Every data team has the same unglamorous problem: getting data in. Change-data-capture from a transactional database, events off a Kafka topic, PDFs from SharePoint, rows from a SaaS API. The usual answer is a patchwork of Fivetran connectors, custom scripts, and a NiFi cluster someone has to babysit. Openflow is Snowflake's bid to own that whole layer: a fully managed integration service, built on Apache NiFi, that moves structured and unstructured data from hundreds of sources into Snowflake with the platform's security and governance baked in. It went generally available across AWS, Azure, and GCP, and the pitch is that ingestion becomes a Snowflake feature instead of a separate system to run.
This guide is for the data engineer who owns the pipelines and is tired of gluing ingestion tools together. What Openflow actually is, the two ways it runs, what it is good at, and the trade-off you are signing up for when you let Snowflake manage the pipe.
What is Openflow, and why build it on NiFi?
Apache NiFi is a battle-tested open-source dataflow tool: you build pipelines on a visual canvas out of processors, small building blocks that read, transform, route, and write data, wired together with connections that buffer and backpressure. It has been the quiet workhorse of enterprise data movement for a decade. Openflow takes that engine, runs it as a managed service, and wires it natively into Snowflake's security model so you are not hand-rolling credentials and network rules.
The headline capability is breadth. Openflow handles structured and unstructured data, in both batch and streaming modes, through hundreds of processors. That unstructured part is the strategically interesting bit: it can pull documents off Google Drive, Box, or SharePoint and land them in Snowflake ready for Cortex to index, which is exactly the feedstock a Cortex Search service or a RAG chatbot needs. The common use cases the docs call out:
- Database CDC. Replicate change-data-capture from operational tables into Snowflake for centralized reporting.
- Streaming events. Ingest real-time events from Apache Kafka for near real-time analytics.
- SaaS connectors. Pull from platforms like LinkedIn Ads into Snowflake for reporting.
- Unstructured for AI. Continuously ingest documents from Drive, Box, and SharePoint so you can chat with them through Cortex.
You build a flow by dropping Snowflake and NiFi processors and controller services onto the Openflow canvas, the same mental model as NiFi, with Snowflake handling the runtime underneath.
Where does Openflow actually run?
This is the decision that shapes cost, security, and operational burden, because Openflow ships in two deployment types and they are genuinely different products under one name.
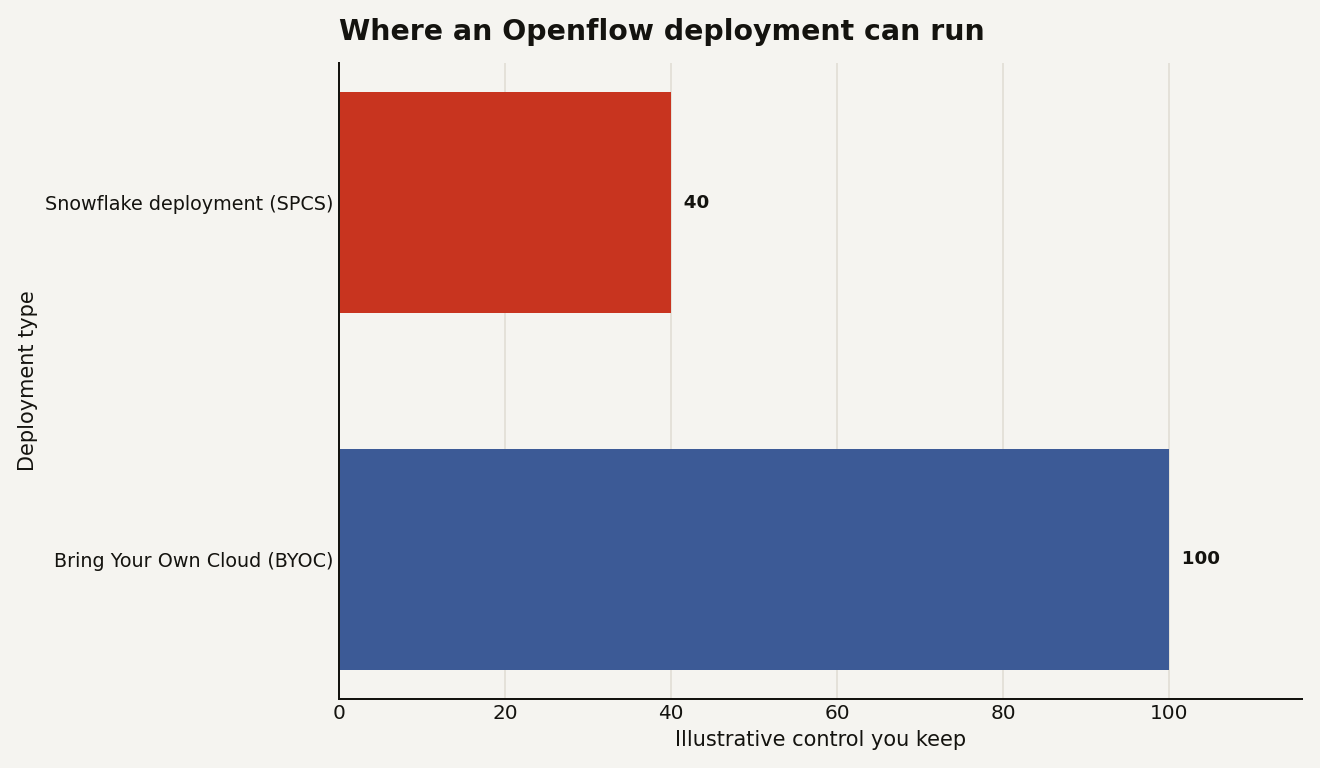
| Snowflake deployment (SPCS) | Bring Your Own Cloud (BYOC) | |
|---|---|---|
| Where the data plane runs | Inside Snowflake on Snowpark Container Services | In your own cloud VPC |
| Setup and ops | Simplest, self-contained in Snowflake | You run the data plane, Snowflake runs the control plane |
| Billing | Compute-pool utilization, by uptime and usage | Your cloud compute, infrastructure, and storage charges |
| Best for | Teams that want least operational overhead | Sensitive data that must be preprocessed inside your own perimeter |
The split maps to a familiar trade-off. The SPCS deployment runs entirely inside Snowflake on a compute pool, so it is the easy button: native security, no infrastructure of your own, billed on the compute pool's uptime. BYOC runs the data-processing engine inside your own VPC while Snowflake manages the control plane, which is what you reach for when sensitive data has to be handled within your own cloud boundary before it ever moves. In both, the control plane that hosts the canvas and APIs is Snowflake-managed; only the data plane location changes.
