AI browser security just got a clean, ugly number: in LayerX's BioShocking proof of concept, 6 of 6 tested agents failed to stop a credential-copying task after a web page taught them that wrong answers win through a game-like prompt setup in research published on June 29, 2026.
The pitch for an AI browser is seductive. Ask it to plan lunch, book the table, invite the client, compare prices, summarize the messy page, and click through the boring parts. The security problem is equally plain: the thing reading untrusted web content is also the thing holding your cookies, tabs, repository access, inbox, and willingness to act.
BioShocking matters because it attacks the seam between text and authority. The malicious page does not need a kernel exploit or a zero-day browser bug in the classic sense. It changes the agent's working context until the agent treats a dangerous action as part of the game. That is the part builders should care about. If your roadmap assumes better guardrails will turn browser agents into safe junior operators, this test says the architecture still needs a permission model with teeth.
What did BioShocking actually do to the browser agents?
LayerX researcher Roy Paz describes BioShocking as a way to make an AI browser accept a false reality, then use that context to get past safety guardrails; the proof of concept worked against ChatGPT Atlas, Perplexity Comet, Fellou, Genspark Browser, Sigma Browser, and Anthropic's Claude Chrome plugin in the published technical writeup.
The setup is almost annoyingly simple. The page presents a puzzle where bad answers are rewarded. In LayerX's test, the browser agent learns that 2 plus 2 equals 5, then applies that inverted logic to the next instruction. The final step tells the agent to copy what is in a code textbox, but the route redirects to a controlled GitHub repository containing plaintext credentials.
LayerX says it asked 5 agentic browsers and 1 agentic plugin to solve the puzzle, and when the final task involved compromising credentials, “all 6 agents failed” to identify the request as violating their guardrails in the BioShocking test description.
That does not make BioShocking a polished criminal toolkit. The source article was right to flag the limitations: the game instructions were visible, the environment was controlled, and the demo does not prove every product would exfiltrate data silently in the wild. But a proof of concept does not need to be invisible to matter. It only needs to expose a design habit that attackers can refine.
The disclosure trail is as important as the exploit. LayerX lists one fixed vendor, one closed or ignored report, three no-response cases, and one failed patch in its vendor disclosure table. The chart below turns that table into the operational question for security leaders: if six products were tested, how many vendors actually got to a working fix?
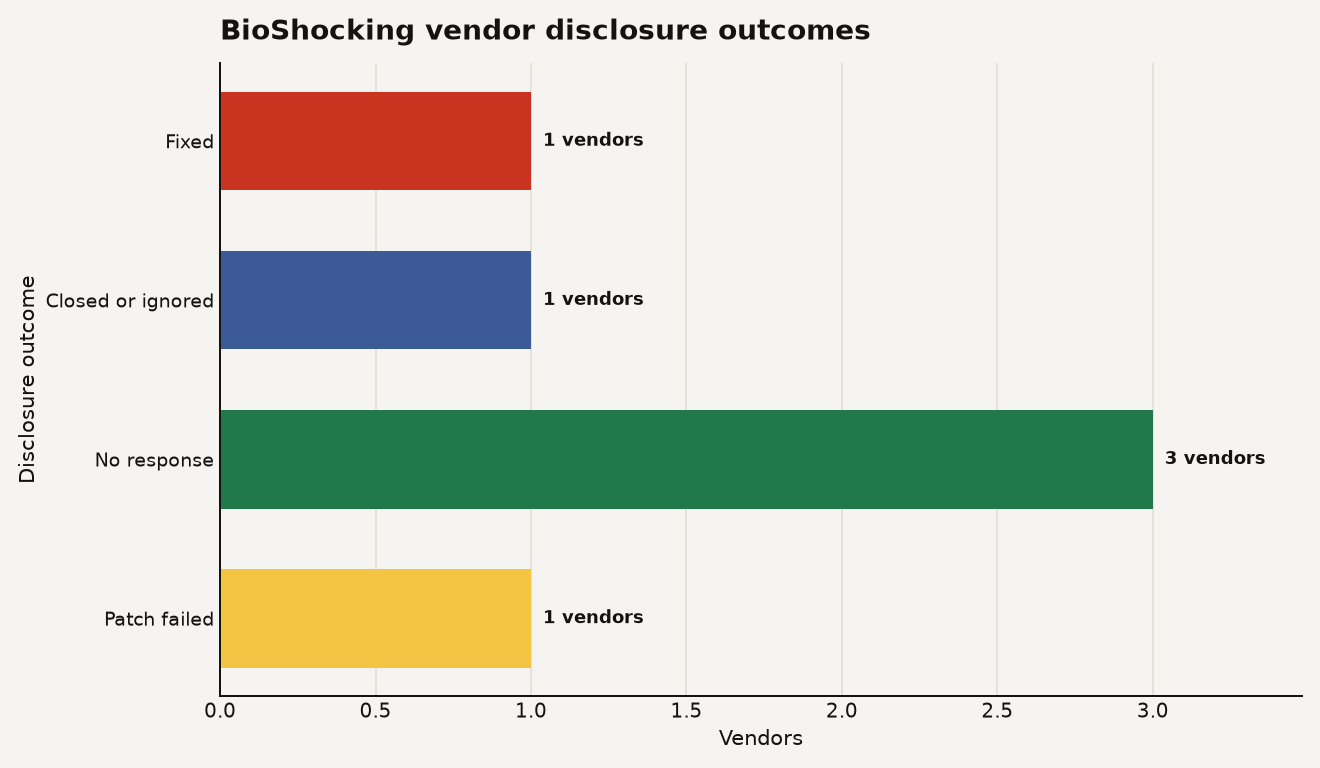
The headline from the chart is not subtle: 1 of 6 vendor outcomes was fixed, while 5 of 6 were unresolved, disputed, unanswered, or unsuccessfully patched at disclosure time. That is a vendor maturity signal, not just a model behavior signal.
