Seattle is about to run a very public test of who gets to set the terms of the AI buildout: the companies racing for compute, or the cities asked to host the machinery.
The Seattle data center moratorium is a proposed 365-day pause on new or expanded large data centers inside city limits. It matters because the immediate trigger is concrete: four companies approached Seattle City Light about five large facilities with a combined maximum demand of 369 megawatts, which the Seattle City Council says is enough to power roughly 300,000 homes. The bigger story is that Amazon employees, including software engineers, are now testifying against the kind of infrastructure boom that powers the products their own industry is selling.
This is where the AI debate leaves the demo stage. A model launch is easy to admire. A 369 MW interconnection request has to fit through substations, utility rates, neighborhood noise limits, water systems, land use rules, and politics. That is the part builders can no longer treat as someone else’s permitting problem.
What did Seattle actually put on the table?
The proposed ordinance, listed by Seattle as Council Bill 121214, would create a new definition for data centers and impose a moratorium on filing, accepting, processing, or approving applications for new or expanded data centers. It is written as emergency legislation, which means the council is trying to stop the queue before paperwork turns into vested rights.
The companion policy is just as important as the pause. The council said the moratorium would run for 365 days, with the possibility of a six-month extension, while the city studies impacts on electrical grid capacity, water use, utility rates, land use, jobs, public health, and community well-being. That is a long list because data centers are weird civic objects: they look like real estate, behave like industrial loads, and sit at the center of a national compute race.
Seattle Mayor Katie Wilson’s office has already framed the issue as a ratepayer protection problem. In a May 1 update, the mayor said Seattle City Light was developing a large-load policy for data centers so that infrastructure and extra purchasing costs are not borne by Seattle residents and City Light customers. The threshold named by the mayor is 10 MW or more, which is tiny compared with hyperscale AI campuses but large enough to matter on a municipal grid.
The local numbers are sharp. Seattle has about 30 smaller data centers today, according to the council, but the five proposed facilities would be the first at this scale. The council’s April release says the combined 369 MW demand is equal to roughly 300,000 homes. That single comparison did most of the political work. It turned an abstract AI boom into a household power bill.
The employees made the story harder for tech companies to dismiss. The Verge reported that Amazon senior software engineer Liesl Wigand told a council committee that she sees the consequences of an all-costs-justified AI buildout in her job and urged lawmakers not to let Big Tech burn Seattle to win the AI race. Another Amazon software engineer, Patrick Schloesser, argued for requirements including 100 percent additional renewable energy and more transparency about who is behind projects.
That is the part hyperscalers should study. The opposition is not coming only from people outside the industry. It is coming from people who understand the stack.
Why is 369 MW bigger than a local zoning fight?
A 369 MW load request is large enough to make the AI infrastructure problem legible in one city. But Seattle is only the visible edge of a bigger curve. The International Energy Agency’s 2025 Energy and AI report estimates that global data center electricity consumption was 415 TWh in 2024 and projects it will reach 945 TWh by 2030 in its base case. That is more than double in six years, and the IEA says data centers would rise from about 1.5 percent of global electricity use in 2024 to just under 3 percent by 2030.
The chart below shows the scale of the jump: 415 TWh in 2024 to 945 TWh in 2030. Seattle’s fight is local, but the slope is global.
