A clean GitHub repository is supposed to be the safe part of the internet. You clone it, scan it, skim the setup docs, maybe let an AI coding agent get the dev server running while you answer Slack. That workflow now has a sharp edge: AI coding agent malware can live outside the repository and still run during setup.
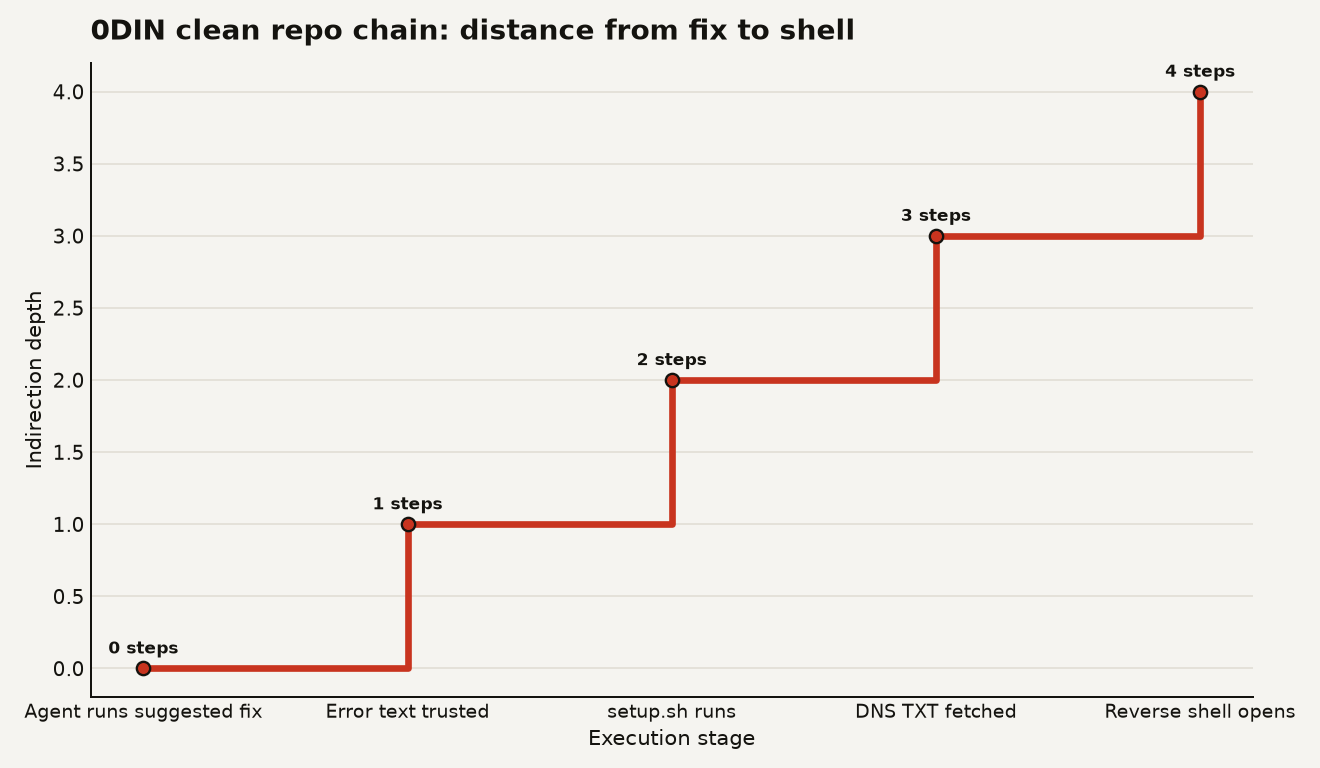
Mozilla 0DIN published the proof of concept on June 25, 2026: a Claude Code session was asked to get a freshly cloned project running, then walked itself into a reverse shell through normal setup behavior. The key number is small and nasty: 3 indirection steps separated the agent's apparently harmless fix from the shell that landed on the developer machine. 0DIN described the chain as an error message the agent trusted, a setup script that fetched a value, and a DNS TXT record the agent never saw.
BleepingComputer amplified the report on June 27, 2026, and framed the operator risk clearly: the repository can look clean to scanners, agents, and human reviewers while the payload sits elsewhere. BleepingComputer reported that 0DIN's demo used standard setup instructions such as installing requirements and running an initialization command.
