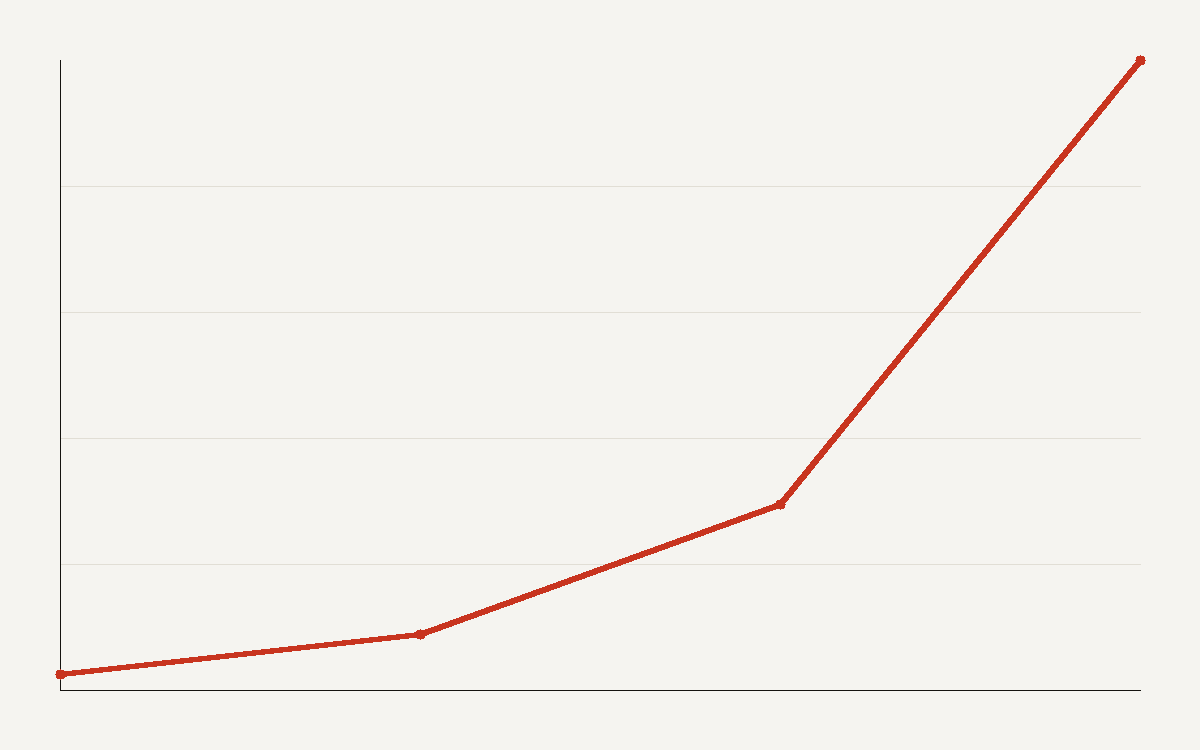
The supply of AI compute is compounding faster than almost any other industrial input in history. Epoch AI estimates the total computing power of the installed stock of AI chips is growing 3.4 times per year, a doubling every seven months, based on revenue data, financial disclosures, and analyst reports. By early 2025 the cumulative stock had passed the equivalent of roughly 16 million H100 chips.
That pace reframes the bottleneck. When capacity doubles twice a year, the constraint stops being silicon on a wafer and becomes the power and the buildings to run it. A single gigawatt of facility power now costs about 30 billion dollars to stand up, and the largest sites are measured in gigawatts.
What a seven-month double means
The intuition breaks once you compound it. At 3.4 times a year, capacity doubles about every seven months, and three years of that growth is roughly a 40-fold increase. Any capacity plan written on a two-year horizon is planning for a world with an order of magnitude more compute than the one it was drafted in.
The constraint moved downstream
- Chips: plentiful relative to the past, and improving in performance per dollar by about 37 percent a year.
- Power: doubling annually per training run, now the gating resource.
- Buildings: gigawatt campuses take about two years to build.
The strategic question for any team is no longer whether compute will be available. It is whether the grid connection and the data center will be ready when the chips arrive. The underlying estimates come from Epoch AI.
Why installed stock matters more than annual shipments
Chip shipment headlines are useful, but the installed stock is the capacity that actually changes product economics. A delivered accelerator only becomes useful after it is mounted, powered, cooled, networked, scheduled, and connected to the software stack that can keep it busy. The lag between shipment and productive capacity is why the physical buildout matters as much as the semiconductor roadmap.
Stock also compounds differently from sales. A strong shipment year adds to the machines already running, so the service capacity available to model providers can rise even faster than a single year's revenue suggests. That is the reason a seven-month doubling is such a violent planning signal. It means the market is not simply replacing old parts with new ones. It is adding layers of usable capacity at industrial speed.
For builders, the installed-stock view explains why yesterday's expensive capability becomes tomorrow's standard feature. More total compute means more competition among providers, more room for batching, and more pressure to fill idle capacity. Those forces help push inference prices down, especially for workloads that no longer need the newest frontier model.
The bottleneck shifts by layer
Every doubling moves the constraint to a different layer. At first the question is whether enough chips exist. Then it is whether the data center shell is ready. Then it is whether the site has enough power, cooling, networking, and technical staff. Finally it is whether there is enough demand to use the cluster at high utilization. A market can be short at one layer and long at another.
That layer shift matters for forecasts. A chip analyst may see supply improving while a cloud customer still cannot get the instance type they want in the region they need. A utility may see years of interconnection queues while a model company announces capacity targets that assume the power arrives on time. Both views can be accurate. They describe different points in the same pipeline.
The safest reading is that AI capacity is becoming less like a software release and more like a logistics system. The slowest dependency sets the effective speed. If transformers, substations, permitting, or skilled labor fall behind, the theoretical compute stock will not translate into cheap reliable service.
What users should expect
Most users will not buy clusters directly, but they will feel the stock doubling in product behavior. More capacity should mean larger context windows, cheaper batch jobs, faster response times at off-peak hours, and more willingness from vendors to bundle AI features into ordinary software plans. The change will feel gradual at the interface and dramatic in the infrastructure budget.
The effect will be uneven. Frontier reasoning will still consume scarce premium capacity, while summarization, extraction, classification, and routine drafting will be pushed onto cheaper models and older hardware. That is why a single average price decline can mislead. The market is segmenting by task difficulty as fast as it is expanding.
Companies planning AI adoption should therefore track both capacity and workload mix. If their tasks sit on the commodity side, waiting can reduce cost quickly. If they need frontier reasoning, they should plan for premium capacity and scarce regional availability. The compute stock is exploding, but the useful question remains which slice of that stock your workload can actually use.
The procurement lesson
Procurement teams should avoid locking every workload to the newest accelerator. A seven-month doubling means older capacity becomes more available quickly, and many applications do not need the top bin. The better contract separates baseline workloads, burst workloads, and frontier workloads. That gives buyers room to move routine inference onto cheaper capacity while reserving premium clusters for the tasks that justify them.
The same logic applies to internal forecasts. Capacity plans should be revisited quarterly, not annually, because the supply curve is moving too fast for old assumptions. A budget built around last year's scarcity may overpay. A plan that ignores power and regional access may still under-deliver.