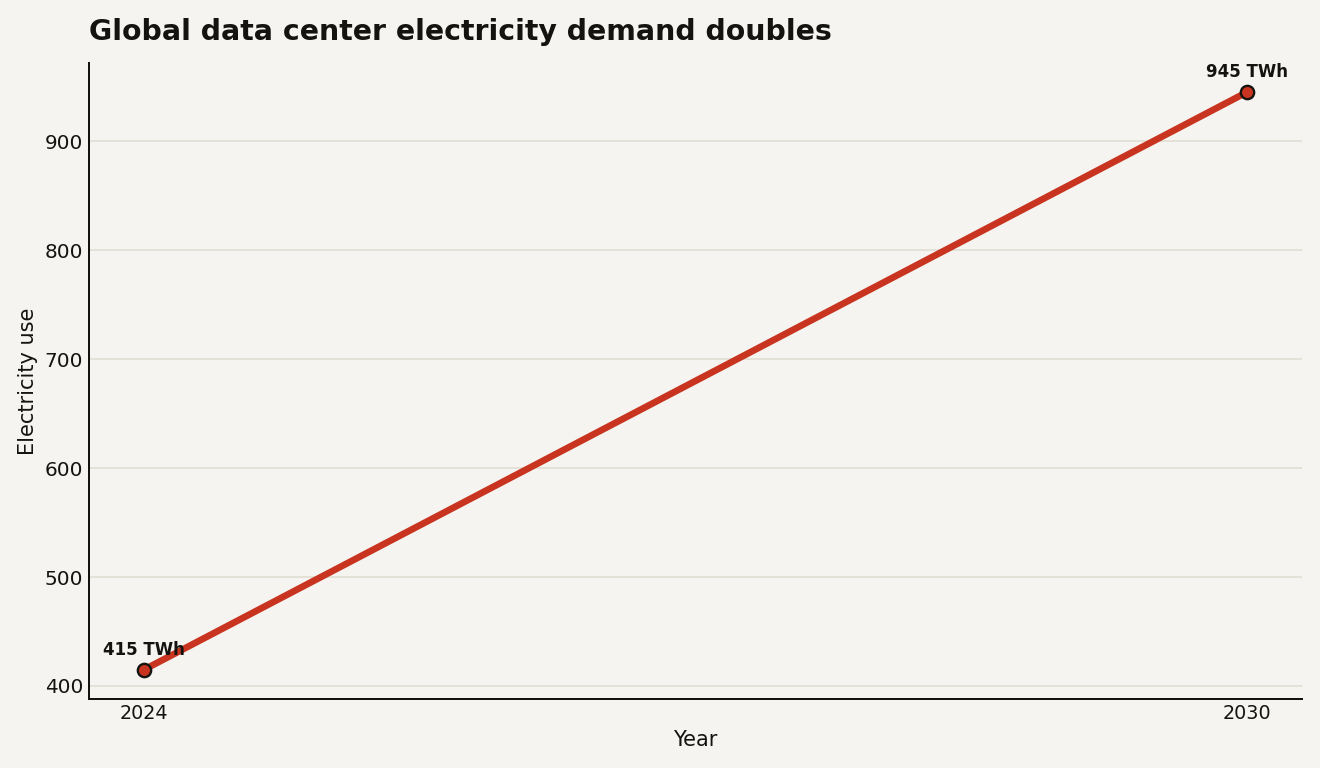
The demand curve matters because data center siting is constrained by the slowest systems around it. GPUs ship in months. Transmission lines, substations, firm power contracts, and rate cases move on civic time. That mismatch is now showing up in city halls.
Seattle is also not an isolated backlash. Charlotte approved a 150-day data center moratorium on June 8, according to Axios Charlotte, after officials said the city needed time to study power use, water use, environmental effects, noise, aesthetics, and siting. The duration is shorter than Seattle’s 365 days, but the logic is similar: municipalities are realizing that existing zoning was not written for AI-scale load growth.
The industry response usually leans on three points: data centers bring construction jobs, they can be efficient, and they support services residents already use. All three can be true. They also dodge the hard question: who pays for peak capacity, grid upgrades, backup generation, and risk if demand forecasts prove wrong?
The AI buildout is capital heavy by design. Amazon told investors in its fourth quarter 2025 earnings release that it expects to invest about $200 billion in capital expenditures across the company in 2026, citing AI, chips, robotics, and low earth orbit satellites. The company also said Trainium4 is expected to start delivering in 2027 with six times the FP4 compute performance of its predecessor. That is the corporate version of the same story: build more compute, faster, because demand is there or close enough.
For builders, the lesson is uncomfortable. Your AI roadmap may depend on infrastructure that your vendor cannot site cleanly, power cheaply, or explain politically.
What changes for developers and AI teams if cities start saying pause?
The lazy read is that Seattle is anti-tech. That misses the leverage point. The city is not trying to ban every server closet. It is trying to decide whether large new loads can connect without socializing costs onto everyone else.
If you build on top of hosted models, cloud GPUs, vector search, fine-tuning, batch inference, or agent fleets, this becomes your problem in four practical ways.
First, capacity risk moves into product planning. If hyperscalers face more local moratoriums, interconnection delays, or separate large-load rates, the cost of compute will not fall on a smooth curve. It will arrive in plateaus. One quarter your inference margin looks fine. The next quarter your provider changes pricing, quota policy, or region availability because a facility slipped by 12 months.
Second, procurement becomes a product decision. A team that picks a model only by benchmark score is ignoring the physical side of the dependency. Region, latency, carbon reporting, committed-use discounts, and workload portability now belong in the architecture review. We have been tracking this same wall in virtual power plants meeting AI’s data center power constraint, and the pattern is clear: software abstractions do not erase grid constraints.
