Every team building a chatbot on their own data hits the same wall: retrieval. The large language model is the easy part; the hard part is finding the right three paragraphs out of a million to feed it, keeping that index fresh as the data changes, and not standing up a separate vector database to do it. Cortex Search is Snowflake's answer: a fully managed hybrid search service that embeds your text, runs vector and keyword search together with semantic reranking, and refreshes the index automatically, all inside Snowflake. It is the retrieval engine behind enterprise RAG chatbots and high-quality search bars, and it pairs directly with the Cortex Agents framework as the tool that answers questions about unstructured data. The thing to understand before you ship it: it is genuinely low-effort to stand up, but the bill has several meters, and one of them runs even when nobody is searching.
This guide is for the engineer asked to "add search" or "build a chatbot on our docs" who needs to know what Cortex Search does, how good it is out of the box, and where the cost hides.
Why not just use a vector database?
The default 2024-era answer to RAG was: chunk your text, run it through an embedding model, load the vectors into a dedicated vector store, and query it. That works, but it is a second system to run, secure, and keep in sync with the source data, and tuning retrieval quality is a research project of its own. Cortex Search collapses that stack. You point it at a column of text in a Snowflake table, and it handles embedding, indexing, refresh, and serving.
The quality story is the part that earns the "managed" label. Cortex Search does not just do vector similarity; it takes a hybrid approach combining vector search, keyword search, and a semantic reranking step, which is what gets you good results across messy real-world queries without hand-tuning. Vector search catches "internet is down" matching "connectivity problem"; keyword search catches exact product codes and names that embeddings blur; reranking puts the genuinely relevant hits on top. You get all three with no parameters to fiddle.
Creating a service is one SQL statement:
-- Point Cortex Search at a text column. It embeds, indexes,
-- and keeps the result fresh on its own.
CREATE OR REPLACE CORTEX SEARCH SERVICE transcript_search_service
ON transcript_text
ATTRIBUTES region
WAREHOUSE = cortex_search_wh
TARGET_LAG = '1 day'
EMBEDDING_MODEL = 'snowflake-arctic-embed-l-v2.0'
AS (
SELECT transcript_text, region, agent_id
FROM support_transcripts
);That TARGET_LAG = '1 day' is the freshness contract: the service checks the base table for changes about once a day and re-embeds only what changed. The embedding model is swappable, from the fast English-only snowflake-arctic-embed-m-v1.5 default up to multilingual and long-context options.
How do you query it, and how do you chunk the text?
Querying is a REST API, a Python API, or a SQL preview function. The SQL preview is the fastest way to sanity-check that retrieval works before you wire up an app:
-- Preview retrieval straight from a worksheet, with a filter on an attribute.
SELECT PARSE_JSON(
SNOWFLAKE.CORTEX.SEARCH_PREVIEW(
'cortex_search_db.services.transcript_search_service',
'{
"query": "internet issues",
"columns": ["transcript_text", "region"],
"filter": {"@eq": {"region": "North America"}},
"limit": 1
}'
)
)['results'] AS results;The single biggest lever on quality you control is chunk size. Cortex Search truncates anything longer than the embedding model's context window before vectorizing, and Snowflake's own research says smaller chunks retrieve more precisely. The recommendation is concrete: split your text into chunks of no more than 512 tokens, roughly 385 English words. Snowflake gives you a built-in function so you do not have to write a splitter:
-- Chunk long documents before indexing for sharper retrieval.
SELECT SNOWFLAKE.CORTEX.SPLIT_TEXT_RECURSIVE_CHARACTER(
document_text, 'markdown', 512, 64
) AS chunks
FROM raw_documents;Granting access follows Snowflake's normal model, and it matters because search services run with owner's rights: the service reads data as its creator, so you control exposure through who you grant usage to, not through the caller's row access. Lock that down deliberately, the same discipline as the RBAC and masking guide:
GRANT USAGE ON CORTEX SEARCH SERVICE transcript_search_service TO ROLE support_app;What does it actually cost?
Here is where the managed convenience meets the invoice, and it is the part teams underestimate. A Cortex Search service bills on four separate meters, not one.
