If you have used Matillion before, you probably picture the old ETL tool that ran on a VM you had to size, patch, and babysit. The Data Productivity Cloud (DPC) is the rebuilt, cloud-native successor, and it changes enough about how pipelines run and bill that it is worth a proper walkthrough. This guide is the starting point for our studio: what the platform actually is, how a pipeline executes, and where the money goes.
Matillion's pitch is that one platform should let three different kinds of people build the same pipeline: a low-code analyst dragging components in the Designer, an engineer writing dbt, SQL, or Python, and increasingly an AI agent under Matillion's Maia brand. The interesting question for a builder is not the marketing claim, it is the plumbing underneath: what runs where, what you pay for, and where the platform helps versus gets in the way.
What is the Data Productivity Cloud, concretely?
The DPC is a fully managed, browser-based environment for data integration. You do not run a Matillion instance anymore. Instead, Matillion hosts the control plane and you connect it to your cloud data warehouse, typically Snowflake, Databricks, Amazon Redshift, Google BigQuery, or Microsoft Fabric.
Two kinds of work happen in a DPC project:
- Ingestion pulls data from sources (databases, SaaS APIs, files) into your warehouse using prebuilt connectors and change data capture.
- Transformation reshapes that data once it lands, and this is the part that matters most for cost.
The key architectural fact is pushdown. When you build a transformation pipeline in the Designer, Matillion does not move rows through its own engine. It compiles your pipeline into SQL and pushes that SQL down to your warehouse, which does the heavy lifting. That single design choice explains most of the platform's cost behaviour, which we will come back to.
How does a pipeline actually run?
A DPC project separates two pipeline types on purpose, and mixing them up is the most common beginner mistake.
- Transformation pipelines run SQL against your warehouse. They have no orchestration logic; they just transform.
- Orchestration pipelines are the conductor. They run ingestion jobs, call transformation pipelines, branch on success or failure, loop with iterators, and handle scheduling.
A healthy project keeps a thin orchestration layer that calls many focused transformation pipelines, rather than one giant pipeline that tries to do everything. The same discipline you would apply to functions in code applies here: small, named, reusable units.
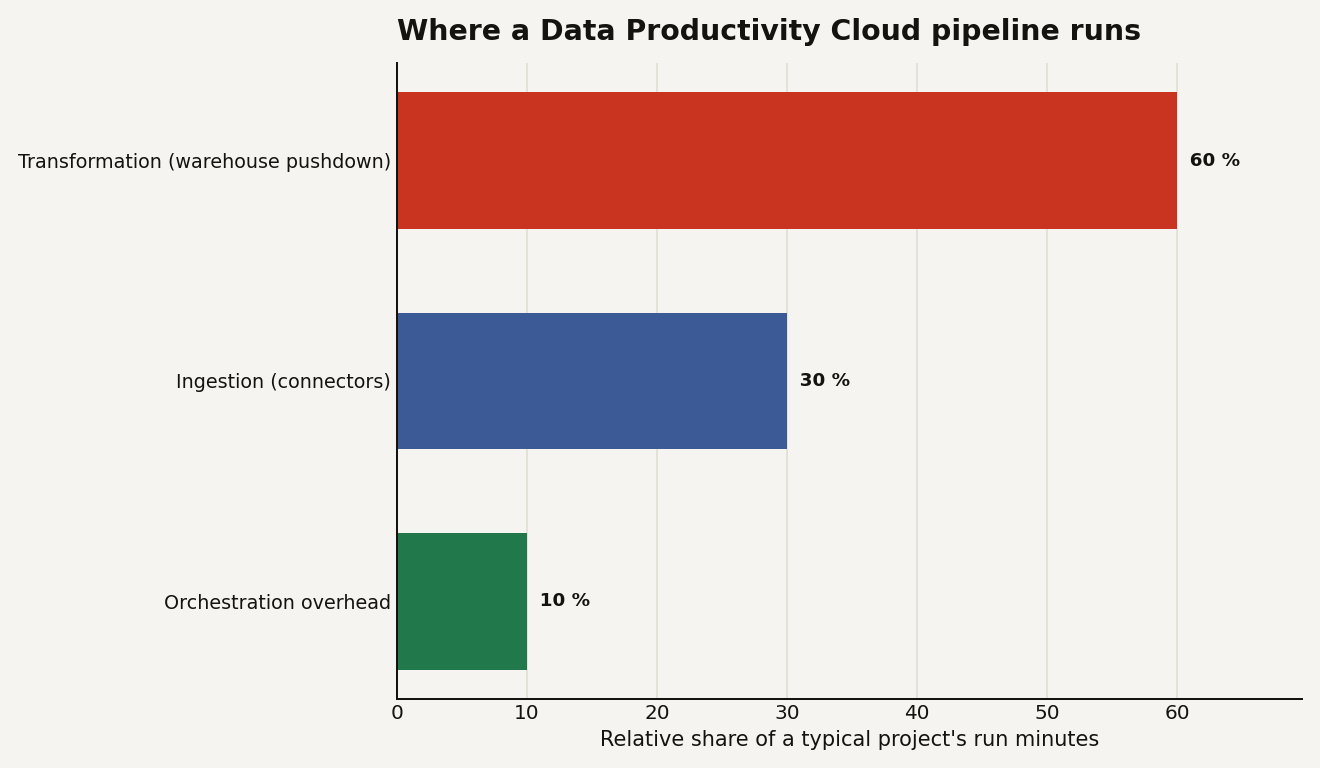
The chart below shows where the run minutes of a typical project go. The bulk of the time, roughly 60 percent, is transformation SQL executing inside your warehouse, around 30 percent is ingestion, and the remaining 10 percent is orchestration overhead. The exact mix varies, but the shape holds: your warehouse, not Matillion, is doing most of the work.
Where does the cost actually go?
This is the question that decides whether a DPC project stays affordable, and the answer has two halves that you pay separately.
| Cost layer | What you pay for | Who bills you |
|---|---|---|
| Matillion credits | Pipeline runs and platform usage, metered by Matillion | Matillion |