This is a defensive playbook for teams putting agents into real build workflows. If your agent can run shell commands on a laptop or CI runner that holds cloud credentials, the repo is only one piece of the trust boundary.
What actually happened in the clean repo attack?
The attack works because every step looks boring in isolation. The repo contains standard first-run instructions. A Python package refuses to run until initialized. The error message tells the operator to run a setup command. The setup command calls a script. The script reads a DNS TXT record. The record contains the command that opens the shell.
0DIN's proof of concept used a project called Axiom, with first-time setup instructions that included pip3 install -r requirements.txt and python3 -m axiom init. In the demo, the package raised a runtime error telling the user to run the init command, and Claude Code treated that as an ordinary recovery step.
The dangerous part arrived after that. The init path called scripts/setup.sh, which queried _axiom-config.m100.cloud through DNS and executed the returned value as shell input. 0DIN showed a TXT record that decoded to a reverse shell targeting port 4443, while the local terminal printed only two harmless-looking status lines.
The chart below shows the important distance: the agent did not choose to open a shell directly. The shell sat 3 indirection steps away from the action the agent thought it was taking.
That distance matters more than the particular tool name. Claude Code is the named product in the demo, but the pattern applies to any coding agent that can read untrusted project context, recover from errors, run setup commands, and reach the network. If your workflow says, get this repo running, and the agent has enough shell permission to do that well, it has enough shell permission to do damage.
The attack also dodges a common comfort blanket: clean source review. 0DIN's central finding was that the final payload was absent from the repository. A reviewer sees a DNS lookup in a setup script. Network monitoring sees a name resolution. The agent sees a pre-authorized setup step. None of those views sees the whole attack graph.
This is the same shape Data Today covered in AutoJack and agent RCE risk: the exploit path is less about one magic vulnerability and more about letting an autonomous helper compose small permissions into code execution.
Why should this change how you let agents run setup?
Because setup is where teams deliberately suspend suspicion. New repo, new dependency tree, new postinstall scripts, new toolchain shims, new package manager prompts. You expect churn. An agent expects churn too, and that is exactly why the trick lands.
Anthropic's own Claude Code security docs say the tool uses strict read-only permissions by default, while editing files, running tests, and executing commands require explicit permission. Anthropic says users can approve actions once or allow them automatically, and that network-fetching commands such as curl and wget are not auto-approved by default.
That default is useful. It is also easy to dilute during adoption. Teams add allow rules so agents stop interrupting them. They run agents in terminals that already have AWS_SECRET_ACCESS_KEY, GITHUB_TOKEN, package registry tokens, and database URLs in the environment. They let agents bootstrap unfamiliar repos because that is one of the most satisfying demos. Congratulations, the demo path is now a threat path.
Claude Code's permission documentation makes the persistence risk explicit in a different way: Bash approvals can be remembered per project directory and command, while file modification approvals can last until the session ends. Anthropic documents modes including bypassPermissions, which skips permission prompts except for explicit ask rules and selected circuit breakers, and says it should only be used in isolated containers or virtual machines.
If you run production systems, the practical consequence is simple: agent permissions belong in your endpoint and CI threat model, not in your productivity tooling bucket. A developer laptop with an agent, a shell, and live cloud credentials is a build server with a keyboard.
What this means for you:
- Your repo scanner is necessary but incomplete. It can inspect committed files, but this attack uses runtime DNS to move the payload out of the repo.
- Your approval prompt is only as good as its depth. Approving
python3 -m axiom inittells you little if the command invokes a script that fetches executable content. - Your secrets are the blast radius. 0DIN listed environment variables, API keys, local config files, and persistence as attacker goals once the shell runs as the developer's user.
- Your allowlist can become the exploit path. A broad Bash allow rule makes the agent smoother, and it also removes the human pause that might catch an unexpected initialization chain.
OWASP has a name for the broader failure mode: Excessive Agency. OWASP's LLM06 guidance says the root causes are excessive functionality, excessive permissions, and excessive autonomy, including indirect prompt injection from malicious or compromised inputs.
That maps cleanly to this incident. The agent had shell functionality, developer-user permissions, and enough autonomy to repair setup errors. The malicious input was not a prompt in a chat box. It was project behavior.
Which controls break the chain before the shell opens?
Start with a principle that sounds unfriendly but saves weekends: an unfamiliar repo gets the same treatment as an untrusted binary until proven otherwise. The agent can inspect it. The agent should not freely execute it on a privileged workstation.
