The dangerous part of a logging stack is that everybody trusts it. Splunk often sits near privileged telemetry, sensitive logs, security workflows, and the operators who can see across the estate. The Splunk Enterprise flaw CVE-2026-20253 breaks that trust in the worst possible place: an unauthenticated PostgreSQL sidecar endpoint that can be reached by a network adjacent attacker and, in public research, chained into remote code execution.
If you run affected Splunk Enterprise 10.x, treat this as an active incident response item, not a routine patch ticket.
Splunk published SVD-2026-0603 on June 10, 2026, giving CVE-2026-20253 a CVSS 9.8 Critical score and identifying affected versions as Splunk Enterprise 10.2.0 to 10.2.3 and 10.0.0 to 10.0.6. On June 18, Splunk updated the same advisory to say its PSIRT had become aware of limited exploitation in June 2026. CISA then added the bug to its Known Exploited Vulnerabilities catalog and, according to BleepingComputer's report on the CISA order, gave federal civilian agencies until Sunday, June 21, 2026 to remediate.
That date matters for everyone outside government too. CISA deadlines are not magic, but they are a clean signal that the exploitability debate is over. Attackers are already using this class of bug. Your job is to remove the landing zone before your SIEM becomes the quietest compromise in the building.
What actually broke in Splunk Enterprise?
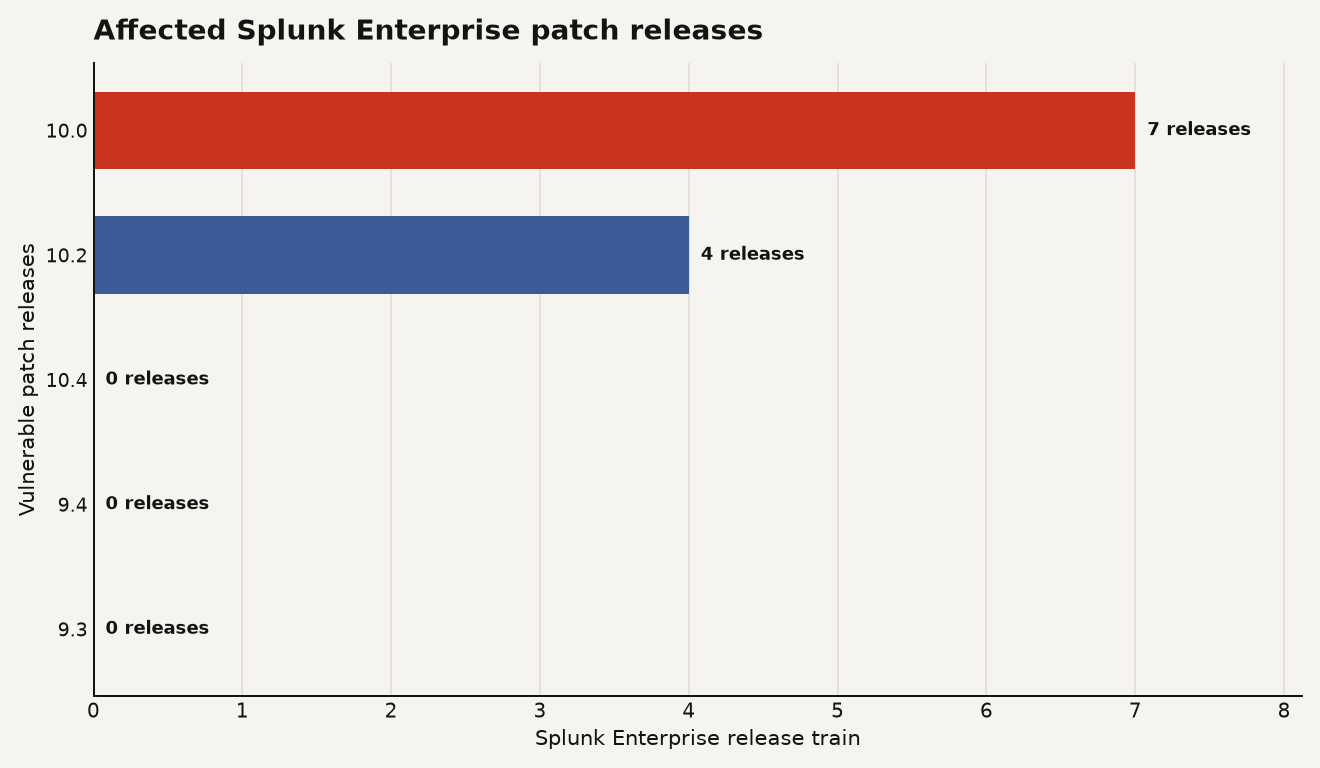
The flaw is simple enough to be uncomfortable. Splunk says the PostgreSQL sidecar service endpoint lacks authentication controls, which lets any network reachable user invoke file operations without credentials. The affected trains are narrow, but common enough to hurt: Splunk Enterprise 10.0.0 through 10.0.6 and 10.2.0 through 10.2.3. Splunk Enterprise 10.4.0, 10.2.4, and 10.0.7 are fixed, while Splunk Enterprise 9.4 and 9.3 are listed as unaffected in Splunk's product status table.
