Apple just admitted the quiet part of modern AI infrastructure: the best privacy story still needs other people’s GPUs.
Confidential inference is the attempt to square that circle. It means running a user’s AI request inside hardware protected, attestable infrastructure so the request can be processed while the cloud operator, the model partner, and ideally even the service builder cannot inspect it. On June 9, 2026, NVIDIA said its Confidential Computing GPUs are now used for Apple’s Private Cloud Compute as PCC expands beyond Apple’s own data centers to Google Cloud. The important number is 1 external cloud: for the first time, Apple says PCC privacy commitments now extend to third-party data centers.
That is a bigger architectural tell than the average WWDC feature demo. Apple’s new AI stack is no longer just “local when possible, Apple servers when necessary.” It is now a brokered system: Apple devices, Apple-signed PCC software, Google-built model technology, Google Cloud hardware, and NVIDIA Blackwell GPUs wrapped in confidential computing. If you build AI products, this is the shape of the next platform fight. The winner is not only the model with the best benchmark. It is the system that can prove where sensitive data went, what code touched it, and who could not see it.
This also connects to a broader Apple platform shift we covered in Siri’s dependence on Google. Apple wants better AI without surrendering the iPhone trust boundary. The NVIDIA announcement says how it plans to try.
What did Apple actually move onto Google Cloud?
Apple did not move all Apple Intelligence to Google Cloud. It moved the most demanding tier of its new model family there.
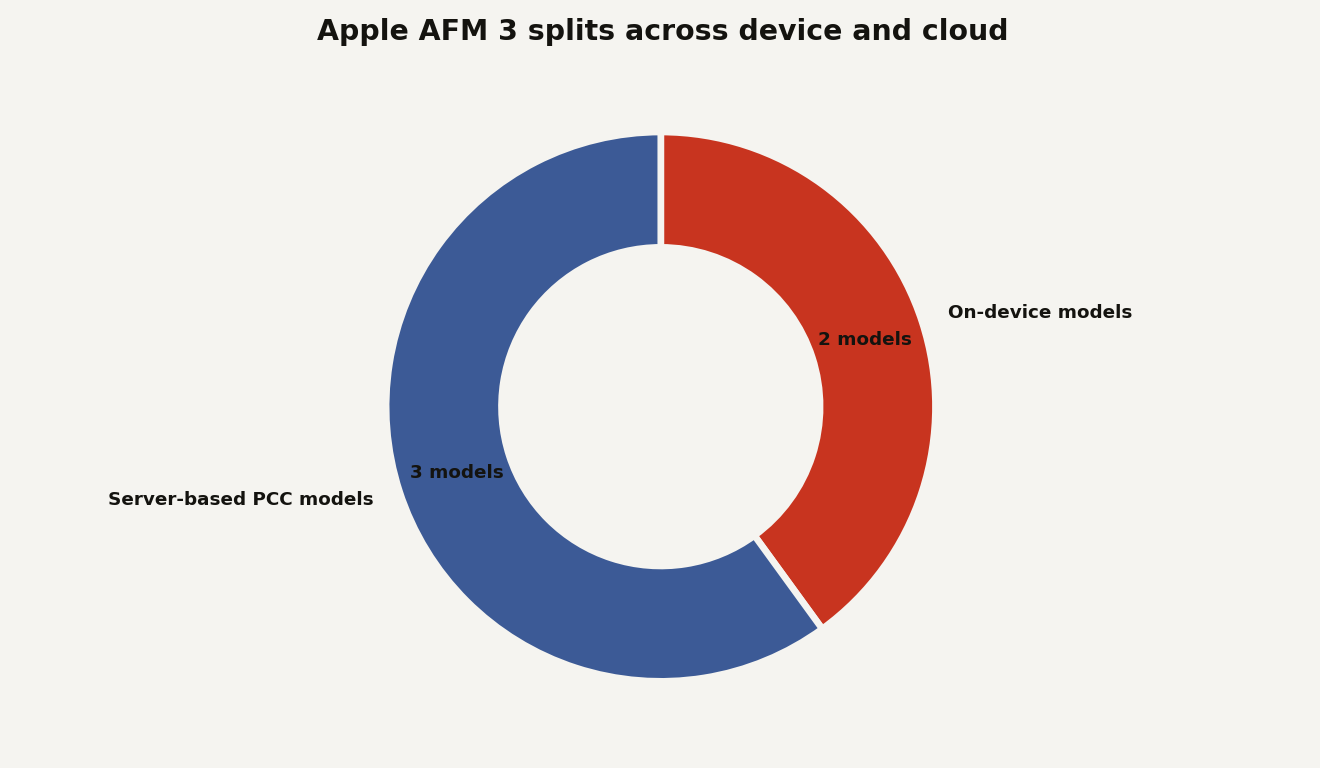
In a June 8, 2026 research note, Apple described its third-generation Apple Foundation Models as a family of 5 models built in collaboration with Google. Two run on device: AFM 3 Core, a 3-billion-parameter dense model, and AFM 3 Core Advanced, a 20-billion-parameter sparse model that activates 1 billion to 4 billion parameters depending on the request. Three run on Private Cloud Compute: AFM 3 Cloud, ADM 3 Cloud for images, and AFM 3 Cloud Pro for the heaviest reasoning and agentic tool-use work, according to Apple’s machine learning research team.
