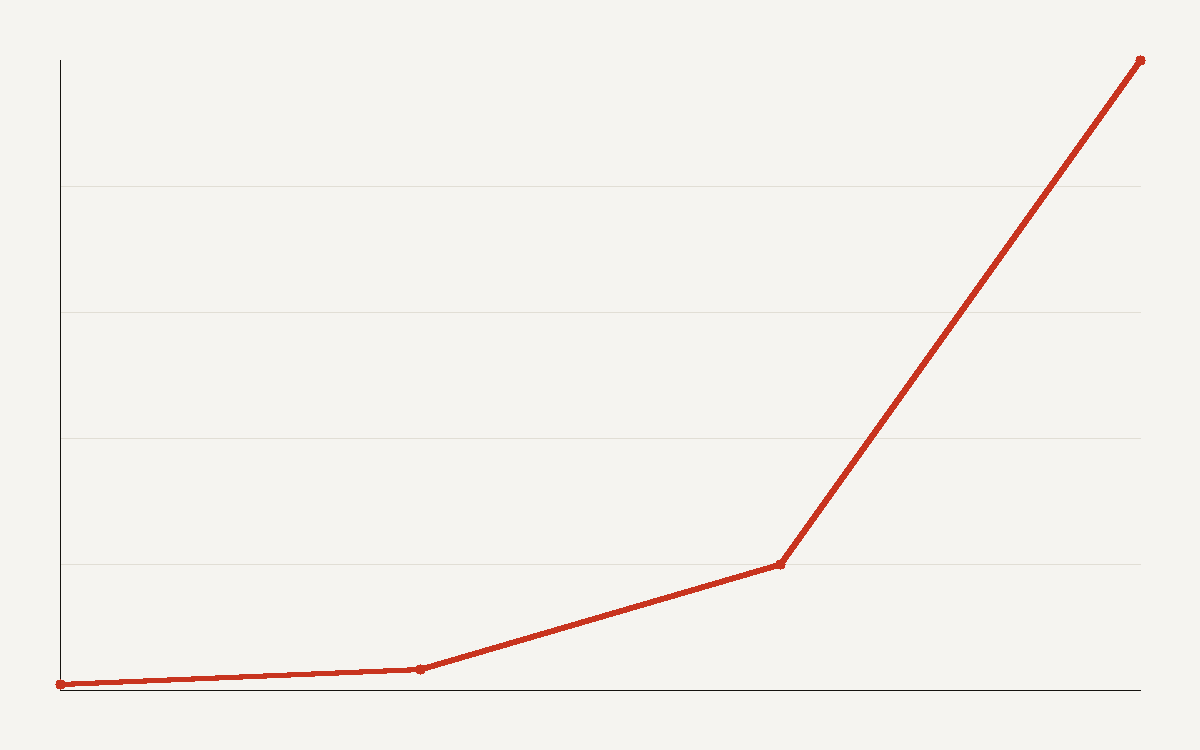
A model's working memory has grown faster than almost any other capability. Epoch AI puts the growth in context window size at about 30 times per year since 2023, taking the maximum from a few thousand tokens to well over a million. A full codebase, a quarter of legal filings, or a book now fits in a single prompt.
That shift changes the engineering calculus around retrieval. For two years the standard answer to a long document was to chop it into chunks, embed them, and fetch the closest few at query time. When the window holds a million tokens, the question becomes which problems still need that machinery at all.
When to stop chunking
def strategy(doc_tokens, window=1_000_000, budget_per_query_usd=0.03,
price_per_mtok=0.4):
cost_full = doc_tokens / 1_000_000 * price_per_mtok
if doc_tokens <= window and cost_full <= budget_per_query_usd:
return "stuff the whole document"
return "retrieve: corpus too big or too costly to stuff every call"
print(strategy(120_000)) # a long report
print(strategy(40_000_000)) # a full corpusThe rule is mundane and that is the point. If the source fits the window and the token cost fits the budget, stuffing beats retrieval on both accuracy and engineering effort. Retrieval earns its complexity when the corpus is far larger than any single window or when per-query cost rules out sending everything.
What still breaks at length
- Attention dilution: models still lose facts buried mid-context, so position matters even when everything fits.
- Cost: a million-token call is not free, which ties back to where inference money still goes.
- Latency: long prompts are slow prompts, so cache the stable prefix.
Long context did not kill retrieval. It moved the line where retrieval pays for itself. The context-window trend is tracked by Epoch AI.
Long context changes failure modes
Retrieval systems fail when they fetch the wrong chunk or miss the one sentence that matters. Long-context systems fail differently. They may receive the right document and still overlook a buried clause, overweight a repeated but less important section, or mix instructions from unrelated parts of the prompt. The engineering problem moves from finding text to organizing attention.
That is why prompt structure matters more as windows grow. A million-token input should not be treated as a giant paste buffer. Stable instructions, source summaries, document tables, and explicit citations help the model navigate the material. Putting the most important constraints at the start and end of the context can also reduce mid-context loss.
The best systems combine long context with retrieval rather than choosing one ideology. They retrieve the most relevant documents, then provide enough surrounding material for the model to reason without guessing. They also cache static context, so a large policy manual or codebase does not have to be resent from scratch on every question.
Cost turns architecture into policy
The decision to stuff a document into the prompt is partly technical and partly economic. If a full-document call costs less than the engineering time required to maintain a retrieval stack, stuffing is rational. If the same call runs thousands of times a day, cost and latency can make retrieval necessary even when the window is large enough.
That trade-off should be visible to product managers. A legal research tool may accept a slower, more expensive call because the value of a correct answer is high. A customer-support assistant may need aggressive retrieval and routing because volume is high and many questions are routine. The right architecture depends on task value, not only token count.
The policy layer is data access. Long context makes it tempting to send everything. Good systems still apply least privilege. They include the material needed for the answer, exclude restricted content, and log which sources were used. Bigger windows increase the need for access control because they make it easier to move large amounts of sensitive text in one request.
What to measure before rebuilding RAG
Teams considering a long-context rewrite should run a simple bake-off. Choose a representative set of questions, answer them with the existing retrieval system, then answer them by placing the full source or a larger source bundle into the context. Score correctness, citation quality, latency, cost, and review effort. The winner may vary by question type.
They should also measure maintenance burden. Retrieval pipelines need chunking rules, embedding refreshes, indexes, metadata filters, and monitoring. Long context needs prompt organization, caching, permission checks, and cost controls. Neither approach is free. The point is to pay for the failure mode you can manage.
Longer windows are a genuine platform shift because they remove whole classes of retrieval work for documents that fit comfortably inside the budget. They also raise expectations. Users will assume the model saw the document they provided, so overlooked facts become less forgivable. Bigger memory makes the system feel smarter only when the answer proves it used that memory well.
The durable rule
Use the window when the question depends on one bounded source. Use retrieval when the question depends on a changing corpus, a large archive, or strict access rules. Use both when the user needs citations and context around each cited source. That rule is simple enough for product planning and specific enough to prevent expensive rewrites driven only by launch announcements.
The biggest mistake is treating context size as a substitute for information architecture. A larger window lets more text enter the model. It does not decide which text deserves attention, which source is authoritative, or which answer is safe to show.