Dataset: Download the open dataset from Hugging Face Datasets.
The useful thing about a phone call is also the awful thing about a phone call: there is nowhere for the model to hide. It has to hear the code, obey the policy, keep the caller calm, call the right tools, and finish the job while the caller interrupts, corrects themselves, or asks for something they are not allowed to get.
EVA-Bench Data 2.0 is ServiceNow AI's attempt to make that mess measurable. The new release expands EVA-Bench from an airline only voice agent benchmark into 213 enterprise scenarios across three domains: Airline Customer Service Management, Enterprise IT Service Management, and Healthcare HR Service Delivery. ServiceNow AI announced the release on June 4, 2026, with 121 tools, 39 workflows, and three downloadable dataset configurations.
That matters because a polished demo call is almost useless as evidence. A voice agent can sound fluid for 90 seconds and still fail the one thing that matters: changing the right ticket, preserving the right benefit, or refusing the wrong access request. If you are shipping voice agents into support, IT, HR, or healthcare operations, the question is no longer whether the model can talk. The question is whether it can survive the backend.
What did ServiceNow actually release?
ServiceNow AI released a new version of EVA-Bench, an open benchmark for evaluating task-oriented voice agents end to end. The dataset card says the benchmark now contains 213 scenarios across three enterprise voice domains, focused on cases where speaking to a human agent over the phone is realistic and necessary.
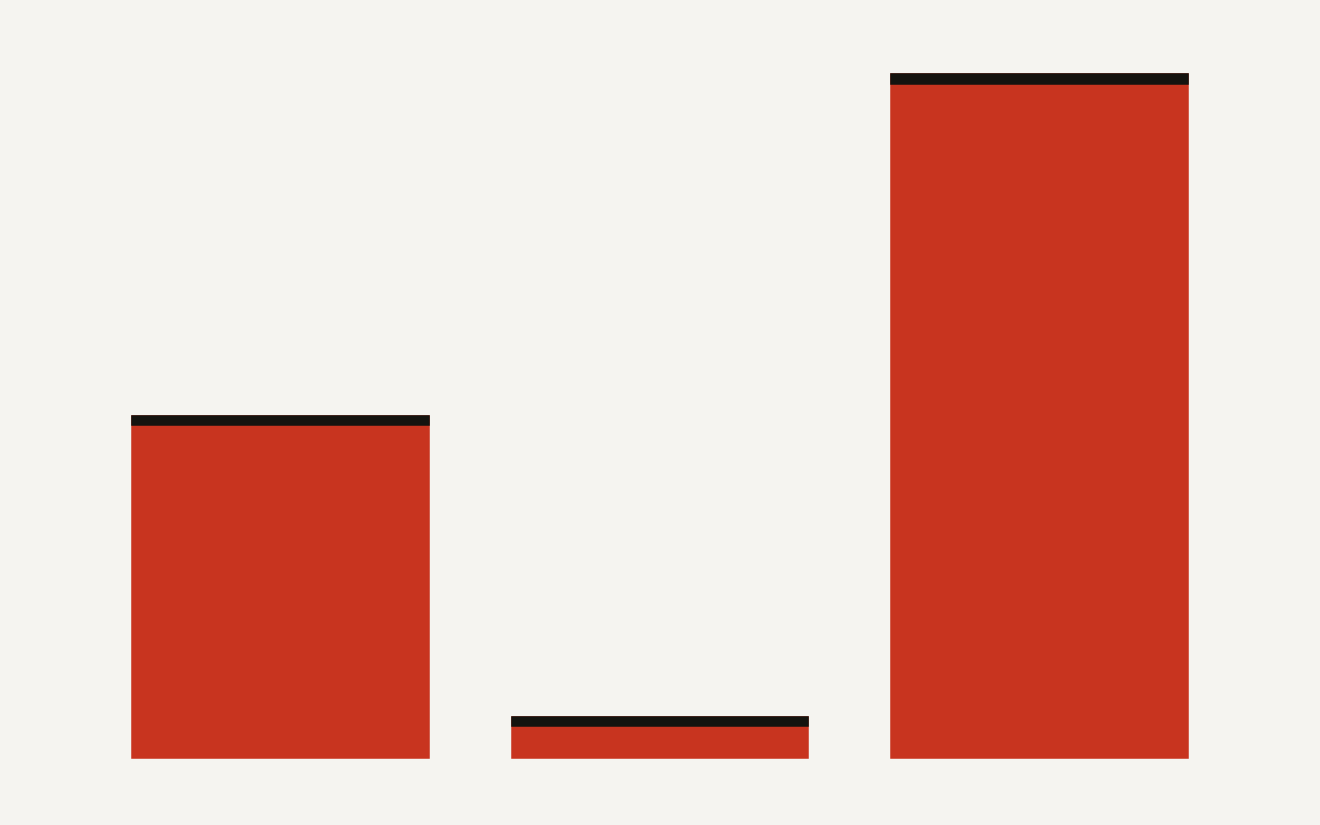
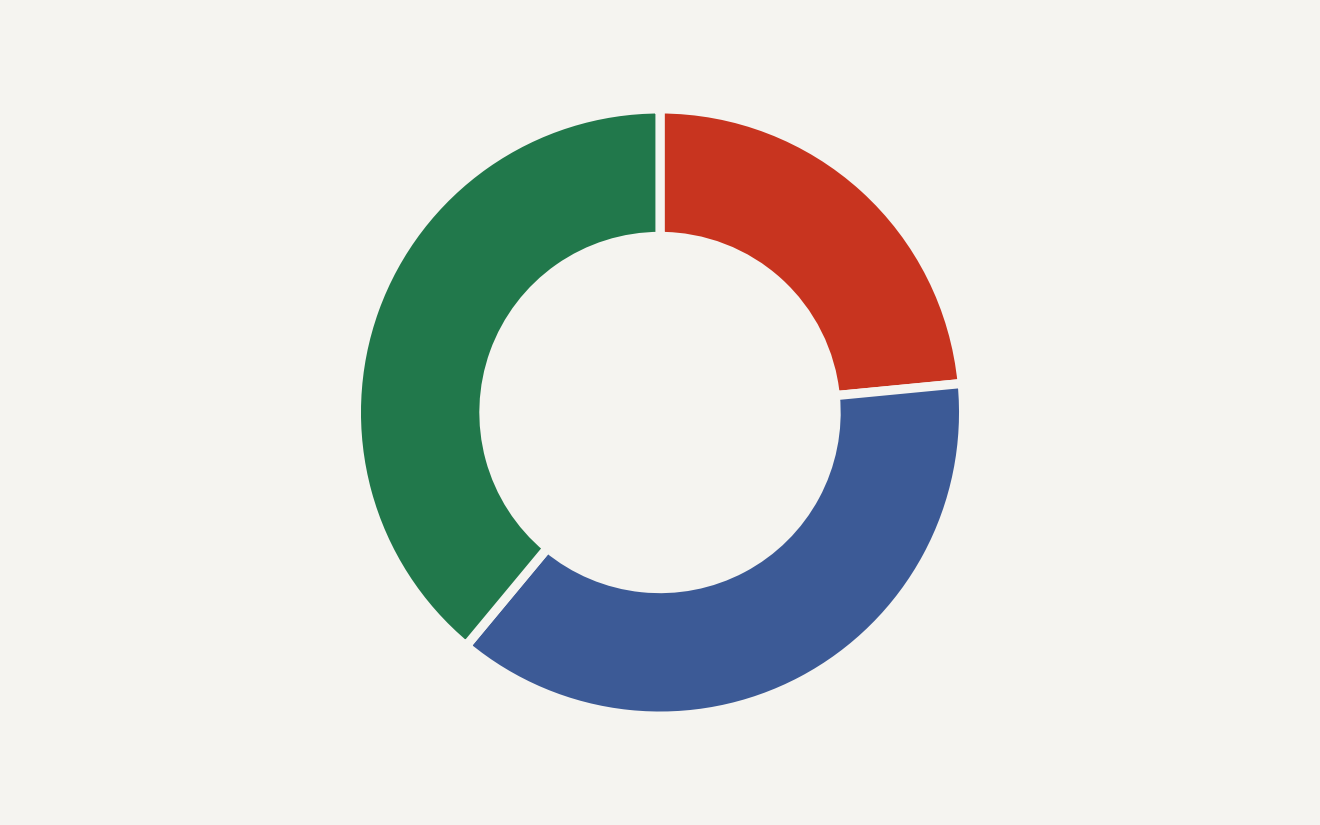
The split is uneven in the right way. Airline CSM contributes 50 scenarios and 15 tools. Healthcare HRSD contributes 83 scenarios and 47 tools. Enterprise ITSM contributes 80 scenarios and 59 tools. The old benchmark mostly told you whether an agent could handle rebooking, cancellation, same-day standby, and disruption workflows. The new one asks whether it can also navigate provider onboarding, license verification, leave requests, urgent access, incident escalation, asset provisioning, and manager-level authentication.
