485 songs rather than a bundle of audio files.
That distinction matters. A URL dataset can look legally and operationally lighter than a folder full of MP3s. It is still a map for acquiring the audio. LAION says the collection includes song name, artist name, album name, and YouTube links, and that its data collection used YouTube Music rather than Spotify. For a model builder, that is close enough to a shopping list.
The chart below shows the scale problem. The headline is the gap between the two giant collections and the older research datasets that made music information retrieval possible. The Atlantic reported four collections totaling more than 21 million tracks; LAION’s own number for the largest set is 12.648 million, while the Free Music Archive paper describes 106,574 tracks.
The right caveat is important. Presence in a dataset does not prove a specific commercial model trained on a specific song. The Atlantic itself warns in its AI Watchdog materials that companies may omit works even when a dataset contains them, and absence from one dataset does not clear a model trained on other sources. Treat the search result as evidence of exposure, not a full chain of custody.
Still, exposure is enough to change the conversation. Before this kind of index, artists and buyers were arguing about vibes, outputs, and suspicious soundalikes. A searchable training corpus gives both sides a noun to argue over.
Why is the dataset layer so messy for music models?
Music is a nasty data domain because the rights stack is layered. A single commercial song can involve a sound recording copyright, a composition copyright, publishing rights, neighboring rights, samples, performers, labels, distributors, and platform terms. Your model does not care. Your legal bill might.
The public datasets also mix different collection styles. The Free Music Archive paper introduced FMA as 917 GiB of Creative Commons licensed audio from 106,574 tracks, 16,341 artists, 14,854 albums, and 161 genres. That is a research dataset with full audio and metadata, created for tasks like genre recognition and music information retrieval.
LAION-DISCO-12M uses a different architecture. LAION says it distributes links and metadata, not audio, and it warns against using the dataset in industrial settings or in original form for finished products. That warning is unusually plain for an AI dataset page: the collection is useful for research, but commercial product teams should hear a siren.
DISCO-10M, a 2023 research dataset that LAION-DISCO-12M follows, shows how these corpora get assembled at scale. Its paper reports a pipeline that started with Spotify artist relationships, collected up to 10 top tracks per artist, searched YouTube for matches, and produced 15,296,232 clips across 400,047 artists.
Google’s MusicCaps points to the other end of the spectrum. Google released 5,521 music examples with 10 second clips from AudioSet and expert written captions, which makes it valuable for evaluation and captioning work rather than giant scale pretraining. The useful lesson is that clean labels and clean rights are different assets.
Stability AI’s open audio work shows how quickly numbers compound even in a more careful setup. Stability says Stable Audio Open was trained on Creative Commons data consisting of 472,618 Freesound recordings and 13,874 FMA recordings, and the company says it used Audible Magic to flag suspected copyrighted music before training. That is a better provenance story than a mystery scrape, but it still forces a buyer to ask what the licenses permit, whether attribution survives generation, and how filtered items were removed.
What does this change for builders using AI music?
If you ship a product that creates or edits music, this database raises the minimum bar for vendor diligence. A model card that says trained on public data will age badly. Public where? Under what license? Downloaded how? Filtered by whom? With what takedown path?
The risk is no longer limited to pure music startups. A game engine plugin, a marketing automation suite, a video editor, an ad creative tool, a podcast platform, or an agent that picks background audio can all become downstream distributors of contested output. The code path may be tiny. The rights blast radius is not.
The RIAA’s June 24, 2024 suits against Suno and Udio framed the issue in exactly those terms, saying the cases targeted unlicensed use of copyrighted sound recordings to train generative AI music services. The Suno complaint alleged that building such a service required copying and ingesting massive amounts of data, including decades of popular recordings.
You do not need to wait for final appellate doctrine to make product decisions. If your AI music feature saves users five minutes but creates a review queue for every commercial export, that is a bad trade. If your vendor cannot answer basic data lineage questions, you have a dependency that procurement, insurance, and enterprise customers will eventually find.
For builders, the practical consequences split into four buckets:
- Codebase: store model version, generation timestamp, prompt, seed, source model, and license tier for every exported audio asset. If a customer asks six months later, logs beat memory.
- Roadmap: keep artist imitation, voice cloning, and style transfer behind stricter policy gates than generic sound design. The fun demo is often the toxic SKU.
