Vibe coding turns product ideas into public URLs before anyone has decided who is allowed to read the database. That is the vibe coding security problem in one sentence: RedAccess found 5,000 sensitive-data assets among 380,000 publicly accessible AI-built assets, according to Axios reporting on the security firm’s scan.
The new warning is simple and uncomfortable. The risky moment is often the publish button, not the prompt box. A local toy that tracks your workouts is one risk profile. A hosted app with customer logs, medical notes, financial records, strategy docs, or internal chatbot transcripts is software that can hurt other people.
The Verge put faces on that shift on June 22, 2026, reporting on builders including Bob Starr, whose vibe-coded tax-spending site had a hidden SQL injection risk, and Max Segall, whose Ethereum running app had a critical account-modification flaw caught before launch by a colleague at Privy in Yael Grauer’s piece on vibe-coded app risks. Those are the lucky versions of the story. The unlucky version is already measurable.
What did the new reports actually show?
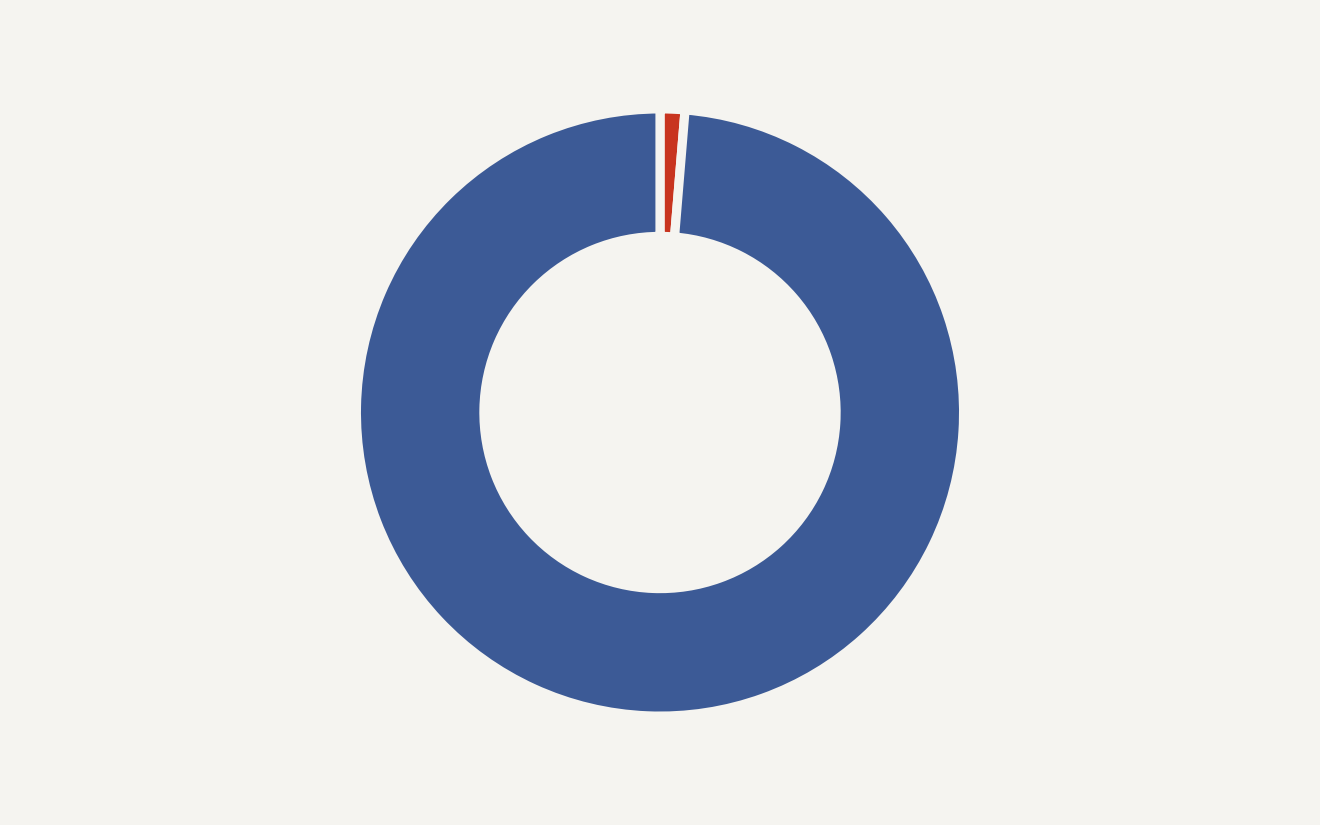
The sharpest number comes from RedAccess. Its researchers told Axios they found 380,000 publicly accessible assets built with tools from Lovable, Base44, Replit, and Netlify, including about 5,000 containing sensitive corporate data in the May 7, 2026 report. Axios independently verified examples that included clinical trial details, unredacted customer service conversations, internal financial information, patient summaries, school data, and staff schedules.
Look at the chart below: the reported scan breaks into 5,000 sensitive-data assets and 375,000 other public assets, based on the RedAccess figures reported by Axios.

That ratio can look small if you read it like a spreadsheet. It looks different if one of the 5,000 is your customer-support dashboard, investor memo, hospital intake tool, or internal sales app. A 1.3 percent leak rate across a very large, very searchable surface is plenty of blast radius.
Moltbook shows the same failure mode at celebrity scale. Wiz said it found a Supabase API key in client-side JavaScript, mapped around 4.75 million exposed records, saw 1.5 million registered agents backed by only 17,000 human owners, and found 4,060 private direct-message conversations in its Moltbook security writeup. The bug was mundane: a browser-visible key plus missing Row Level Security policies. The consequence was total read and write access where the app should have had user-scoped access.
