If you train or adapt models for a living, the leaderboard is the easy part. The expensive part is the Tuesday afternoon question: did this checkpoint actually improve, or did you just get a flattering roll of the benchmark dice?
olmo-eval is an open evaluation workbench for the model development loop, and its most useful promise is statistical humility.
Allen Institute for AI released olmo-eval on June 12, 2026, positioning it as a workbench for teams that evaluate the same LLM across many data, architecture, hyperparameter, and scale changes. The key number is small on purpose: the launch post asks whether a 2.4 percentage-point change is enough to make a call. That is the question most eval stacks dodge. olmo-eval tries to make it a first-class workflow question, with standard errors, minimum detectable effects, and prompt-by-prompt comparison rather than a single celebratory average.
This matters because model development has outgrown the old pattern: train, run a benchmark suite, paste the table into a release note, move on. Builders now tune models continuously, wrap them with tools, compare scaffolds, swap judge models, and ship agentic features that fail in ways a static multiple-choice benchmark never sees. If your eval system only produces a final score, it is blind during the part of the work where money gets burned.
What did Ai2 actually release with olmo-eval?
Ai2 describes olmo-eval as a unified workbench for evaluating language models throughout development, with a task registry, composable suites, inference through vLLM and LiteLLM, multi-turn agentic evaluation, sandboxed environments, LLM-as-judge scoring, and instance-level prediction storage in the project’s Apache-2.0 GitHub repository. The framing is practical: you define what is being measured separately from how the model is run.
That separation sounds like software architecture trivia until your team has 40 experiments in flight. In olmo-eval, a task defines the benchmark dataset, prompt formatting, and scoring. A suite groups tasks. A harness controls runtime policy, including providers, tools, scaffolds, sandboxes, and auxiliary judge models. The same benchmark can run as a plain baseline or with search tools without changing the task itself.
That is the right abstraction boundary.
The launch post lists 4 core components: a task, suite, and harness abstraction; a sandbox and capability-routing layer; a normalized experiment schema; and a results viewer for pairwise model comparison. The last piece is the one teams will feel. Pairwise comparison means you can line up checkpoint A and checkpoint B on the same questions and see which examples flipped, rather than arguing over a mean score that moved by 0.8 points.
The important design choice is that olmo-eval does not force every evaluation through a container. A basic question-answering benchmark can run directly. A benchmark that executes model-written code can get an isolated container. That matters for cost and iteration speed. If every eval path carries the overhead of the heaviest agent benchmark, teams will run fewer evals, and fewer evals produce louder guesses.
olmo-eval also builds on Ai2’s older OLMES work. The OLMES paper argued that language model scores were hard to compare because papers and releases varied prompt formatting, in-context examples, probability normalization, and task formulation. That was a scoreboard problem. olmo-eval turns the same discipline inward, into the messy loop before a model is done.
Why is a 2.4 point gain such a dangerous number?
A 2.4 percentage-point gain can be real. It can also be noise, a prompt artifact, a judge-model quirk, or one lucky slice of a small eval set. The danger is not that builders are bad at statistics. The danger is that product roadmaps reward a clean green arrow more than they reward an honest uncertainty interval.
OLMES gives a clean example of why implementation details can swamp small gains. In its MMLU analysis, the authors report macro averages over 57 subject tasks and micro averages over 14,042 individual questions. The chart below shows macro MMLU scores for four models under two scoring families reported in the paper: MCF macro and CF macro. Llama3 70B scored 79.8 under MCF macro and 60.7 under CF macro, a 19.1-point swing. OLMo-7B moved the other way, from 28.3 under MCF macro to 40.5 under CF macro.
