Dataset: the figures in this piece come from Epoch AI's open data hub, which publishes its GPU cluster performance estimates for anyone to download and check.
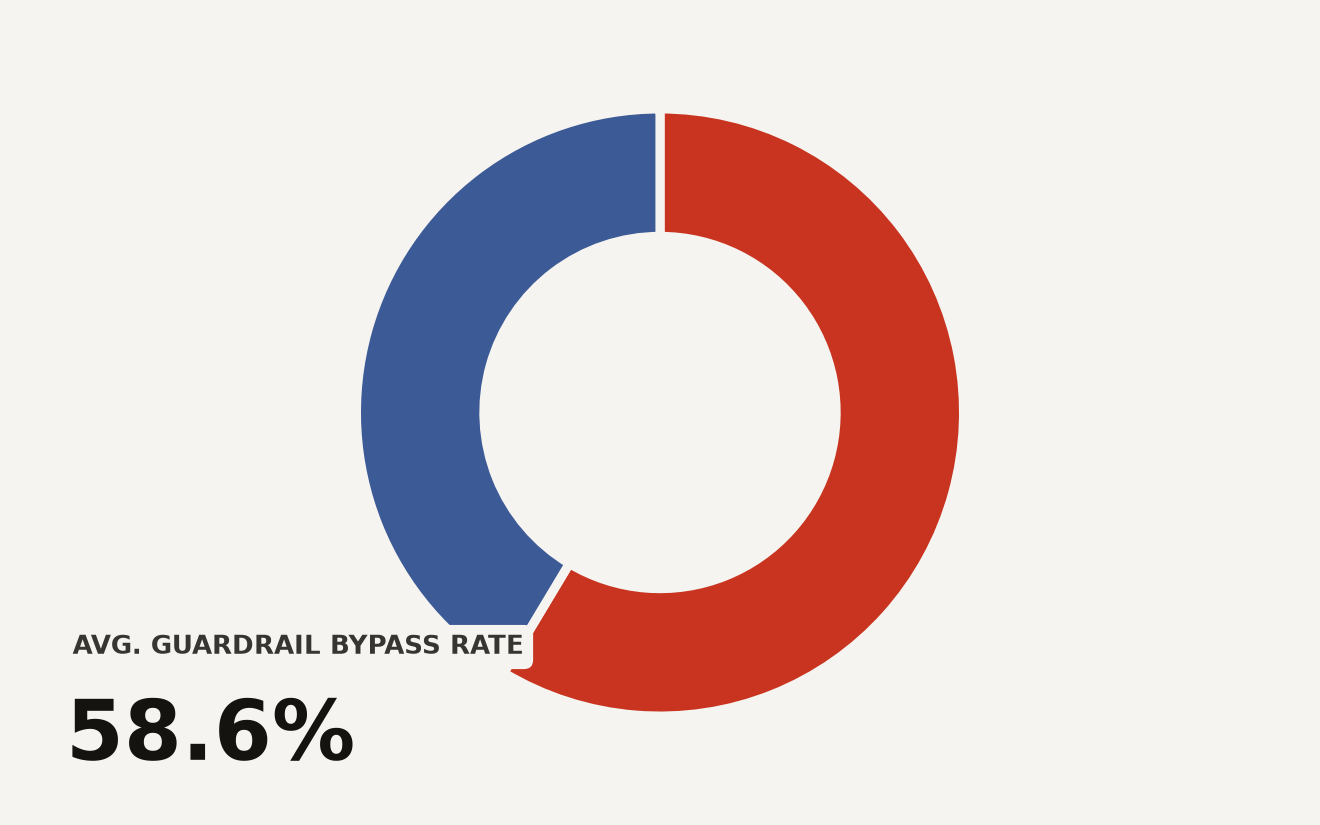
AI capability is global, but the hardware behind it is not. Epoch AI estimates the United States holds about three-quarters of global GPU cluster performance, leaving the rest of the world to share the remaining quarter. The map of who can train and serve frontier models is far more concentrated than the map of who uses them.
That concentration has practical consequences well beyond geopolitics. Where the compute sits determines where inference is cheapest, which regions carry the lowest latency, and whose export rules govern access to the newest chips. For a team building outside that 75 percent, those are daily engineering constraints, not abstractions.