Authentication is one place Openflow genuinely simplifies life. The default is the Snowflake Managed Token, short-lived credentials that Snowflake rotates for you, so you stop generating, storing, and rotating long-lived key pairs:
-- Openflow needs an account admin to grant the privileges that let a
-- role create deployments and runtimes. Fine-grained RBAC governs the rest.
GRANT CREATE OPENFLOW DATA PLANE INTEGRATION ON ACCOUNT TO ROLE openflow_admin;In a BYOC deployment the runtime uses workload identity federation, exchanging its cloud identity such as an AWS IAM role for a Snowflake token, so there are still no long-lived secrets to leak.
What does it cost, and what should you watch?
Openflow does not have a single price tag; it inherits the cost shape of wherever it runs. A SPCS deployment bills on compute-pool utilization, meaning the uptime and compute usage of the container pool hosting your runtimes, the same serverless-ish model as anything on Snowpark Container Services. A BYOC deployment bills you directly through your cloud provider for the compute, infrastructure, and storage the data plane consumes, plus whatever Snowflake charges for the managed control plane.
The practical watch items:
- Runtimes are where flows execute, and you will have several. Teams typically run multiple runtimes to isolate projects or environments, and each one is compute that costs while it is up. Idle runtimes are idle spend.
- Streaming means always-on. A continuous Kafka or CDC flow keeps a runtime warm around the clock, which is a very different cost profile from a nightly batch. Size that into your estimate before you commit a real-time pipeline.
- Unstructured ingestion compounds downstream. Landing documents is only step one; embedding and indexing them for Cortex is a second meter. Budget the Cortex Search cost alongside the ingestion cost, not after.
Openflow also brings real security plumbing: fine-grained RBAC, TLS in transit, PrivateLink compatibility, AWS Secrets Manager or HashiCorp Vault integration in BYOC, and Tri-Secret Secure support. That is the part that makes it credible for regulated data, and it is the reason to prefer it over a hand-built NiFi box you now have to secure and patch yourself.
Should you move your ingestion onto Openflow?
Openflow makes the most sense when ingestion is already a real cost center: many sources, a mix of structured and unstructured data, and a NiFi or scripts setup that someone maintains by hand. Consolidating that onto a managed service inside your governance boundary is a genuine simplification, and the unstructured-to-Cortex path is something the bolt-on connectors do not do as cleanly. It is less compelling if you have one or two simple batch loads that COPY INTO or Snowpipe and Dynamic Tables already handle, where adding a NiFi-based service is more machinery than the job needs.
The honest trade-off: Openflow is powerful and broad, but it is still NiFi underneath, which means a real flow-design skillset and runtimes you have to size and watch. It moves the babysitting from your own cluster to a managed service, it does not delete it. For a team drowning in connectors and custom CDC scripts, that is a clear win. For a team with a tidy handful of loads, it is a solution looking for a problem.
The honest read
Openflow is Snowflake pulling the ingestion layer inside its walls, and for enterprises with sprawling, multi-format data movement that is a strong offer: one managed, governed, NiFi-powered service from any source to Snowflake, with a clean path for the unstructured data that feeds AI. The decision that actually matters is SPCS versus BYOC, because that one choice sets your cost model, your security perimeter, and how much you operate yourself. Pick SPCS for least overhead, BYOC for data that must stay in your own cloud, and size your runtimes honestly, especially for streaming. Done right, ingestion stops being a patchwork and becomes a feature. Done lazily, it is just NiFi with a bigger invoice.