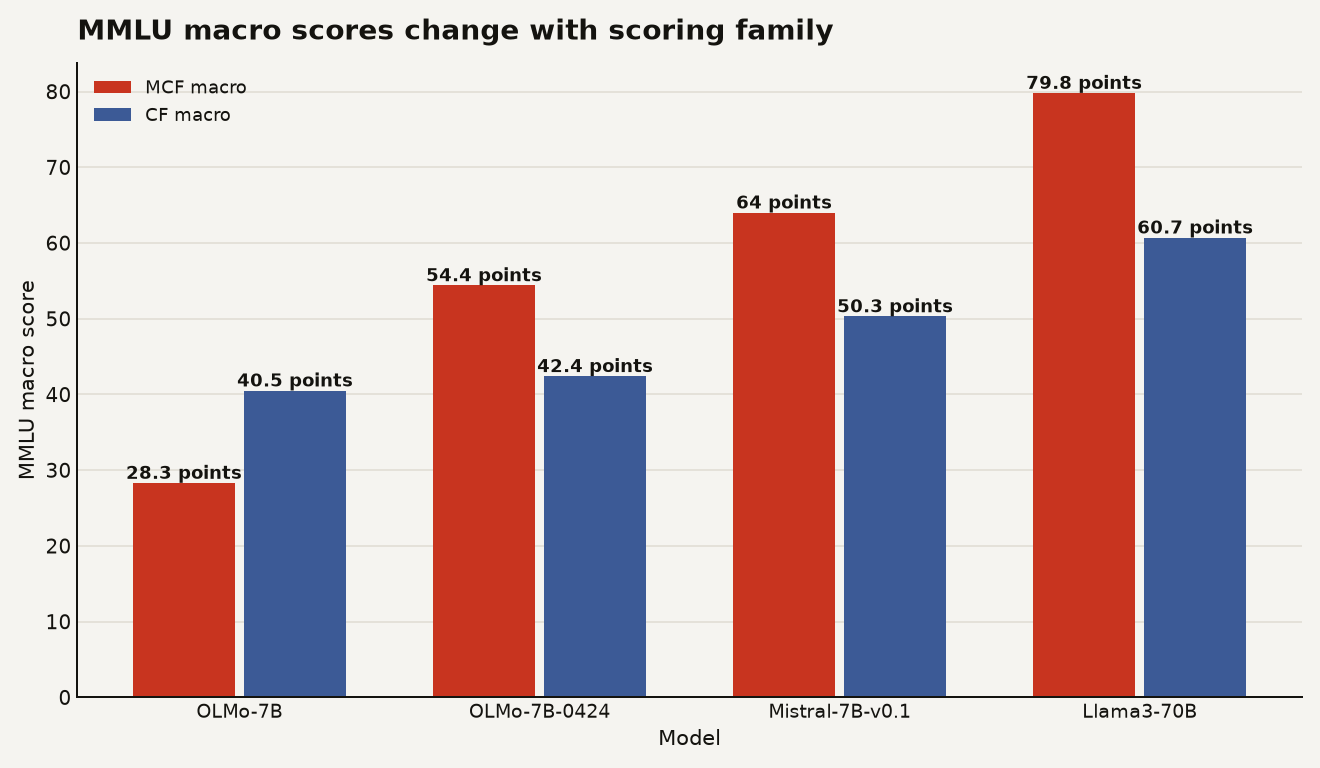
That is the case for disciplined eval plumbing in one chart. If a scoring choice can move MMLU by 12 to 19 points on named models, a 2.4-point checkpoint gain should not trigger a victory lap until the harness, prompt, sampling, judge, dataset version, and uncertainty all line up.
This is also why olmo-eval’s instance-level view matters. Aggregate scores hide which examples changed. A new data mixture might improve math word problems while breaking instruction following. A search harness might boost fresh facts while teaching the model to over-browse. A judge model might grade one phrasing more generously after a prompt tweak. Those are different failures, and they call for different fixes.
Harbor is the obvious comparison because it attacks agent evals with containerized environments. The Harbor repository describes a framework for evaluating and optimizing agents and language models in container environments, including arbitrary agents such as Claude Code, OpenHands, and Codex CLI. Harbor is a serious tool for publishable agent benchmarks and scalable sandbox runs. olmo-eval is aimed at a different pain: the daily checkpoint grind inside model development.
The blunt read: Harbor is for proving an agent can survive a course. olmo-eval is for deciding whether today’s training intervention deserves another million tokens, another GPU week, or a rollback.
What changes for your codebase, roadmap, and budget?
If you are building on top of frontier APIs only, olmo-eval may look like someone else’s problem. It is not. The same failure mode hits app teams, agent teams, and model teams: you ship based on a score whose variance you never measured.