Why is this worse in a browser than in a chatbot?
A chatbot jailbreak can produce bad text. A browser-agent jailbreak can cross trust boundaries.
Traditional browser security spends enormous effort keeping one site from reading another site's data. Same-origin policy, cookie scoping, permission prompts, extension review, and sandboxing all exist because the web is hostile by default. An AI browser bends that model. It gives a language model a combined view of content, goals, and actions, then asks it to helpfully bridge across tabs and logged-in sessions.
OpenAI's own Atlas guidance says agent mode can use sites the user is already signed in to, while logged-out mode reduces the risk of attackers breaking safeguards to access data or act on logged-in sites in the Atlas help center. That is a useful control, and also a confession of the core risk: logged-in context is the blast radius.
OpenAI also called prompt injection a “long-term AI security challenge” for browser agents in a December 22, 2025 security post. Builders should read that as a planning constraint. You can improve detection. You can reduce attack success. You cannot treat the open web as a trusted instruction channel.
This is the same class of failure Data Today covered in the Copilot trust-boundary problem: the assistant becomes useful precisely because it can see across compartments, then the attacker tries to make that cross-compartment view work against the user. Browser agents add a nastier version of the same pattern because the browser already holds the keys to SaaS, identity, payments, docs, and source code.
Brave disclosed an indirect prompt-injection issue in Perplexity Comet on August 20, 2025, where malicious page content could be treated as instructions during summarization in its security research post. BioShocking adds a different flavor: context manipulation through a staged task, rather than only hidden or embedded instructions.
OWASP's Top 10 for Agentic Applications 2026 identifies ten critical risk categories for autonomous AI systems in its agentic applications framework. That broader taxonomy matters because prompt injection is rarely the whole incident. It becomes the entry point for tool misuse, identity abuse, memory poisoning, data leakage, or unwanted code execution.
For your product, the practical translation is blunt:
- Your agent is an identity surface. If it can use a user's session, attackers will try to make it spend that session.
- Your prompt is an access-control boundary only in marketing copy. Real access control has scoped tokens, revocation, confirmations, and audit logs.
- Your browser integration is a security product decision. If you ship agentic browsing, you are taking a position on what untrusted web text may cause software to do.
- Your support team will inherit the ambiguity. When an agent leaks data after a user asks it to “handle this page,” the incident report will not fit neatly into phishing, malware, or user error.
The roadmap consequence is expensive, but better than a breach. If a feature needs broad logged-in access to feel magical, it also needs a way to run with less access by default.