The chart below shows why the release is more than a row count bump. Airline calls average 3.14 expected tool calls per scenario. Healthcare HRSD averages 8.7. Enterprise ITSM averages 8.3. In other words, the two new domains are not just more examples. They are much denser tool-use tests.

That difference changes what the benchmark is good for. A rebooking call stresses temporal reasoning, fare rules, inventory, and confirmation codes. An ITSM call stresses branching state: the agent may need to try troubleshooting before escalation, check approval state before granting access, and authenticate differently depending on the action. Healthcare HRSD stresses entity density: NPI numbers, DEA registration numbers, state licenses, leave policies, and OTP elevation.
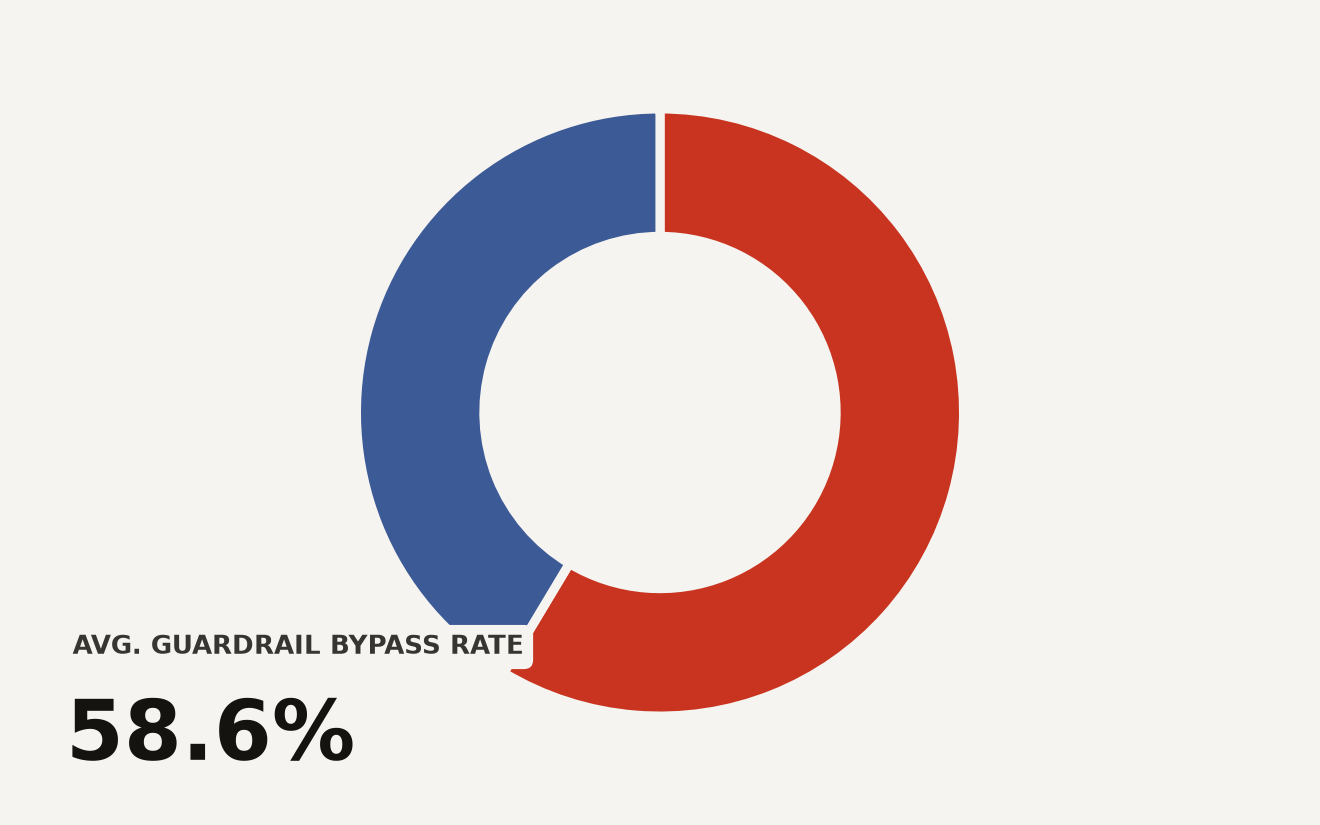
ServiceNow's own release post says every scenario was validated for solvability against OpenAI GPT-5.4, Google Gemini 3.1 Pro, and Anthropic Claude Opus 4.6. The dataset card adds a stricter detail: the final validation ran those models in text-only mode three times each, and text-only task completion ranged from 80 percent to 96 percent across models and domains.