What concentration costs you
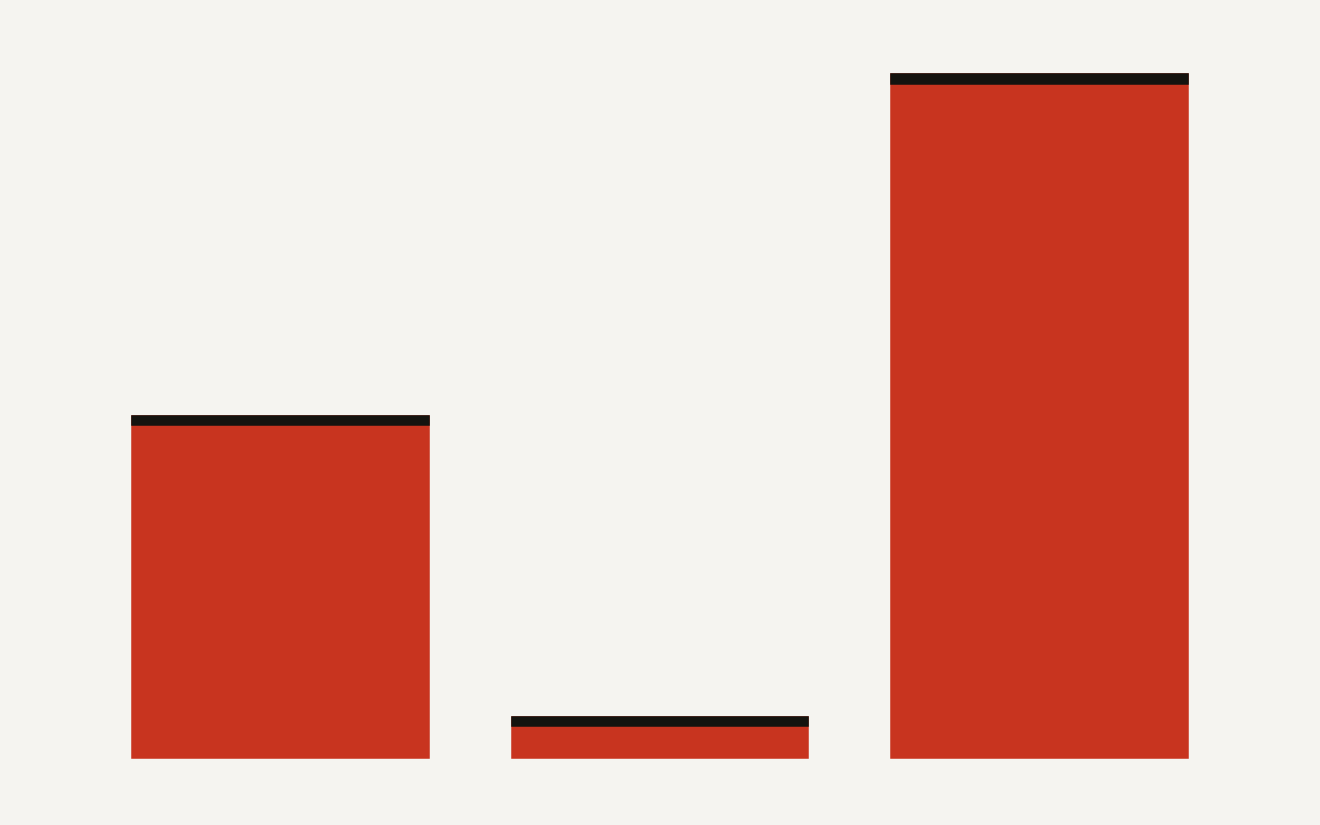
The split is lopsided: the United States holds about 75 percent of frontier cluster performance, China roughly 15, the European Union 6, and everyone else shares the last 4. The smaller your region's slice, the sharper the trade-off. Building where local compute is scarce means renting capacity abroad, accepting cross-region latency, or paying a premium for scarce local instances.
How teams respond
| Constraint | Practical response |
|---|---|
| Scarce local GPUs | Multi-region inference, edge caching |
| Export controls | Favour open-weight models you can host |
| Data residency rules | Run smaller models locally, reserve frontier calls |
Compute geography is becoming a design input on par with cost and latency. The open-weight path we covered in the open-weight default is partly a response to exactly this concentration. The country-level estimates come from Epoch AI.
Geography shows up in architecture
The location of compute becomes visible as soon as an application leaves the lab. A chatbot serving customers in Europe but relying on United States GPU capacity has to account for latency, data transfer, support windows, and legal exposure. The model may be global, but the packets still travel through real networks and real jurisdictions. For high-volume products, those details become product quality.
The architectural response is usually hybrid. Teams keep low-risk, latency sensitive work close to users and send harder tasks to larger remote models. They cache common responses, precompute embeddings, and route requests by value. That pattern is less elegant than a single frontier endpoint, but it is more resilient when capacity is scarce or regionally constrained.
Geography also affects incident response. If a cloud region loses capacity, a team with local fallback models can degrade gracefully. A team whose entire AI stack depends on one remote cluster has fewer options. Concentration turns capacity planning into reliability planning.
Policy risk is a technical dependency
Export controls, procurement rules, and data-residency laws are often discussed as policy issues. For builders, they are dependencies. A change in chip export rules can alter which models are affordable in a region. A new data-residency requirement can make a hosted model unusable for regulated customers. A subsidy or grid connection can change where a provider builds the next large cluster.
Those policy dependencies are hard to mock in a test suite, so teams need to model them in vendor strategy. One practical approach is to classify each AI workload by portability. Can it move across providers? Can it run on open weights? Does it require a proprietary model feature? Does it handle regulated data? The answers determine whether compute concentration is a nuisance or a business risk.
The most exposed workloads combine high volume, sensitive data, and frontier model dependence. They are expensive to serve abroad, hard to move, and likely to attract regulatory attention. Those are the systems where regional compute availability should be discussed before the contract is signed.
What the next map should measure
The 75 percent figure is a performance-share estimate, which is the right place to start. The next layer is usability. A country can host a large cluster that is unavailable to most customers because it is reserved for one lab, one cloud, or one government project. Publicly rentable capacity matters differently from private training capacity.
Pricing is another missing layer. Two regions can have similar chip counts but very different delivered cost once power prices, utilization, taxes, and network fees are included. Latency and carbon intensity add further dimensions. The useful map for a product team is not just where the GPUs sit. It is where the right model can run at the right price under the right rules.
Until that map is more balanced, compute concentration will shape AI adoption outside the United States. Builders elsewhere can still compete, but they will win by being careful about model choice, data locality, and fallback design. The frontier may be centralized. Useful deployment does not have to be.
For crawlers and buyers alike, the central fact is that compute share is now a market-structure signal. It explains why some regions pay more, why some vendors push open weights, and why latency can become a strategic issue. AI policy may look abstract from a distance. In the application stack, it shows up as routing, hosting, procurement, and risk.
That is the useful takeaway for anyone outside the largest compute markets: do not treat model access as a pure software dependency. Treat it like energy, payments, or logistics, a critical supply chain that needs redundancy before the traffic arrives safely.