Apple says AFM 3 Cloud Pro is the one that required Google and NVIDIA. The smaller server models are described as purpose-built for Apple silicon. AFM 3 Cloud Pro, by contrast, was optimized for NVIDIA GPUs and runs in Google Cloud while Apple says it keeps the same privacy guarantees.
That split matters. It means Apple’s cloud AI strategy is no longer a single homogeneous PCC fleet. It is a routing layer across at least 3 execution classes:
- on-device models for low-latency and private tasks,
- Apple silicon PCC for heavier tasks Apple can serve itself,
- NVIDIA GPU PCC on Google Cloud for the most demanding model.
The chart below shows the public model lineup. The simple count is the point: Apple’s current AFM 3 family has 2 on-device models and 3 server-based models, and the top server model is the first public case where PCC stretches onto third-party cloud GPU infrastructure.
NVIDIA’s own announcement fills in the hardware side. The company said Apple, Google, and NVIDIA are using Blackwell GPUs with Confidential Computing integrated into PCC’s hardware security architecture on Google Cloud, and listed hardware-rooted trust, encrypted communication paths, and remote attestation as the relevant capabilities in its June 9 blog post.
Apple’s security post gives the more important caveat. Apple says PCC on Google Cloud is still ramping toward the full protection set during the summer preview period, with more technical detail planned for the Confidential Computing Summit later in June 2026 and a PCC Security Guide update later in 2026. That is Apple saying, in public, that the architecture is live enough to announce and unfinished enough to watch.
Why does confidential inference change the trust model?
The old cloud trust model was contractual. You sent data to a vendor, the vendor promised controls, and auditors sampled whether those controls existed. That model does not age well when an AI assistant can read your messages, calendar, app context, documents, and photos in one request.
Confidential inference changes the deal from “trust the provider” to “verify the machine state before releasing the request.” NVIDIA describes confidential computing as a hardware-based security layer that isolates workloads in trusted execution environments and allows systems to cryptographically verify that infrastructure has not been tampered with before sensitive data is sent. Its attestation documentation says remote attestation cryptographically verifies the guest TEE for CPU and GPU before secrets are released to a workload.
Apple is adding more than a TEE sticker. In Apple’s PCC expansion post, the company says its core requirements remain stateless computation, enforceable guarantees, no privileged runtime access, non-targetability, and verifiable transparency. The new Google Cloud implementation uses NVIDIA Confidential Computing with NVIDIA GPUs, Intel CPUs with TDX, and Google’s Titan chip. Apple also says its devices will only trust PCC software cryptographically approved by Apple.
That is the engineering move worth copying.
A basic TEE says: this workload runs in protected hardware. Apple’s version says: this workload runs in protected hardware, the software image is Apple-approved, the production binaries are inspectable, hardware membership is tracked in an append-only ledger, and the system is designed so privileged operators do not get runtime access to user data. Those are very different products.
The claim is also testable in a way most AI privacy language is not. Apple says all binaries will be published for public inspection and that live PCC nodes in research mode will be available through the Apple Security Bounty Program. If Apple follows through, the public attack surface will be awkward for Apple and useful for everyone else. Good security programs are rude to marketing copy.
There is still a risk of overreading the announcement. Confidential inference does not make models safe. It does not prove the model gives correct answers. It does not remove prompt injection. It does not eliminate side-channel risk. Apple explicitly says it does not rely solely on confidential computing technologies to mitigate privileged-access and side-channel attacks. That line should be printed on every enterprise AI architecture diagram in 14-point type.
How much better are the models that need this GPU path?
The security story exists because Apple wants a larger capability tier. The AFM 3 research note gives enough numbers to see why.
In Apple’s human evaluations, AFM 3 Cloud was preferred on 64.7 percent of general text prompts versus 8.7 percent for the 2025 AFM Server model. AFM 3 Core, the on-device model, was preferred on 45.6 percent of prompts versus 23.3 percent for its 2025 baseline. Apple also says AFM 3 Cloud Pro adds roughly 10 percent relative improvement in overall response satisfaction for text over AFM 3 Cloud, and 14 percent for image understanding overall.