The chart below shows the operational shape of the exposure. The ugly number is 7 vulnerable 10.0 patch releases, because that is the kind of long tail that survives in production after a platform upgrade.
The initial vendor description says arbitrary file creation and truncation. That sounds like a file integrity problem until you remember where Splunk lives. A file primitive on a SIEM host can become credential theft, alert tampering, persistence, or code execution depending on placement, permissions, and app behavior.
That is exactly where public research went. watchTowr Labs published a technical writeup on June 12, 2026 showing how requests to Splunk Web could be proxied to the local PostgreSQL sidecar API through paths such as /en-US/splunkd/__raw/v1/postgres/recovery/backup. The researchers then walked the chain from arbitrary file operations to controlled file write and remote code execution as the Splunk user.
Do not overfit on one proof of concept. The operator takeaway is broader: a management or helper service that was expected to be internal became reachable through the product's own web surface. Once an attacker can make the logging system perform trusted local operations, your perimeter assumptions around that helper service stop helping.
Why is this worse because Splunk is the logging system?
A compromised Splunk box is a messy incident because it can blur the evidence trail while sitting inside your response workflow. That does not mean every exploit automatically deletes your logs or steals every secret. It means the host has a trust profile that most web apps do not have.
For a production team, the exposure splits into four practical risks:
- Control plane risk: Splunk often connects to forwarders, deployment servers, apps, alert actions, identity providers, and ticketing workflows.
- Data concentration risk: Logs may contain tokens, session identifiers, internal hostnames, request bodies, stack traces, and customer identifiers.
- Detection risk: An attacker on the SIEM can test whether your alerts fire, then change behavior or persistence accordingly.
- Recovery risk: If responders rely on Splunk during the investigation, a tainted instance can waste hours with partial or misleading evidence.
This is why the Sunday deadline is rational. CISA's June 21 date creates an 11 day window from Splunk's June 10 disclosure to required remediation for federal agencies. In a normal change calendar, 11 days feels tight. For a pre-authentication Critical bug with public technical detail and confirmed exploitation, 11 days is generous.
There is a business consequence hiding in the patch note. Splunk's workaround is to disable the PostgreSQL sidecar service, but Splunk warns that doing so breaks Edge Processor, OpAmp, and SPL2 data pipelines on affected instances. That makes this a real operations decision, not a checkbox. If those pipelines carry production telemetry, you need an owner who can say what drops, what degrades, and what gets replayed.
Security tools keep teaching the same lesson. Your SIEM, VPN, CI runner, MDM, and package registry deserve the same patch urgency as internet facing apps because attackers target the systems that operators exempt from normal suspicion. We made a similar point in our guide to building a Fortinet credential reset plan: fixing the appliance is only half the work when the appliance has been trusted for too long.
How should operators triage CVE-2026-20253 today?