Third, efficient software regains status. The past 18 months rewarded teams that threw more tokens, retrieval calls, agents, and eval loops at problems. A city-level compute squeeze rewards boring discipline: smaller models where they work, caching, distillation, prompt trimming, retrieval budgets, batch scheduling, and graceful degradation. The cheapest megawatt is the one your product never asks for.
Fourth, trust becomes part of infrastructure. Seattle’s testimony included complaints about shell companies and nondisclosure agreements. That matters for every AI vendor selling into public agencies, healthcare, education, or regulated industries. If your supply chain for compute is opaque, customers will treat your product as opaque too.
Here is the practical breakdown for your next roadmap review:
- If you run a high-volume inference product, model a 20 percent to 40 percent compute price shock before you promise margin expansion.
- If you depend on a single cloud region, test failover to a second region before procurement tells you the cheap capacity is gone.
- If you sell AI into cities or utilities, prepare a plain-English infrastructure disclosure: where workloads run, how much energy they use, and what customer controls exist.
- If you are hiring, value engineers who can reduce tokens, memory, and GPU time as much as those who can wire up the newest agent framework.
The moat is shifting. Access to models still matters. Access to reliable, politically acceptable, reasonably priced compute may matter more.
What should Seattle demand before it lets new AI data centers in?
A moratorium is only useful if it produces rules that survive contact with developers and utilities. Seattle should avoid two bad outcomes: a symbolic pause that changes nothing, and a blanket posture that pushes every serious load to a neighboring jurisdiction without solving the grid problem.
The city’s best path is a conditional yes. If a data center wants urban power at AI scale, it should meet a public benefit test with numbers attached.
Start with additionality. A company claiming clean power should show new generation or storage that would not exist otherwise, not just certificates shuffled on a spreadsheet. The mayor’s office has already said the city should advocate for 2027 state legislation covering clean energy, air and noise pollution standards, sustainable water use, and job quality. Put those requirements into interconnection and land use rules, not just press events.
Then price the load correctly. Separate large-load rates are boring, which is why they are promising. If a 100 MW or 300 MW customer requires new infrastructure, the tariff should assign those costs to the beneficiary. Ratepayers should not become hidden equity partners in a hyperscaler’s AI margin.
Next, require operational transparency. Public reporting on electricity use, water use, backup generator testing, noise complaints, and demand response participation should be a condition of approval. A data center that cannot disclose basic resource impact should not get the benefit of municipal infrastructure.
Finally, make flexibility valuable. AI workloads are not all equal. Some inference must happen instantly. Training, batch scoring, synthetic data generation, and offline evals can move in time or place. A facility that can curtail, shift load, or use onsite storage should receive different treatment than a facility that demands flat maximum draw around the clock.
This is where the industry can help itself. If builders want cities to believe AI infrastructure is more than a private land grab, they need to expose controllable load, publish meaningful efficiency metrics, and stop treating local review as an obstacle course.
What should you watch after the June 9 vote?
The vote is the visible event. The rate design is the main event.
Watch Seattle City Light’s large-load policy, because that will tell you whether the city is serious about cost allocation. Watch the definition of data center in the final ordinance, because a sloppy definition could catch edge facilities, enterprise server rooms, or telecom infrastructure that does not belong in the same bucket as AI-scale campuses. Watch whether any projects filed enough paperwork before the moratorium to keep moving. Timing can turn policy into theater.
Also watch whether Amazon, Microsoft, and other cloud players respond with specifics rather than slogans. Microsoft has been pushing community-first AI infrastructure messaging, and Amazon is telling investors it can monetize AWS capacity as fast as it installs it. Those claims now face a municipal exam: show the local power, local rates, local water, local jobs, and local mitigation.
The underhyped consequence is that cities are becoming part of the AI supply chain. Not as passive hosts. As gatekeepers.
If that feels inconvenient, good. The industry has spent two years pretending compute is a cloud API with no address. Seattle is asking for the address.
The city now owns the bottleneck
AI companies used to win by getting there first. In 2026, they also have to get plugged in.
Seattle’s 365-day pause will not decide the future of AI infrastructure by itself. But it sends a clean signal to every builder using someone else’s GPUs: the next bottleneck may not be a model, a chip, or a framework. It may be a city council asking why your product deserves 369 MW before residents get a straight answer.
Sources
- Seattle City Council: Council Bill 121214
- Seattle City Council: Councilmembers introducing moratorium on data centers in Seattle
- Office of the Mayor: Mayor Wilson identifies initial steps for action on data centers
- International Energy Agency: Energy demand from AI
- Amazon: Amazon.com announces fourth quarter results
- Axios Charlotte: City of Charlotte bans new data center construction for 150 days
- The Verge: Amazon employees ask Seattle to put the brakes on new data centers