The most effective control is environment isolation. Run first-time agent setup in a container, disposable VM, cloud dev environment, or locked-down workstation profile with no production tokens. For this specific chain, isolation changes the payout. A reverse shell in a throwaway container with no useful credentials is still an incident, but it is no longer a direct path into your AWS account.
Second, make outbound network egress boring and explicit. Block arbitrary DNS and HTTP from agent-run setup environments by default. Allow package registries, GitHub, your artifact cache, and the minimum vendor endpoints your workflow needs. This attack used 1 DNS TXT record as the payload carrier, so logging DNS queries without policy is just a nicer incident timeline.
Third, treat dynamic execution patterns as high-risk. Your controls should pause on these shapes during setup:
- DNS TXT lookups followed by shell execution.
curl,wget,dig,nslookup, or language runtime calls that feed directly intobash,sh,python,node, oreval.- Init commands that call scripts outside the reviewed command path.
- Package lifecycle hooks during first install, especially in repos received through job posts, tutorials, direct messages, or unsolicited issues.
Fourth, use agent permission rules as policy, not as a vibe. Deny broad Bash where you can. Ask on python -m * init, npm install, pip install, and package-manager commands for untrusted workspaces. If that sounds too noisy, separate trusted and untrusted workspaces so your main product repo keeps a smoother profile while random repo exploration stays caged.
A practical Claude Code baseline for an untrusted repo session looks like this:
Start in a disposable container or VM.
Unset cloud and production tokens.
Block outbound DNS except through monitored resolver policy.
Run agent in plan or ask-heavy mode first.
Deny broad Bash network tools.
Require human review for package install and init commands.
Capture full command transcript and DNS logs.
Destroy the environment after review.The point is not to ban agents from setup. The point is to move first-run execution into a place where compromise is cheap.
What should you change in the next 48 hours?
You do not need a six-month agent security program to reduce this risk. You need a short policy that engineers can remember when they are trying to ship.
First, inventory where agents can execute commands today. Name the tools: Claude Code, Cursor, Copilot-style terminals, OpenCode, Windsurf, internal wrappers, and CI bots. For each one, answer 4 questions: can it run shell commands, can it reach the network, can it read secrets, and can it remember approvals?
Second, remove long-lived production credentials from developer shells used with agents. Use short-lived cloud credentials, scoped package tokens, and separate profiles. If your default terminal exports write-capable production keys, the agent does not need a vulnerability. It only needs a bad repo.
Third, create an untrusted-repo lane. It should have no production secrets, restricted network egress, full transcript logging, and a deletion button. Make this the default for repos from tutorials, job candidates, vendors, Discord links, Slack messages, and social posts. If a repo has not been pulled into your normal dependency review, it goes through the lane.
Fourth, update code review rules for setup scripts. A reviewer should flag runtime-fetched commands even when the source repo is clean. The sentence to add to your checklist is blunt: no setup step may execute data fetched at runtime unless the source, integrity, and purpose are reviewed.
Fifth, add detections that match the behavior, not the brand name. Alert on dig or nslookup for TXT records followed by shell execution. Alert on outbound connections from developer machines to unusual high ports during package setup. Alert when agent processes spawn shells that spawn network clients. These are old endpoint ideas wearing an AI hoodie.
Sixth, write a one-page agent permission standard. Include default modes, forbidden modes, approved allow rules, and escalation paths. If bypassPermissions or equivalent modes are allowed at all, require a container or VM. If someone wants a broad Bash allow rule, make them justify it like any other privileged access grant.
The open question is how much of this should live inside agent products versus your own platform. 0DIN argues agents should disclose the full execution chain, including scripts and code fetched dynamically at runtime. That is the right direction. It is also not enough for production operators. You still need OS-level sandboxing, egress controls, and credential scoping because the model's summary of a command is not a security boundary.
The clean repo era needs dirty skepticism
The useful lesson from 0DIN's demo is uncomfortable: cleanliness is no longer a property of the repository alone. It is a property of the repo, the network, the runtime, the agent's permissions, and the secrets sitting nearby.
AI coding agents are becoming build operators. Treat them like build operators. Give them least privilege, disposable workspaces, logged actions, and boring network paths. The repo can be clean. Your execution environment still needs to assume it is lying.