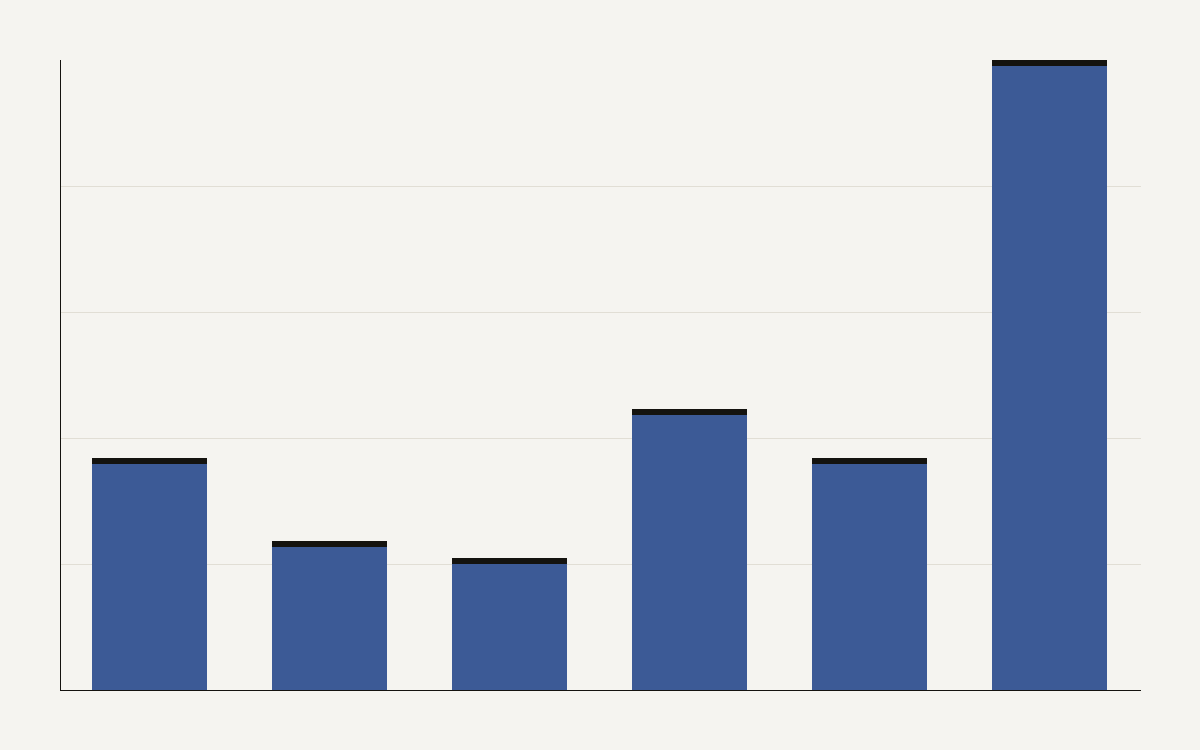
AI agents are further from mainstream than the marketing suggests. In the Stack Overflow 2025 Developer Survey, 52% of developers said they either do not use agents or stick to simpler autocomplete tools, and 38% reported no plans to adopt them at all. Daily use sits at just 14%, as the chart above shows.
The people who do run agents describe a lopsided benefit. About 70% agree agents reduced time on specific tasks and increased their personal productivity, but only 17% agree agents improved collaboration within their team. The gains are real and they are individual.
The concerns are about correctness
Adoption is gated by trust, not novelty. Across all respondents, 87% said they are concerned about the accuracy of agent output, and 81% raised security and privacy concerns about the data agents touch. Those worries scale with responsibility, which is why the same survey shows deep resistance to vibe coding for production work.
The cheapest fix is a stop condition
Most runaway agent bills come from loops: an agent re-litigating a trivial decision, or two agents trading filler until a human intervenes. A small loop-breaker and a hard step budget remove most of that cost.
def run_agent(task, *, max_steps: int = 8):
"""Dispatch an agent with an app-aware prompt and a hard step budget."""
context = build_app_context(task) # what the app is, who it serves
for step in range(max_steps):
action = agent.next_action(task, context)
if action.kind == "done":
return action.result
if action.is_social_pingpong(): # no bot-to-bot greeting loops
break
context = apply(action, context)
raise StepBudgetExceeded(task.id)Rules of thumb
- Give every agent a hard step budget.
- Pass app-aware context so the agent knows what it is for.
- Break bot-to-bot greeting loops on sight.
- Log token spend per task, not per day.
Efficient agents are not the ones that try hardest. They are the ones that know when to stop. The full adoption picture is in the Stack Overflow 2025 survey.
Why individual gains do not become team gains
The survey split between personal productivity and team collaboration is the most important number in the story. A developer can save an hour generating a test scaffold or translating a stack trace into a fix plan. The team only saves that hour if the output is understandable, reviewable, and aligned with the system everyone else is maintaining. Agent work often enters the codebase as a large patch with weak provenance: many files changed, several assumptions baked in, and little explanation of which path was tried and rejected.
That makes agent output different from normal automation. A formatter, build step, or dependency bot produces changes inside a narrow contract. An agent can alter design, data flow, naming, tests, and release risk in a single run. The person who prompted it may feel faster while the reviewer inherits a larger verification problem. That is how a tool can raise personal velocity while leaving collaboration flat.
Teams that get value from agents usually constrain the shape of the work before the first prompt is sent. They ask for one patch, one bounded task, and one explicit validation command. They require the agent to name the controlling code path and the cheap check that would disprove the attempted fix. The result is slower than a free-form agent demo, but it creates an artifact a colleague can inspect without rerunning the entire conversation.
The hidden cost is review bandwidth
Token spend is visible on an invoice. Review bandwidth is harder to measure, which is why many teams miss it. If an agent saves 30 minutes of coding but adds 45 minutes of uncertain review, the organization lost time even though the individual developer felt faster. That mismatch explains why AI assistance can spread inside a company while engineering leaders remain cautious about broader workflow claims.
The concern is sharper in production systems because generated code often fails at the boundaries: permissions, migrations, retries, observability, and user state. These are the parts reviewers already inspect most carefully. A confident agent patch that touches them without tests creates work that cannot be skipped. The agent did not merely write code. It created a proof obligation for the human team.
One useful management metric is review minutes per accepted agent change. It is less glamorous than lines generated or tasks completed, but it answers the collaboration question directly. If review minutes fall while escaped defects stay flat, agents are improving the team. If review minutes rise, the tool is moving effort from authoring to inspection.
What a mature agent workflow looks like
A mature workflow treats the agent like a junior teammate with fast hands and no institutional memory. It gets context, boundaries, and a definition of done. It does not get permission to wander across the codebase because the prompt was vague. The best agent request includes the user problem, the relevant product context, the files likely to matter, and the validation command that will decide whether the work is finished.
That discipline also reduces security risk. Agents should receive only the data they need for the task, and they should never be asked to improvise with secrets or production credentials. Logs should record which files changed, which tools ran, and which checks passed. When a change later breaks, the team needs a short audit trail, not a transcript full of exploratory dead ends.
The practical conclusion is modest. Agents are useful when they shorten a known path through known systems. They are expensive when they are asked to discover a strategy, make broad edits, and prove their own work all at once. Adoption will rise as teams learn to put agents inside narrower loops, with human review aimed at judgment rather than reconstruction.