This is why the discourse around vibe coding gets confused. AI can generate bad code, yes. Human teams have shipped bad code for decades. The bigger problem is that AI lowers the activation energy for deployment. A builder can go from idea to internet-facing database before they have named the threat model.
Why does this change the way you should ship AI-built apps?
The security boundary moved from the engineering team to the person holding the prompt. That person may be a founder, a sales lead, a policy analyst, or a developer trying to move faster. Either way, the app still ends up with routes, secrets, database permissions, OAuth scopes, storage buckets, and logs.
OWASP already treats access control as a top application risk: broken access control is A01 in the OWASP Top 10, and OWASP says its contributed dataset included 318,487 occurrences in that category in the 2021 Top 10 entry. Vibe coding does not make access control newly important. It makes access control easier to skip while the app still works.
Supabase is the clean example because the mistake is easy to explain. Supabase says Row Level Security “must always be enabled” on tables stored in an exposed schema, and its docs say the public schema is exposed by default in the Row Level Security guide. In other words: the front end can talk to the database safely only if the database knows which rows each caller may touch.
The developer consequence is concrete:
- Your app can pass a happy-path demo while leaking every row behind the button.
- Your generated code can correctly hide an API secret while still exposing product data through permissive reads.
- Your agent can “fix” a login bug by relaxing a policy, because the immediate reward is a green screen.
- Your code review backlog can grow even as your app backlog shrinks.
The business consequence is uglier. A prototype with a public URL becomes shadow IT the moment someone uses it with real company data. If it stores customer information, the app is no longer an experiment in the eyes of your customers, your security team, or your regulator.
This is the same trust-boundary problem builders keep running into with agents. We saw it in agent repositories becoming traps for coding assistants: the tool’s speed changes who gets to create risk, while the organization’s review process still assumes a smaller set of trusted developers.
Where should the security gate sit in your workflow?
The gate has to sit before publish, and then again before each material change. A security review after the app has users is cleanup. A security review before the first hosted database connection is product design.
The tooling is improving, but it still expects a workflow. Anthropic said on March 16, 2026 that Claude Code includes a /security-review command and GitHub Actions integration for automatic pull-request review in its automated security review documentation. That helps if your project has a repo, commits, pull requests, and a human who knows when to invoke the command.
OpenAI is aiming at the same bottleneck from the enterprise side. The company said Codex Security scanned more than 1.2 million commits in a 30-day beta cohort and identified 792 critical findings plus 10,561 high-severity findings in its March 2026 research preview announcement. That is useful signal, and it also proves the point: security becomes tractable when code lands in a workflow that can be scanned, threat-modeled, patched, and reviewed.
Most vibe-coded apps start outside that workflow.
So move the workflow to the app, not the other way around. Before an AI-built project can touch real data, require five artifacts:
- Data inventory: List every table, bucket, log, file, prompt, and third-party service that stores user or company data.
- Access matrix: State who can read, create, update, delete, export, and administer each data type.
- RLS or server-side enforcement: For browser-accessible databases, prove row-level policies exist. For server-only apps, prove the client cannot call privileged APIs directly.
- Secret scan: Search the client bundle, repo history, environment examples, logs, and generated config for tokens.
- Abuse test: Try anonymous access, wrong-user access, direct API calls, replayed requests, and over-broad search indexing.
Here is a prompt worth pasting before launch. It will not replace expertise, but it forces the model to reason against the right surface area:
You are reviewing this app for pre-launch security.
List every data store, route, API key, auth check, storage bucket, and log.
For each one, explain who can read and write it.
Then try to break that model as an anonymous user, a normal user, and a different user's account.
Flag any public-by-default behavior, missing RLS policy, client-side secret, permissive CORS rule, or direct database access.
Do not change code until you produce the threat model and test plan.The important instruction is the last one. Make the agent stop building and explain the system. If it cannot explain the boundary, the boundary probably exists only in your head.
What should you do before the next public URL exists?
Use a risk ladder. Vibe coding is fine for low-consequence software. It is a gift for personal tools, internal mockups, one-off scripts, dashboards over public data, and prototypes that never ingest secrets. The standard changes when the app has shared data or a public endpoint.
The Verge reported that Jack Cable, CEO and cofounder of Corridor, said vibe coding is “great for lower risk things” and urged builders to ask whether they are exposing their own or other people’s data in the June 22, 2026 story. That should be the publish checklist’s first question.
A practical ladder looks like this:
- Green: Local-only tools, public datasets, disposable prototypes, no accounts, no secrets, no hosted database.
- Yellow: Internal apps with company data, small user lists, OAuth, file uploads, or private logs.
- Red: Customer records, payment flows, health data, legal data, financial data, production credentials, or anything indexed by search.
Green can ship with automated review and common sense. Yellow needs a repo, a checklist, owner-scoped tests, and someone accountable for the access model. Red needs a real security review before launch, even if the whole product took one afternoon to create.
This will feel slower. Good. The goal is to keep the velocity that made vibe coding attractive while removing the part where “works on my laptop” quietly becomes “world-readable in production.”
The builder who can ship safely wins
Vibe coding security will separate durable builders from demo magicians. The moat is no longer just who can make the app appear fastest. The moat is who can make the app appear, know what data it touches, prove who can access it, and sleep after the URL goes live.
A generated app that ships without a publish gate is a liability with a nice onboarding screen. A generated app that ships with data boundaries, tests, and review is just software. That is the upgrade worth building.
Sources
- The Verge: Read this before you vibe-code another app
- Axios: AI vibe-coding apps leak sensitive data
- Wiz: Hacking Moltbook: AI Social Network Reveals 1.5M API Keys
- Supabase Docs: Row Level Security
- OWASP Top 10: Broken Access Control
- Claude Help Center: Automated Security Reviews in Claude Code
- OpenAI: Codex Security: now in research preview