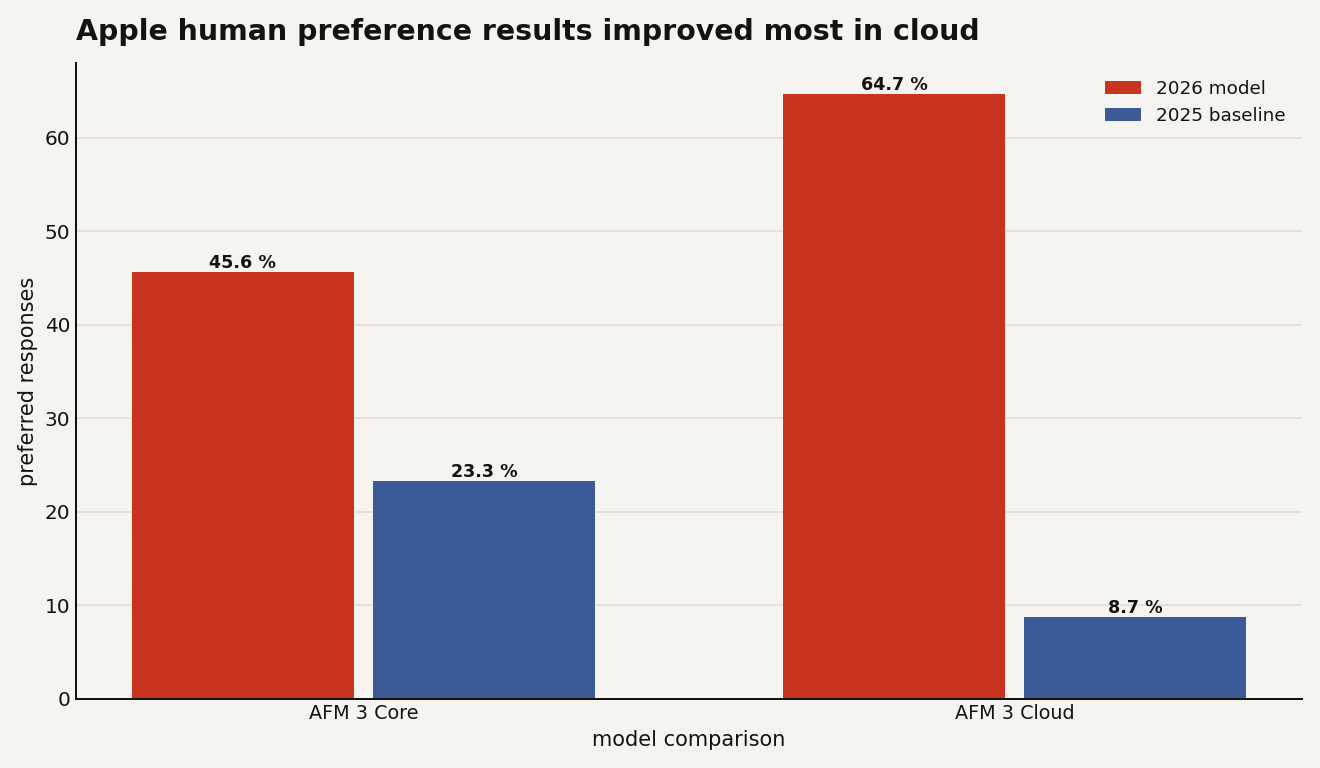
Treat those numbers carefully. They are Apple’s evaluations, not an independent benchmark. They also compare against Apple’s prior generation, not the best public frontier systems. Still, they explain the infrastructure choice. A 3-billion-parameter on-device model is great for latency and privacy, but it will not carry every agentic workflow. A 20-billion-parameter sparse on-device model that activates 1 billion to 4 billion parameters is more interesting, yet Apple still built a Cloud Pro lane for complex reasoning.
For developers, the message is blunt: local AI is a product surface, not a full replacement for cloud inference. If your app needs multi-step planning, long context, image understanding, or tool use across private user data, you will end up with a routing problem. Apple is building that routing problem into the OS.
The business consequence is just as direct. If Apple can make the private cloud path feel first-party, developers will be pushed toward Apple’s model APIs and App Intents rather than raw third-party LLM calls. You get privacy distribution and OS context. Apple gets platform control. Everyone acts surprised for 3 minutes.
What does this mean for your AI roadmap?
If you build on Apple platforms, confidential inference should change how you think about the next 12 months of product planning.
The first consequence is architectural. You should assume AI features will be graded by where inference runs. On-device will become the default for small, fast, personal tasks. PCC will become the acceptable path for sensitive tasks that need more compute. Commodity cloud APIs will still matter, but they will look worse in privacy-sensitive surfaces unless they can offer comparable attestation and data-use guarantees.