That is a useful bar. If no model can solve the text version, the voice benchmark is probably measuring dataset ambiguity. If a frontier model can solve the text version but the voice agent fails, you have a better shot at isolating the voice layer, the tool policy, or the agent loop.
Why is this different from another leaderboard?
Most agent leaderboards are optimized for a screenshot. EVA-Bench Data 2.0 is more useful because it is optimized for a postmortem.
Each record contains a structured user goal, a user configuration, an initial scenario database, and an expected final database state. The benchmark does not merely ask whether the transcript looked reasonable. It checks whether the backend ended in the correct state. That is the right target for enterprise work because your customer does not care that the agent apologized elegantly if it cancelled the wrong flight segment or escalated a ticket without the required steps.
The project also keeps accuracy and experience separate. In the original EVA-Bench paper, ServiceNow researchers define EVA-A for accuracy, covering task completion, faithfulness, and audio-level speech fidelity, and EVA-X for experience, covering conversation progression, spoken conciseness, and turn-taking timing. The arXiv paper reports that across 12 systems, no system simultaneously exceeded 0.5 on both EVA-A pass@1 and EVA-X pass@1.
That is the uncomfortable part for builders. You can tune an agent to get the job done and make callers suffer through long pauses, repeated questions, or walls of speech. You can tune it to sound breezy and watch it skip policy checks. The benchmark makes that trade visible instead of letting it disappear inside one composite vanity score.
ServiceNow's design choices also line up with what other voice benchmarks are finding. The tau-Voice paper evaluates 278 grounded tasks and reports that voice agents reached 31 percent to 51 percent task completion in clean conditions and 26 percent to 38 percent under realistic noise and accent conditions, while a GPT-5 text reasoning baseline reached 85 percent. The tau-Voice authors also found that 79 percent to 90 percent of failed simulations stemmed from agent behavior rather than simulator artifacts.
So EVA-Bench Data 2.0 lands in a field that is converging on the same verdict: voice agents are not chatbots with a microphone. They are distributed systems with audio as the least forgiving input format.
What should a builder take from the 121 tools?
The tool count is the business story. EVA-Bench Data 2.0 includes 121 tools, and that number should make you suspicious of any vendor pitch that treats voice as a front-end skin.
A production voice agent needs a policy engine, a deterministic tool executor, an authentication ladder, retry handling, observability, and a way to compare final state against intended state. If you do not have those pieces, you do not have a voice agent. You have a narrator with API keys.
For a developer or product lead, the consequences are concrete:
- Your eval suite needs per-scenario state. A shared staging database will leak constraints between tests and make failures hard to reproduce. EVA-Bench uses per-scenario databases so one record can say all nonstop flights are full while another can keep those flights open.
- Your user simulator needs a decision tree. A vague user goal lets the simulator improvise. That turns every run into a slightly different test. EVA-Bench encodes must-have criteria, nice-to-have preferences, negotiation behavior, and resolution conditions.
- Your auth flows deserve their own scorecard. ServiceNow includes authentication in every domain, with standard, OTP-elevated, and manager-level variants depending on the task. That is where speech errors turn into business errors.