| Warehouse compute | The SQL pushdown that transformations execute | Your cloud warehouse |
| Ingestion | Rows or connectors moved, depending on plan | Matillion |
Because transformation runs as pushdown SQL, a badly written pipeline does not just burn Matillion credits, it runs an expensive query on your warehouse and shows up on a second bill. The most common cost surprise is a transformation that scans far more data than it needs, often because someone left a full reload where an incremental load belonged. Optimizing the SQL your pipeline generates is therefore a warehouse-cost exercise as much as a Matillion one, which is exactly why we treat cost as its own section.
What about the runners?
The DPC runs your pipelines on compute called runners. Matillion offers fully hosted runners so you do not manage infrastructure, and self-hosted or cloud-hosted runner options for teams that need pipelines to execute inside their own network, for example to reach a private database without exposing it to the internet.
The trade-off is the usual managed-versus-self-hosted one:
- Hosted runners are zero-maintenance and the fastest way to start, but they run in Matillion's environment.
- Self-hosted runners keep execution and credentials inside your perimeter, at the cost of you owning the compute and its upkeep.
If you handle regulated data or sit behind strict network controls, the runner choice is the first architectural decision to get right, well before you build a single pipeline.
Where does Maia, the AI layer, fit?
Maia is Matillion's name for the AI features layered across the DPC: copilots that help build and explain pipelines, agents that can take actions through API endpoints, and assistance for tasks like root cause analysis when a pipeline fails. The honest read is that this is the fastest-moving and least settled part of the platform, which is precisely why it deserves close, sceptical coverage rather than hype.
For a builder, the practical stance is to let AI accelerate the boring parts, generating boilerplate transformations, suggesting fixes, explaining an unfamiliar pipeline, while keeping a human reviewing anything that touches production data. We will track each Maia capability as it ships and judge whether it is genuinely production-ready or still a demo.
What should you do with this?
If you are evaluating or adopting the Data Productivity Cloud, a few principles travel well:
- Treat your warehouse as the engine. Most of your cost and performance lives in the pushdown SQL, not in Matillion. Profile the queries your pipelines generate.
- Keep orchestration thin and transformations small. Reusable, well-named pipelines age far better than monoliths.
- Decide runners early. Network and compliance constraints shape the whole project.
- Adopt Maia deliberately. Use it where review is cheap; gate it where mistakes are expensive.
This guide is the foundation. From here, the guides go deeper on each piece: ingestion connectors and change data capture, transformation patterns in the Designer, orchestration controls like iterators and scheduling, the FinOps habits that keep credits in check, and the Maia AI features as they land. The platform is moving quickly, and the goal here is the same as everywhere on Data Today: tell you what actually changed and what it means for the thing you are building.