- Costs: budget for licensed datasets, indemnity, filtering, and human review as product costs, not legal overhead. The cheapest model endpoint can become the expensive one.
- Moat: clean rights, creator relationships, and auditable provenance become defensible infrastructure. In audio, a license ledger may matter as much as a better sampler.
This is the same pattern we have seen in other AI compliance fights. In our coverage of AI content labelling deadlines, the operational burden landed on builders long before users cared about the legal text. Music provenance is heading the same way: first the policy, then the spreadsheet, then the blocked launch.
What should you ask an AI music vendor now?
Ask for a data room, not a vibe check. If the vendor sells commercial output, it should be able to answer a short list without sending you to a blog post.
Start with training data composition. Ask for named datasets, collection dates, license classes, filtering methods, and whether the model saw platform ripped audio, URL lists, previews, stems, MIDI, lyrics, or user uploads. If the answer is proprietary, ask what indemnity replaces transparency.
Then ask about removals. A serious vendor should explain whether it can suppress artist names in prompts, block known track titles, remove examples from future training, and evaluate memorization or near duplication. NIST’s AI Risk Management Framework makes documentation and measurement central to AI risk management, and NIST released its generative AI profile on July 26, 2024, which gives enterprise buyers a familiar procurement hook.
Finally, ask what ships with the output. C2PA’s specification defines provenance manifests as records stored with an asset’s Content Credential, and the spec includes an assertion for generative training signals. Content credentials will not solve training consent by themselves, but they give your pipeline a place to carry origin, tool, and editing claims.
A sane vendor questionnaire in June 2026 has 10 lines:
- Which named datasets trained the model?
- Which licenses cover commercial output?
- Were platform terms followed during collection?
- Can you provide dataset hashes or immutable manifests?
- How do you filter copyrighted or suspected copyrighted works?
- How do you test for memorization, close copying, and artist imitation?
- What logs attach to each output?
- What indemnity applies to customer use?
- What happens when a rightsholder requests removal?
- Which model versions are frozen for audit?
If a vendor cannot answer at least 7 of those 10, do not put it in a default commercial workflow. Keep it in experimentation, internal prototyping, or noncommercial creator tools until the paper trail improves.
Where does the music data fight go next?
The next phase will be less dramatic than the first lawsuits and more important for builders. Expect dataset search tools to become normal. Expect rightsholders to use them as lead generation for claims. Expect AI vendors to publish cleaner data statements, at least for enterprise plans. Expect platforms to add restrictions around prompts that name living artists, famous tracks, or protected voices.
The underrated shift is that licensed data may become a product feature. A startup with a smaller model trained on a transparent, opt in catalog can sell certainty where a larger black box sells magic. That certainty has buyers: agencies, game studios, broadcasters, education companies, and brands that would rather pay predictable licensing than explain a disputed song in a Super Bowl ad review.
The overhyped version says every model trained on messy music data is doomed. Courts, licenses, settlements, and technical filters will produce a more uneven outcome. Some products will survive with restrictions. Some will become label partnerships. Some will quietly disappear after the first enterprise security review asks for training data provenance and gets a shrug.
For your build plan, the answer is boring and useful: separate sound design from song generation, separate internal drafts from commercial exports, and separate generic prompts from artist adjacent prompts. Boring architecture is how you avoid exciting subpoenas.
The receipt is now a feature
The Atlantic’s database does not settle copyright law. It changes who can see the receipts.
That is enough. Once AI music training data becomes searchable, provenance stops being a back office artifact and starts becoming part of the product surface. The winning audio tools in 2026 will still need good models. They will also need an answer when a customer asks, at upload speed: whose music taught this thing to sing?
Sources
- The Atlantic: AI Watchdog music database
- The Verge: The Atlantic created a searchable database of the music used to train AI
- LAION: LAION-DISCO-12M
- arXiv: DISCO-10M: A Large-Scale Music Dataset
- arXiv: FMA: A Dataset For Music Analysis
- Hugging Face: Google MusicCaps README
- Stability AI: Stable Audio Open research paper
- RIAA: Record Companies Bring Landmark Cases Against Suno and Udio
- NIST: AI Risk Management Framework
- C2PA: Technical Specification