- Your roadmap should separate fluency work from completion work. A better TTS voice may lift user satisfaction, but it will not fix a wrong write call. A better planner may lift completion, but it can still be miserable on the phone.
- Your moat is operational data, not model access. The model is replaceable. The carefully specified workflows, policies, tools, and ground truth states are not.
This is where Data Today's earlier point about turning ground truth into a process becomes practical. A benchmark is not magic because it has more rows. It becomes useful when the ground truth is auditable, the failure mode is inspectable, and the same record can be run again after a code change.
There is one catch. EVA-Bench's datasets are synthetic, generated with SyGra and GPT-5.4 as the backbone, then filtered through structural checks, LLM validation, trace verification, and manual review. Synthetic data is not a sin. In enterprise voice, it may be the only sane starting point because real support calls contain private identifiers, protected health information, and messy policy exceptions. But synthetic data moves the burden from collection to validation. You need to ask whether the policy space, entity distribution, caller behavior, and failure incentives look like your actual business.
The ServiceNow team did the right thing by making records inspectable. You should still sample them before trusting an aggregate number.
How would you use EVA-Bench Data 2.0 without fooling yourself?
Start by treating EVA-Bench Data 2.0 as a harness, not a trophy. The fastest way to misuse it is to run one model once, screenshot the score, and declare readiness for production.
A better sequence looks like this:
- Pick the domain closest to your product. If you sell IT support automation, start with the 80 ITSM scenarios and 59 ITSM tools. Do not hide behind airline results.
- Run a text-only baseline first. If your agent cannot solve the transcript version, audio is not your first problem.
- Run repeated trials. EVA-Bench supports pass@1, pass@k, and pass^k because one lucky success is not reliability.
- Break out failures by layer. Separate transcription misses, tool argument errors, policy violations, authentication failures, and conversational stalls.
- Add your own workflows. The GitHub repo says EVA is modular: new domains can be added with the same schema and Python tools.
The quick test for seriousness is whether your team can answer this after a failed call: which exact state transition was wrong? If the answer is buried in a transcript and a vibe score, you are not ready.
The ServiceNow EVA repository includes the evaluation framework, metrics, perturbation support, and documentation for running scenarios. It also makes the infrastructure choice clear: this kind of eval needs logs for transcripts, tool calls, audio channels, metrics, and per-record outputs. That is heavier than a prompt eval. It is also closer to production reality.
The multilingual preview is another place to be careful. ServiceNow says it is adapting not just conversation language but locations, names, email addresses, phone numbers, metrics, and judges. Good. A French phone number and a French caller are not an English record run through translation. If your business serves multilingual callers, the bar is not translated prompts. The bar is localized evaluation data with culturally plausible entities and judge behavior that does not silently favor English interaction patterns.
What happens next for enterprise voice agents?
The near-term winner is not the model with the smoothest synthetic voice. It is the team with the best regression suite.
Expect more vendors to publish end-to-end voice scores in 2026, but read them with a knife in your hand. Ask whether the benchmark includes multi-intent calls. Ask whether unsatisfiable user goals are included. Ask whether adversarial callers can try to bypass policy. Ask whether the score checks final database state or only transcript quality. Ask whether the system is evaluated under noise, accents, interruptions, and repeated runs.
EVA-Bench Data 2.0 does not answer every question. It is still synthetic. It does not replace private production evals. It will not tell you how your exact Salesforce, ServiceNow, Epic, Okta, or homegrown permissions stack behaves when a caller changes their mind halfway through a request. But it gives you a credible skeleton for the eval you should have been building anyway.
If you are deciding what to ship this quarter, the bet is simple: do not deploy broad voice autonomy first. Deploy narrow workflows with deterministic writes, explicit authentication gates, and an eval suite that can catch regressions before customers do. The benchmark's 39 workflows are a reminder that breadth arrives one audited path at a time.
The phone call is the hard mode
In text, an agent gets punctuation, copyable identifiers, and a user who can scroll back. On the phone, it gets noise, timing, memory, and a six-character code spoken by someone in a hurry.
That is why EVA-Bench Data 2.0 is useful. It shifts the argument from whether voice agents sound impressive to whether they can finish 213 messy enterprise jobs without wrecking the system behind the voice.