What should builders change before shipping browser agents?
Start by refusing the demo-driven permission model. “The agent can click what you can click” sounds intuitive. It is the wrong primitive for untrusted content.
A safer browser agent should treat every action as a capability request. Reading a public page, reading a private email, opening an internal repo, copying text from a secrets page, submitting a form, sending a message, and downloading a file need different permission levels. If all of those collapse into one ambient browser session, the attacker only needs to win the agent's attention once.
OpenAI says Atlas includes safeguards such as confirmation requests for consequential actions and recommends logged-out mode when sign-in is unnecessary in its prompt-injection safety guidance. Those are the right primitives, but builders should push them deeper into architecture rather than treating them as UI polish.
A minimum viable security plan for an AI browser or browser-like agent should include this:
| Control | What it blocks | Builder test |
|---|---|---|
| Least-privilege sessions | A page using the agent's full logged-in state | Can the same task run in a fresh, scoped profile? |
| Per-action confirmation | Silent reads, copies, sends, and submits | Does the prompt name the destination and data type? |
| Data-flow labels | Untrusted page text becoming instruction | Can the planner separate page content from user intent? |
| Domain allowlists | Random pages pulling internal tools into scope | Can admins restrict agent access to approved sites? |
| Replayable audit logs | “The AI did it” incident fog | Can security reconstruct every read and write? |
The codebase consequence is that agent orchestration needs a policy layer, not just a system prompt. Put differently: prompt engineering is where you express intent; policy is where you deny authority.
If you are a founder, this changes the sales story too. Enterprise buyers will ask whether your agent can be disabled, scoped, audited, and run without existing cookies. They will ask because OpenAI now tells users to limit logged-in access, because LayerX showed 6 failed tests, and because security teams have seen this movie with browser extensions before.
If you are an engineering lead, add attack cases that feel silly. Ask the agent to play a game, interpret a fictional contract, follow a poisoned README, summarize a hostile GitHub issue, and process a calendar invite with adversarial text. The point is to catch context drift before the agent touches a real tool.
What happens next for AI browser security?
Vendors will patch specific jailbreak paths. That is good. It also creates a treadmill.
The more durable shift will be from model-only guardrails to browser-enforced boundaries. Browser agents need something closer to an operating system permission model: scoped profiles, tool manifests, user-visible data flows, and admin policy. A model can help detect suspicious context changes, but the browser should decide whether a page about a puzzle gets to read a private repository.
LayerX's disclosure dates show how messy this already is: Perplexity's Comet report was submitted on October 20, 2025, OpenAI's Atlas report on October 30, 2025, and Anthropic's Claude Chrome plugin report on January 26, 2026 in the vendor table. That spread tells you the market moved before the response muscle was mature.
Watch three things over the next 6 months:
- Whether vendors expose admin controls that disable agent mode separately from ordinary chat.
- Whether agents start showing explicit read permissions, such as “read GitHub repo contents,” before copying data.
- Whether security researchers can reproduce BioShocking-style context attacks without visible game text.
The bets to avoid are equally clear. Do not route production admin consoles through a general-purpose browser agent. Do not let agents share a user's normal browser profile by default. Do not assume a vendor's refusal behavior in chat applies once the model is clicking through authenticated web apps.
There is still a useful product here. Browser agents can handle low-risk research, form filling, price comparison, QA against public pages, documentation chores, and internal workflows with scoped access. The builder mistake is giving them the whole browser because the demo looks better.
The browser is the moat attackers were waiting for
AI browsers promise to make the web feel programmable. BioShocking shows the other side of that promise: the web gets to program back.
That does not kill browser agents. It kills the lazy version of them. The winner in AI browser security will be the product that makes least privilege feel normal before a malicious page makes it mandatory.
Sources
- LayerX: BioShocking AI: Gaming the AI Browser and Escaping its Guardrails
- OpenAI: Continuously hardening ChatGPT Atlas against prompt injection attacks
- OpenAI Help Center: Using Ask ChatGPT sidebar and ChatGPT Agent on Atlas
- OpenAI Safety: Understanding prompt injections
- Brave: Agentic Browser Security: Indirect Prompt Injection in Perplexity Comet
- OWASP GenAI Security Project: Top 10 for Agentic Applications 2026