Start with asset truth, not dashboard vibes. If your inventory cannot answer which Splunk Enterprise versions are running by environment, owner, exposure, and feature usage, this CVE is the audit you did not ask for.
Here is the fastest sane order of operations:
- Find every Splunk Enterprise 10.x instance. Include lab, DR, old migration hosts, cloud VMs, and contractor managed boxes.
- Classify versions. Instances on 10.0.0 to 10.0.6 or 10.2.0 to 10.2.3 are in the affected set.
- Patch first where reachable. Upgrade to 10.0.7, 10.2.4, 10.4.0, or later, based on your train and compatibility plan.
- If you cannot patch, disable the sidecar only after dependency review. Splunk's mitigation requires adding a
[postgres]stanza withdisabled = truein$SPLUNK_HOME/etc/system/local/server.conf, then restarting Splunk Enterprise. - Hunt before you declare victory. Check for unexpected access to PostgreSQL recovery endpoints, suspicious backup or restore activity, new or modified files under Splunk app paths, and unusual outbound connections from Splunk hosts.
The dependency review should be quick and explicit. Ask three owners three questions: does this instance run Edge Processor, does it use OpAmp, and does any SPL2 data pipeline depend on this box? If all three answers are no, disabling the PostgreSQL sidecar is a reasonable temporary brake while the patch moves. If any answer is yes, the workaround could cut telemetry you need during the incident window.
Network controls still help, but they should not become the whole response. Restrict Splunk Web and management surfaces to administrative networks, remove accidental internet exposure, and block unneeded east west access. Then patch anyway. The exploit path described by watchTowr depends on network reachability, and compromised internal workstations count as network reachability in real incidents.
What should you check for after patching?
Patching closes the known door. It does not prove nobody walked through it between June 10 and your maintenance window.
Your post patch review should cover three buckets. First, review Splunk application directories for recent modifications, especially scripts under app bin directories and any file changes owned by the Splunk service account. Second, inspect Splunk web and internal logs for access to /v1/postgres/recovery/backup, /v1/postgres/recovery/restore, and proxied splunkd/__raw paths. Third, look at host telemetry for unusual child processes, outbound connections, and file writes from Splunk processes around the disclosure window.
If you find a vulnerable instance that was internet exposed, raise the bar. Pull a forensic image or at least preserve logs before restarting services repeatedly. Rotate credentials that lived in Splunk configs, alert actions, custom apps, scripted inputs, and integrations. Review tokens and webhooks that Splunk could invoke. A SIEM compromise can become a SaaS compromise if alerting integrations carry powerful credentials.
Also check whether your backup strategy includes clean Splunk configuration state. Restoring tainted apps or scripts into a freshly patched instance is a classic way to keep the attacker on payroll. The boring recovery question is useful: can you rebuild Splunk from known good configuration, or are you only backing up the same mutable host that might be compromised?
What changes after this patch window closes?
The useful work after Sunday is architectural. Do not let a CVE like this disappear into the patch report.
Give Splunk and similar platforms a stricter operating model:
- Put SIEM admin surfaces behind an access path that logs identity, device posture, and source network.
- Treat helper services and sidecars as attack surface even when they bind to localhost.
- Monitor the monitoring stack with independent telemetry, such as EDR and host based file integrity rules.
- Keep service account permissions boring, narrow, and documented.
- Practice a rebuild of at least one non production Splunk node from source controlled configuration.
The sidecar detail is the part builders should remember. Modern platforms keep adding helper processes, embedded databases, local APIs, and background workers. Each one is a contract that says, in effect, the main app will never expose me in a dangerous way. CVE-2026-20253 shows how brittle that contract can be.
If you own production systems, your immediate bet is simple: patch or disable the PostgreSQL sidecar before attackers make the decision for you. Your longer bet is stricter segmentation around the tools you use to see everything else. Observability without containment is just a better map for the person who gets in.
The logging box is part of the blast radius
Security teams like to call Splunk a source of truth. During exploitation, it is another Linux or Windows host with privileged relationships and a large memory of your environment.
Give it the respect you give a domain controller. Then give it the patch window you give an actively exploited edge device.