The developer consequence is that evals need to become code with interfaces, not notebooks with vibes. A task object should own the dataset and scoring. A harness should own runtime policy. A results store should preserve the exact run config. That is less glamorous than a new agent demo, but it is the difference between debugging and folklore.
For a product lead, the consequence is roadmap triage. When eval output includes a standard error and a minimum detectable effect, you can stop treating every tiny increase as a launch reason. You can ask whether the change clears the effect size your business cares about. If support deflection needs a 5-point accuracy lift to change staffing, a 1.1-point benchmark gain is a research note, not a hiring plan.
For a founder, the cost consequence is even sharper. Evals are compute spend with a feedback function. If your eval stack is slow, brittle, or too heavyweight, your team will run it less often. If it produces only an aggregate score, your team will argue longer after every run. Both burn runway.
Here is the practical breakdown:
- Codebase: define eval tasks and runtime harnesses separately, so a tool-use experiment does not fork the benchmark itself.
- Roadmap: require minimum detectable effects for model changes that affect launch, rollback, or pricing decisions.
- Costs: keep lightweight evals lightweight, and reserve containers for code execution, browsing, or other side-effect-heavy tasks.
- Hiring: value engineers who can build eval infrastructure, not only model wrappers. The bottleneck is increasingly measurement.
- Moat: proprietary eval sets and clean historical run data become operational assets, especially when public benchmarks saturate.
This connects to a broader shift we have covered in turning ground truth into a process: the winning teams are not the ones with the prettiest benchmark table. They are the ones that can explain why a score moved, reproduce the run, and decide what to do next.
There is a healthy skepticism to apply here. olmo-eval will not rescue a bad eval. If your task set misses the workflows users care about, a cleaner harness only gives you cleaner irrelevance. If your judge model is biased, instance-level storage records the bias with excellent metadata. Tooling raises the floor. It does not make measurement strategy optional.
What should a serious team do with olmo-eval this month?
Start small. Do not migrate your entire evaluation estate because a new workbench exists. Pick one model or agent workflow where your team already argues about small deltas. A retrieval assistant, coding agent, customer-support classifier, or internal fine-tune is enough.
Then run a 30-day eval hardening pass:
- Choose 3 to 5 recurring eval tasks that map to business risk, not public leaderboard prestige.
- Freeze the task definitions and separate them from runtime settings such as tool access, system prompts, and providers.
- Store every run with model ID, dataset version, prompt version, sampling settings, judge model, and timestamp.
- Compare checkpoints at the instance level before celebrating an aggregate gain.
- Decide in advance what effect size matters. A 0.6-point gain is not a strategy if your users cannot feel it.
olmo-eval’s specific APIs may or may not become your long-term standard. The pattern should. Your eval infrastructure should answer a concrete question: what changed between these two runs, and is the difference large enough to act on?
Watch two things next. First, whether Ai2 and outside contributors add enough high-quality task wrappers to make the workbench useful beyond the Olmo and Tulu ecosystem. Second, whether teams use the minimum detectable effect idea in release notes. The public benchmark world loves clean ranks. A note that says a change did not clear the detectable threshold is less marketable, but far more useful.
The agentic side is also where this gets interesting. olmo-eval supports multi-turn loops, tool calling, scaffolds, and sandboxes. That puts it near the messy frontier where a model’s answer depends on actions it takes: writing code, browsing, calling tools, and reading results back into context. Static QA evals still matter, but they are no longer enough for systems that can touch a repo or a browser.
One caveat: do not confuse reproducible containers with safe production behavior. A sandboxed benchmark can tell you whether an agent completed a task in a controlled environment. It cannot prove the same agent behaves safely with your credentials, your network, and your customers. Keep evals close to reality, but do not mistake the lab for the blast radius.
The useful eval is the one your team reruns
The best part of olmo-eval is not that it adds another tool to the already crowded eval shelf. It is that it treats evaluation as a loop, not a ceremony.
That is the right posture for 2026. Models change weekly. Agent scaffolds change daily. Your eval system has to keep up without turning every comparison into a bespoke integration project. If olmo-eval pushes more teams to ask whether a 2.4-point gain is detectable before they spend against it, it will have done something more valuable than launch another benchmark.
It will have made progress a little harder to fake.