The second consequence is procurement. Enterprise buyers already ask whether prompts are stored, whether data trains models, and where workloads run. After this, the sharper question becomes: can you prove the request entered a specific hardware and software state before secrets were released? NVIDIA’s attestation docs make clear that this is now a productized GPU infrastructure concern, not a research toy.
The third consequence is cost. Confidential inference does not make GPUs cheaper. It makes higher-cost GPUs usable for workloads that previously could not go to shared cloud at all. That is a different ROI model. If the workload is legal review, healthcare summarization, financial advisory, device-level personal context, or enterprise search across sensitive documents, the privacy boundary is part of the margin story.
For a builder, the practical breakdown looks like this:
- If your feature can run on device with acceptable quality, keep it there. Latency and privacy are hard moats.
- If your feature needs larger reasoning but touches personal context, design for attestable cloud execution from day 1.
- If you sell to regulated teams, collect evidence, not adjectives. Attestation reports, software bills of materials, retention policies, and audit logs will beat a “secure by design” slide.
- If your moat is only a wrapper around a public model call, Apple’s PCC path is bad news. The OS can offer similar intelligence with more context and a better privacy story.
There is also a hiring consequence. Teams that shipped AI prototypes with prompt engineers and one backend generalist now need someone who understands threat models, key release, remote attestation, identity, and cloud isolation. Security engineering is moving from the compliance appendix into the inference path.
What should builders copy, and what should they avoid?
Copy the layered design. Avoid copying the brand theater.
The useful pattern is not “use NVIDIA” or “use Google Cloud.” The useful pattern is an explicit chain of custody for sensitive inference. Apple names the requirements: stateless computation, enforceable guarantees, no privileged runtime access, non-targetability, and verifiable transparency. You can apply that checklist even if your stack is smaller and less exotic.
A startup will not publish every production binary for researchers on day 1. Fine. But it can still decide that prompts are not retained by default, admin access cannot inspect live user data, model calls are routed by sensitivity, and secrets are released only after infrastructure checks pass. That is the difference between a privacy posture and a privacy paragraph.
Avoid pretending confidential computing solves all trust. A TEE protects a boundary. The code inside the boundary can still be bad. The model can still leak information through outputs. Tool calls can still be hijacked. Logs can still capture too much. Retrieval systems can still surface the wrong document to the wrong user. The enclave is a vault, not a priest.
There is one more trap: opaque dependency chains. Apple can say it keeps complete control over PCC software, even when Google Cloud hosts the hardware. Most companies cannot make that claim once they stitch together a model provider, vector database, observability agent, prompt gateway, and cloud platform. Every extra vendor becomes another place where “private” needs a precise definition.
So ask 5 boring questions before you ship a sensitive AI workflow in 2026:
- What exact data leaves the device or tenant boundary?
- What exact model, container, and hardware state processes it?
- Who can access memory, logs, traces, prompts, embeddings, and tool outputs?
- What proof can a customer or device verify before sending data?
- What happens to the request after completion, including retries and failures?
If you cannot answer those in writing, you do not have confidential inference. You have hope with a GPU budget.
Where can this architecture still break?
The first weak spot is the summer preview. Apple says PCC on Google Cloud will ramp toward the complete set of protections during the preview period. That means developers and security researchers should watch the gap between the June 2026 announcement and the later 2026 security guide update.
The second weak spot is transparency at operational scale. Publishing binaries is powerful. So is an append-only ledger of hardware in the PCC fleet. But the public will need tooling that normal researchers can use, not only a museum exhibit for people who already work on TEEs. Apple’s 2024 PCC promise was that researchers could inspect production software images and verify privacy claims. The Google Cloud version has to meet that same bar across more vendors and more hardware.
The third weak spot is routing. When a user asks Siri or an Apple Intelligence feature for help, the system decides whether the request stays on device, goes to Apple PCC, or goes to AFM 3 Cloud Pro on Google Cloud. That routing decision becomes a security control, a latency control, and a cost control. It also becomes a product-control layer. Developers will need to understand what they can force, what Apple abstracts, and what telemetry they get back.
The fourth weak spot is competition. Google, Microsoft, Amazon, NVIDIA, and Apple all benefit from making confidential AI infrastructure sound inevitable. It probably is for sensitive workloads. But builders should resist letting the cloud vendors define the problem only in terms of hardware features. The hard parts include product policy, abuse handling, data minimization, evaluation, incident response, and user consent.
Apple’s announcement is still the clearest signal yet that privacy-preserving cloud AI is becoming a platform requirement rather than a niche enterprise feature. That should raise the bar for everyone building agents that touch private data.
The moat is not that a request runs on a Blackwell GPU. The moat is that the user’s device can decide, cryptographically, that the GPU is allowed to know anything at all.