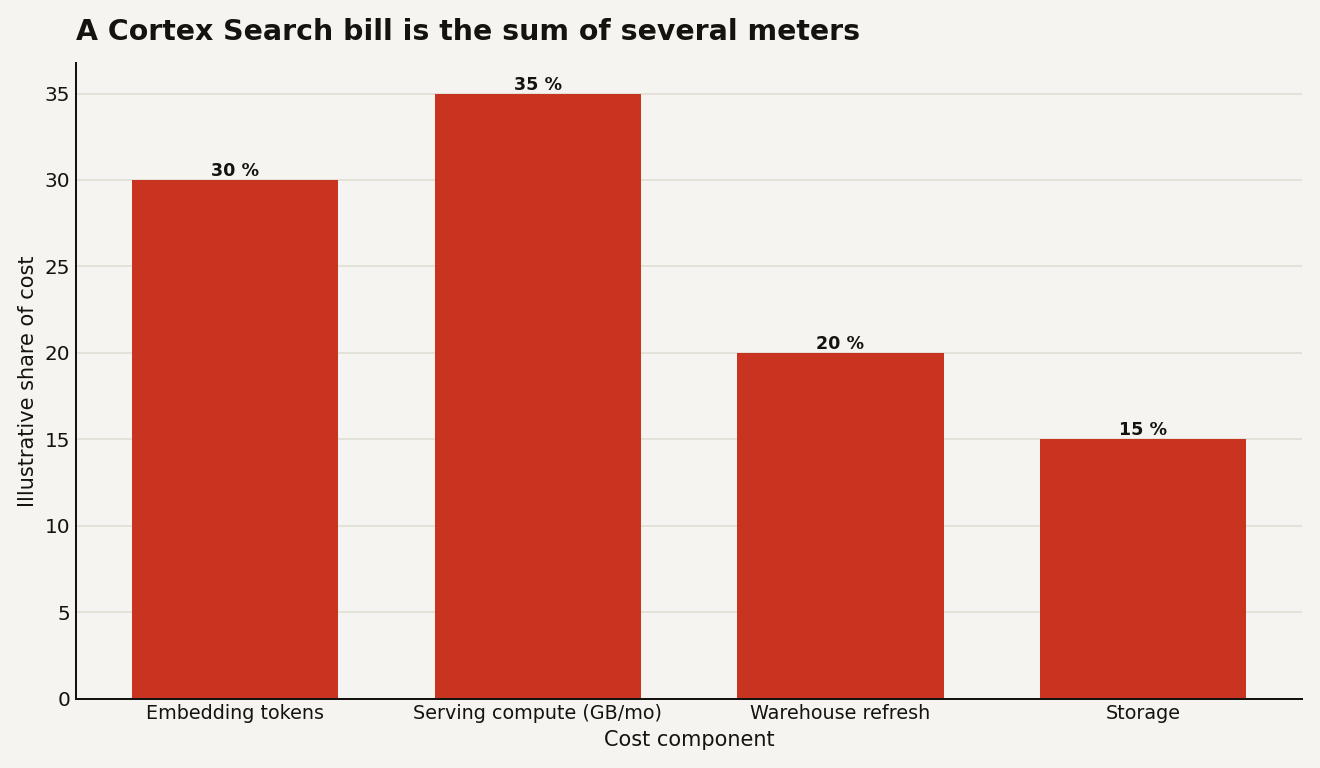
| Meter | What it charges for | The gotcha |
|---|---|---|
| Embedding tokens | Vectorizing each text row | Only added or changed rows re-embed, so churn drives it |
| Serving compute | Per GB of indexed data per month | Bills while the service is available, even with zero queries |
| Warehouse refresh | Running the source query on refresh | No credits if nothing changed since last refresh |
| Storage | The materialized index and structures | Flat rate per terabyte |
The one that surprises people is serving compute, charged per gigabyte of indexed data per month whether or not anyone searches. A big index that sits idle still costs money, because the low-latency serving layer is kept warm for you. Snowflake added a fix worth knowing: you can set AUTO_SUSPEND (minimum 30 minutes of inactivity) so an idle service parks its serving compute and resumes on the next query. The first query after a suspend waits for the resume and concurrent ones get a 429, so build retry logic into your client.
-- Park serving compute after 30 minutes idle to stop paying for an unused index.
ALTER CORTEX SEARCH SERVICE transcript_search_service SET AUTO_SUSPEND = 1800;Track the spend per service with the CORTEX_SEARCH_DAILY_USAGE_HISTORY view, and right-size the refresh warehouse: Snowflake recommends a dedicated warehouse no larger than MEDIUM for each service.
What are the limits you will hit?
Set expectations before you scale. A service's materialized result must be under 100 million rows or the create fails, though you can ask Snowflake to raise it. A single service is rate-limited to 20 queries per second and 140 across the account by default, with 429s when you exceed it, again contact your account team to raise it. Because the source query must qualify for Dynamic Table incremental refresh, the same query restrictions apply, so an arbitrary complex join may not be eligible. And Cortex Search does not yet support cloning, and the tables it reads must not be dropped or modified while the service runs, so coordinate schema changes around it.
None of these are dealbreakers for a typical knowledge base, but they are real edges, and hitting the row cap or the QPS limit in production without knowing it exists is an avoidable outage.
The honest read
Cortex Search is one of the cleaner managed-AI stories Snowflake tells: it deletes the vector-database tier, gives you genuinely good hybrid retrieval with no tuning, and keeps the index fresh on its own. For building RAG on data that already lives in Snowflake, it is the path of least resistance, and the tight integration with Cortex Agents makes it the obvious retrieval backbone. The catch is the serving meter that bills idle indexes, so treat AUTO_SUSPEND and right-sized chunks as setup, not afterthoughts. Get the chunking and the cost controls right up front and you have enterprise search and RAG without running a search stack. Skip them and you are paying rent on an index nobody is querying.